最近浏览Flink文章的时候发现一个现象,就是在操作State的时候,很多文章里面并不会直接操作State,而是会定义一个相似的变量去操作,在 snapshot 和 recover 的时候讲变量中的内容写入到State或者从State中恢复,为啥要这么使用呢?本文探究StateBa
RocksDB介绍:
本文探究以RocksDBStateBackend为例进行说明,因为它的数据都是存放在磁盘上的,所以它能存放超大State,生产环境上一般用的也是它。虽然StateBackend还有MemoryStateBackend和FsStateBackend,但是它们都基于JVM堆,即运行中状态存储在JVM堆中,不能存放太大的State。而且MemoryStateBackend一般都用于测试环境,生产环境上没人会用这个。FsStateBackend个人感觉是可以直接操作State的,这个后续看完整篇文章就会明白了。
RocksDB 是一个非常优秀的 Key-Value 存储,经过了 Facebook 多年的迭代和优化。它通过Java本机接口(JNI)与Flink进行交互。如下所示:

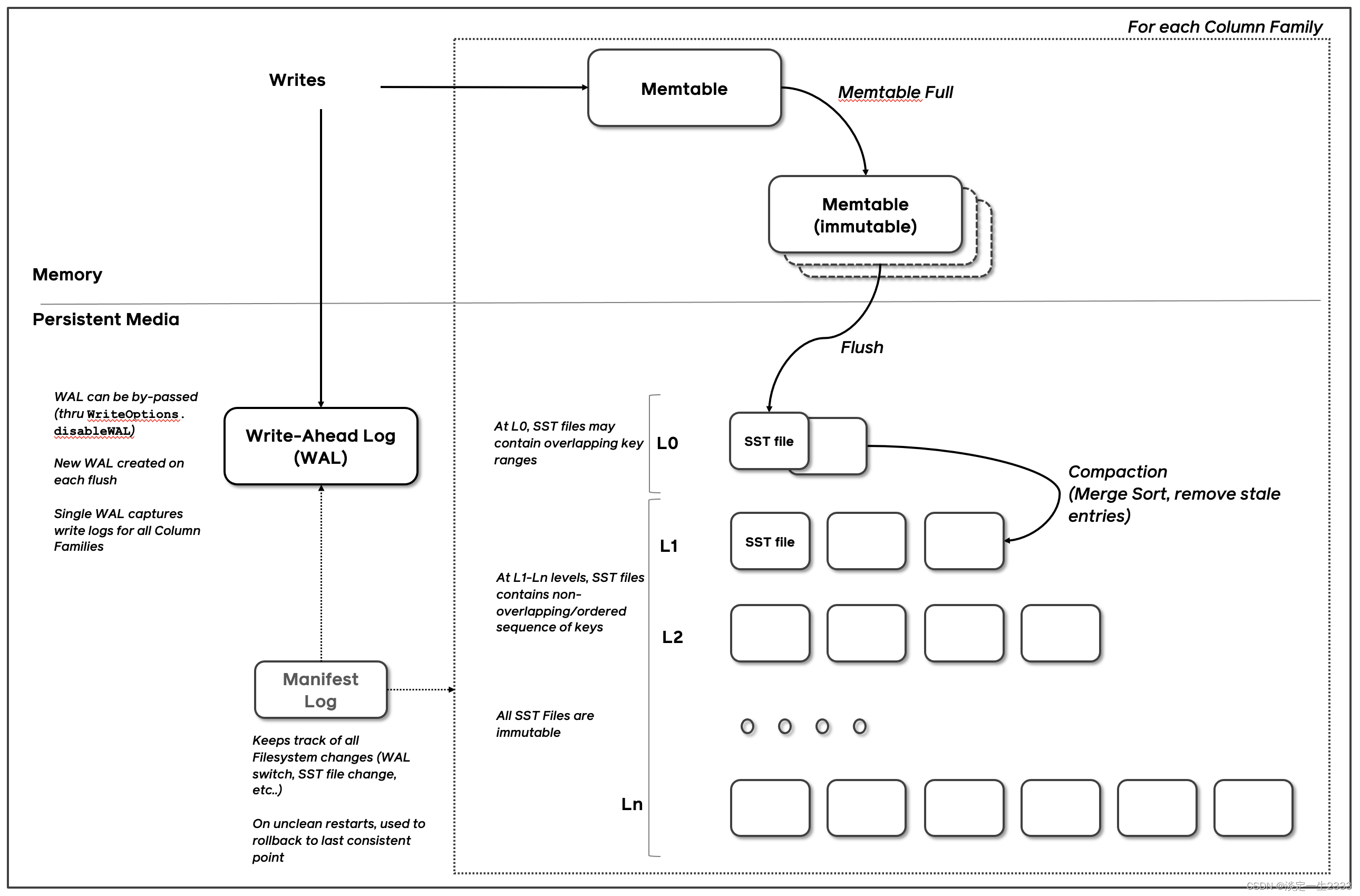
可以按照HBase的概念去理解RockDB。RockDB写入是也是先写入Memtable(类似HBase MemStore),达到一定大小的时候再Flush到磁盘上形成一个SST文件(来源于Google的Big Table)。如果开启了WAL的话数据会同步写入到WAL中。读取的时候,会从Memtable、Block Cache、SST 文件。然后数据会进行文件的Compaction操作,此操作同时会删除和更新数据。
不过和HBase不同的是,RocksDB文件存储组织成了多个层级,不同层级之间会通过异步 Compaction 合并重复、过期和已删除的数据。:
所以,为什么额外要再自己定义一个变量来操作State呢?
本质的原因还是磁盘IO问题,RockDB写数据时候的Flush操作和Compaction会消耗IO的。如果在内存中额外定义一个变量,只在Checkpoint和Recover的时候才去操作State,就免去了磁盘IO问题!
当然,如果State非常大的话,那还是得直接去操作State,不然TM内存也放不下不是,大部分State不大场景下,个人理解最好都是额外定义一个变脸来操作State。
和大佬交流之后发现自身理解有误,State只有在snapshot的时候才会真正的落盘。
新进来的数据写入到了State中,但是都是在内存里,没有落到磁盘上。 例如看windowState就可以大概了解,数据写入了State如果是立即落盘,那么数据就会重复消费,无法保证Exactly_Once语义了。
现在个人看法是,尽量直接操作State。如果有特殊自定义的TTL逻辑,可以考虑额外定义一个变量来操作State。
参考:
字节跳动使用 Flink State 的经验分享-51CTO.COM
Apache Flink: Using RocksDB State Backend in Apache Flink: When and How
Pebble/RocksDB SST 文件详解_Caption 嘟嘟嘟的博客-CSDN博客_sst文件
Why not RocksDB in Streaming State? | 廖嘉逸's Blog
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)