spark作为一个内存mapreduce框架,速度是hadoop的10倍甚至100倍。windows下可以通过简单设置,搭建本地运行环境。
1、下载spark预编译版本,spark运行环境依赖jdk,scala,这里下载的最新spark版本是2.3,对应jdk1.8+scala2.11.8。
java -version
java version "1.8.0_151"
Java(TM) SE Runtime Environment (build 1.8.0_151-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.151-b12, mixed mode)
scala -version
Scala code runner version 2.11.7 -- Copyright 2002-2013, LAMP/EPFL
2、下载hadoop-common-2.2工具包,并设置环境变量HADOOP_HOME,PATH。
如果不下载hadoop-common-2.2并设置环境变量,启动spark-shell时,会报如下错误:
ERROR Shell:397 - Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binar
ies.
hadoop-common包下有bin目录,bin目录中的内容如下:
3、standalone方式启动spark:进入spark-2.3.0-bin-hadoop2.7目录,按住shift,鼠标右键->在此处打开命令窗口。运行bin\spark-shell
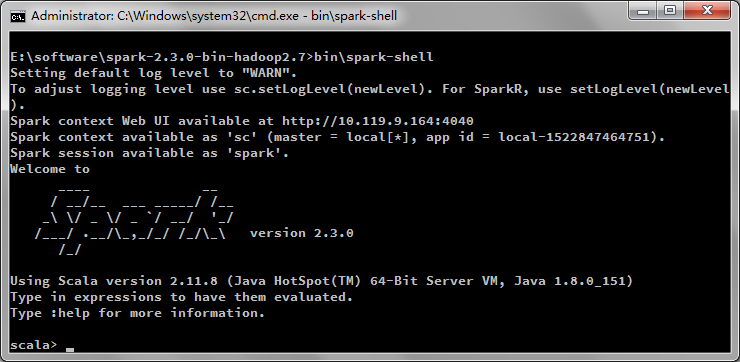
启动成功,会进入scala命令行交互界面,然后就可以进行编码了。
scala> val textFile = sc.textFile("helloSpark.txt");
textFile: org.apache.spark.rdd.RDD[String] = helloSpark.txt MapPartitionsRDD[1] at textFil
e at <console>:24
scala> textFile.foreach(println)
sparkui
hello,java
spark
hello,scala
hello,spark
scala> val counts = textFile.flatMap(line=>line.split(",")).map(x=>(x,1)).reduceByKey((x,y
)=>(x+y))
counts: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[10] at reduceByKey at <conso
le>:25
scala> counts.foreach(println)
(spark,2)
(sparkui,1)
(scala,1)
(hello,3)
(java,1)
scala>
这里运行一个最简单的wordcount程序,先导入一个文档,文档五行内容,然后运行flatMap(),将文档内容每一行按照逗号分割,然后运行map(),reduceByKey()。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)