题意
咕咕东 正在上可怕的复变函数,但对于稳拿A Plus的 咕咕东 来说,她早已不再听课,此时她在睡梦中
突然想到了一个奇怪的无限序列:112123123412345 …这个序列由连续正整数组成的若干部分构成,其
中第一部分包含1至1之间的所有数字,第二部分包含1至2之间的所有数字,第三部分包含1至3之间的所
有数字,第i部分总是包含1至i之间的所有数字。所以,这个序列的前56项会是11212312341234512345612345671234567812345678912345678910,其中第1项是1,第3项是2,第20项是
5,第38项是2,第56项是0。咕咕东 现在想知道第 k 项数字是多少!但是她睡醒之后发现老师讲的东西
已经听不懂了,因此她把这个任务交给了你。
Input

Output

输入样例
5
1
3
20
38
56
输出样例
1
2
5
2
0
提示


分析
这道题也不算很难,但是需要找到规律,这个过程可能会消耗一定时间,而且用代码实现规律的过程也不是很容易。现在还不太能做到在规定时间内做完第三题。
- 初步分析
根据题意可知:
不考虑题目要求,仅观察这个序列,它的初步特征非常明显,就是将所有递增的小序列合并为一个大序列。
(1)(1 2)(1 2 3)…
其中,
第一个小序列为:1
第二个小序列为:1 2
第三个小序列为:1 2 3
而这三个序列在整个大序列中出现的次序分别为第1个、第2个、第3个。
由此推演不难发现:每个小序列都是从1开始,公差为1,项数等于小序列在大序列中出现的次序。而每个小序列中的数字个数同样也是等差的。
所以初步分析可得:题目所给序列满足每个小序列中的数为等差序列、每个小序列中的数字个数之间也为等差序列。
- 进一步分析小序列
但是,题目提到,在这个序列中每一项的序号并不是以数为单位,而是以单个数字为单位。
也就是说当出现多位数时,不是以一个数为单位,而是以一个单独的数字(0~9)为单位,所以这个数实际看作为它所包含的数字个数个。
例如,54 在这个序列中不算作出现的一项,而是以5和4视作出现了两项。
因此在这种方式下,我们自然要计算一下如何根据初步总结的数列特征来统计序列中实际包含的数字项数:
假设其中一个小序列,包含了1~无限大。显然无限大包含了从位数为1到无限大的数。
将相同位数的数放在同一个区间,我们可以发现:
1~9 共包含 9 * 1 项数字
10~99 共包含 90 * 2 项数字
100~999 共包含 900 * 3 项数字
...
综上可以得到规律:
一个递增序列中,位数为a的区间里共包含 9 * 10^(a-1) * a 项数字
因此,前a位数区间里包含的数字项数就等于从位数1项数累加到位数为a 的区间。
- 进一步分析大序列
通过分析小序列中的位数区间,自然也会联想到大序列中的位数区间。
大序列的位数区间指的是在该区间内所有小序列的项数都为同样的位数,也可以理解为该区间内所有小序列中的最大数都为同样位数。
那么我们又该如何计算大序列中各区间的数字项数呢?
最开始会觉得这很麻烦,因为我们很难估计那么多小序列组成的区间。但是通过1、2点分析,可以发现这其中不无规律:
每个小序列中都会比前一个序列多一个数,且多出来的这个数——即当前小序列中的最大数——都比其前一个小序列的大1。那么在最开始就会自然想到每一个小序列的数字项数也比前一个小序列大1。
但实际上并不是,仔细一想会发现,这要取决于当前小序列比前一个序列多出来的这个数的位数。
考虑序列中的一段:
...(1 2 3 4 5 6 7 8 9)(1 2 3 4 5 6 7 8 9 10)...
第一个序列包含 9 项数字
第二个序列包含 11项数字
...(1 2 3 4 5 6 7 8 9 10)(1 2 3 4 5 6 7 8 9 10 11)...
第一个序列包含 11 项数字
第二个序列包含 13 项数字
...(1 2...98 99)(1 2 ... 99 100)...
第一个序列包含 9 + 90 * 2 = 189 项数字
第二个序列包含189 + 3 = 192项数字
...
