虽然应该尽量避免使用笛卡尔积,因为要全量匹配,所以运算的效率十分低下,但是有些业务有必须得用,所以在此了解下SparkSQL中的笛卡尔积。
SparkSQL中计算笛卡尔积时有两种Join方式:Cartesian Join 和 Broadcast Nested Loop Join。其中 Broadcast Nested Loop Join 是默认的 Join 机制,它可以用来进行任意条件任意类型的 Join。
Cartesian Join:
该种方式的执行其实就是RDD操作中的cartesian。最终partition的数量是两个RDD partition数量的乘积。它是遍历partition进行计算的,所以会产生巨量多的Task:

SparkSQL对此进行了优化,对右边的数据进行了cache,以便加快计算速度,计算的原理是一致的:

cache就是标红的地方,把数据放到rowArray结构中: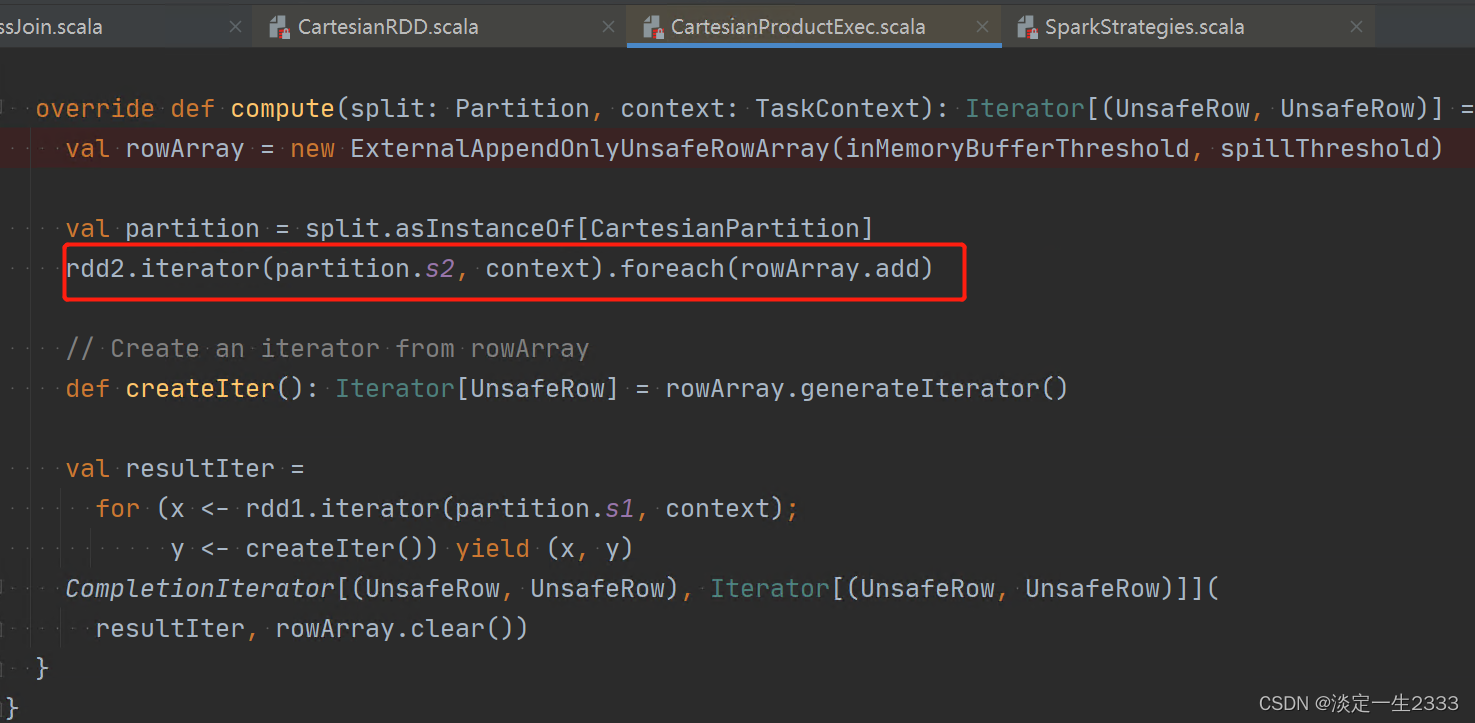
Broadcast Nested Loop Join:
选择BNLJ时,优先通过hints判断到底要广播哪一侧的表。如果没有hints的时候,再通过大小比较,广播小一侧的表:

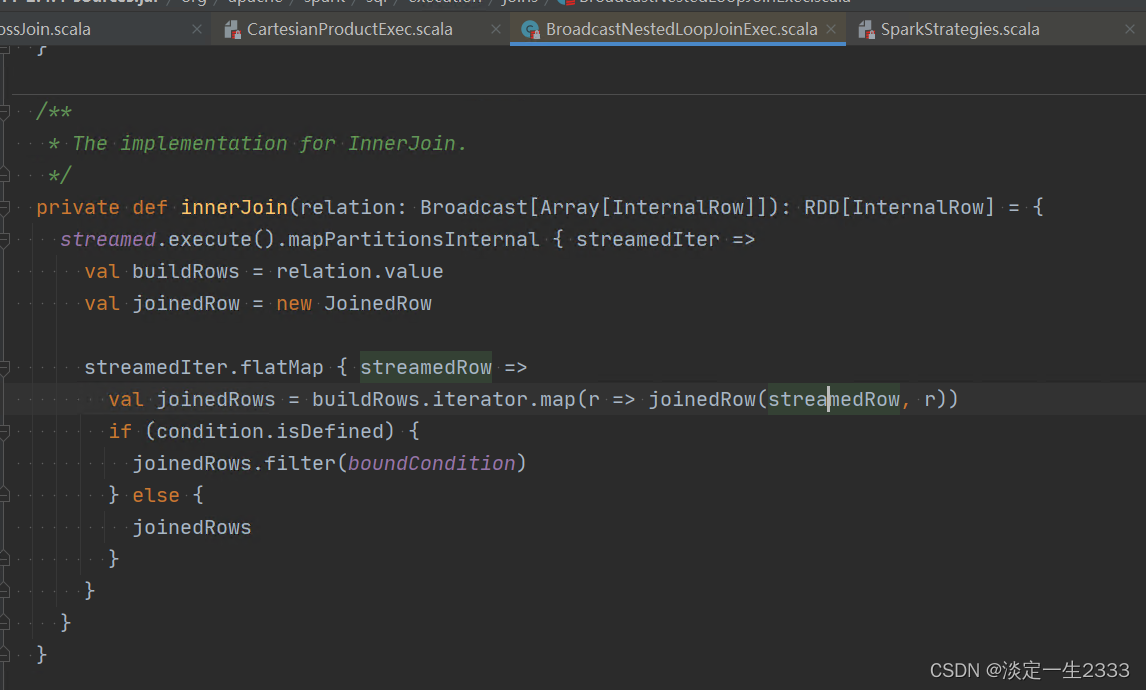
Join的流程很简单,以Inner Join为例,就是逐条匹配,然后按条件过滤。可以理解为Join的流程就是双重的for循环:
for(x in ***){
for(y in ***){
x match y
}
}
参考:
spark2.4 `Inner join`被“优化”成`CartesianProduct`
Spark Catalyst 进阶:Join - Robert Peng's Blog
https://www.jianshu.com/p/fb8b792a7a9b
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)