从上述例子中能感受到,当小序列中最大数的位数发生变化时,小序列包含数字项数所构成的等差序列的公差也会发生改变:
大序列的1位数区间(即区间中所有小序列的最大数都为1位数)
每个小序列所含数字项数构成的序列:
1 2 3 4 ... 公差为1
大序列的2位数区间(即区间中所有小序列的最大数都为2位数)
每个小序列所含数字项数构成的序列:
11 13 15 17 ... 公差为2
大序列的3位数区间(即区间中所有小序列的最大数都为3位数)
每个小序列所含数字项数构成的序列:
192 195 198 201 ... 公差为3
...
显然每个位数区间都是从最大数为当前位数的最小数的小序列所包含的数字项数开始的,即为等差数列的首项。
大序列的1位数区间
第一个小序列为:1
数字项数 = 1
大序列的2位数区间
第一个小序列为:1 2 3 4 5 6 7 8 9 10
数字项数 = 9 + 2 = 11
大序列的3位数区间
第一个小序列为:1 2 ....98 99 100
数字项数 = 9 + 90 * 2 + 3 = 192
...
即,位数为a区间的首项等于小序列中前a-1个位数区间的数字项数和+a。
综上,可得规律:
大序列中位数为a的区间中,所有小序列所包含的数字项数构成公差为a的等差数列。每个大序列位数a区间中的等差序列的首项等于小序列中前a-1个位数区间的数字项数和 + a。
将序列特征分析结束后,解题思路大致也可以想到。
如果我们能找到给定的项数包含在哪一个数内部,就很容易确定是这个数中的哪一个数字了。
但是大序列中有许多重复出现的数,所以我们得找到这个数具体是在哪一个小序列中。而每一个小序列中的一部分总会重复出现,所以又要进一步确定这个小序列到底是在大序列中的哪一段。
因此,根据反向思维整理可得:
已知目标数字x在大序列中的项数为m:
根据以上步骤,从上至下逐步锁定m指向的数字x的位置。
1. 确定x在大序列中位数为a的区间
显然,项数为m的数字x被包含在大序列中第一个项数总数大于m的位数区间内。
为了优化搜索时间,我们可以用一个数组记录大序列中每一个位数区间的数字项数总数,方便比较。
2. 确定x在大序列位数a区间中的b小序列中
当确定了x在大序列中位数为a区间后,我们也就知道了这个区间中开头到任意一个小序列末尾包含的数字项数。
根据等差公式可以快速计算出最大项为n的小序列到区间起始所包含的数字项数总和。
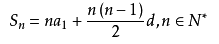
n = 小序列最大项
a1 = 最大序列位数a区间第一个小序列的数字项数
d = 位数a
但项数m是指的x在整个大序列中的位置,此处我们需要知道x在这个位数区间中的位置。用m减去位数a区间之前的所有项数即可得到。
因此,
x在位数a区间中的项数m2 = m - 前a-1位数区间项数和
同样,第一个项数大于m2的小序列包含数字x,该小序列的最大项为b。
3. 确定x在小序列的位数c区间中
同理,用m2减去位数a区间内小序列b之前的项数得到数字x在这个小序列中的项数m3。
因此,
x在小序列中的项数m3 = m2 - 位数a区间内小序列b前的项数和
再根据小序列的各位数区间项数和来判定其属于小序列中的哪一个位数区间。
因为在实现过程中会多次用到小序列各位数区间的项数,为了减少计算时间,我用了一个数组存储小序列中所有位数区间的项数和。
同上,得到包含x的最小位数区间c。
4. 确定x来自于数y中以及其位数
当知道了x属于小序列中的位数c区间后,由于小序列是以1递增的整数序列,所以只要知道x在这个位数c区间内的位置,就能知道其所在数。
同理,
x在小序列位数区间c中项数m4 = m3 - 小序列前c-1位数区间项数和
此时范围已经缩减很小,只要稍作举例就能发现特征。
2位数区间:10 11 12 13..
1)每个2位数的个位的项数都可以整除位数2
如10的0为第2位、11的1为第4位、12的2为第6位...
2)十位数的项数除以位数2的余数都为1
3位数区间:100 101 102 103..
1)每个3位数的个位的项数都可以整除位数3
2)十位数的项数除以位数3的余数都为2
3)百位数的项数除以位数3的余数都为1
...
根据举例证明,可以发现:
不过由于是从第1个开始算起,数y= 位数c的最小数+ 序号 - 1。
当一出现在有序序列中进行查询时,就应该自然想到二分查找。因此在寻找大序列的位数区间,以及大序列位数区间中的小序列时,我都运用了二分。
二分法👉[week4]四个数列——二分法(巧用)
这道题所给的数据范围很大,但是根据高斯数列,假设以所有数为单位计算项数时,当小序列中最大数为1e9时,所得项数已经接近最大数据了,因此显然在以数字为单位计算项数时,最大数为1e9已经满足题目数据范围。
不过需要注意的是,由于大序列的位数为9区间的项数非常大,如果不进行约束在vj上测试就会发生错误。所以只需要将大序列起始到这个区间末尾的项数和设置为题目所给最大数据即可。
我最开始写的方法是将小序列中每个位数区间中的数字从第0个开始计算,以此再来求商和余,得到数y及x所在位数。
但是这样的方法从第6个点开始就会WA。但目前我还不清楚错在哪里😰但是它真的让我调试了太久,一直没想到是这里的问题。
最开始的思路并没有将确定x的位置细分到那么多层,而是直接通过在小序列项数和来一步确定x在哪一个小序列中。
若当前数组存储的最大项数和小于x的项数m,则从当前存储的最后一个小序列开始向后计算,直到找到第一个包含x的小序列。
反之,则在数组中二分查找第一个包含x的小序列。
之后的操作都和上面相同。
但是这个做法只能过前3个点,后来被逼疯了直接重写,但是我想这个方法本身应该也没有问题,可能是因为确定x来自的数y以及x在其中的位数这一部分,在最初写的这个方法里我仍然用的是从0开始计位。
这个问题在此类设计数据比较多的规律型问题时就比较敏感。在各种计算和推演中,从0和从1开始将会是完全不同的方法。
总结
- 一个小步骤调试了两天👍差点在电脑面前暴走
代码
#include <iostream>
using namespace std;
long long digit[10],digit2[10];
long long powing(long long m,long long k)
{
long long ans = m;
if( k != 0 )
{
for( long long i = 0 ; i < k ; i++ )
ans *= 10;
}
else
return m;
return ans;
}
int find1(long long n)
{
int left = 0,right = 10,dig = 0;
while( left <= right )
{
int mid = (left + right) >> 1;
if( digit[mid] > n )
{
dig = mid;
right = mid - 1;
}
else if( digit[mid] < n )
left = mid + 1;
else
return mid;
}
return dig;
}
long long find2(long long num,long long dig)
{
long long sum = 0,min = 0,start = 0,res = 0;
start = powing(1, dig - 1);
min = digit2[dig - 1] + dig;
long long left = powing(1,dig - 1),right = powing(1, dig) - 1;
while( left <= right )
{
long long mid = (left + right) >> 1;
sum = (mid - start + 1) * min + (mid - start + 1) * (mid - start) / 2 * dig;
if( sum > num )
{
res = mid;
right = mid - 1;
}
else if( sum < num )
left = mid + 1;
else
return mid;
}
return res;
}
int main()
{
int q = 0;
long long n = 0,max = 0,min = 0,num = 0,loc = 0,start = 0,site = 0,origin = 0,dig = 0;
cin>>q;
digit[0] = 0;
digit2[0] = 0;
for( long long i = 1 ; i <= 9 ; i++ )
{
digit2[i] = digit2[i - 1] + i * powing(9,i - 1);
digit[i] = digit[i - 1] + powing(9, i - 1) * (digit2[i - 1] + i) + powing(9, i - 1) * (powing(9, i - 1) - 1) / 2 * i;
}
digit[9] = 1e18;
while ( q-- )
{
cin>>n;
dig = find1(n);
num = n - digit[dig - 1];
max = find2(num, dig);
start = powing(1, dig - 1);
min = digit2[dig - 1] + dig;
loc = num - ((max - start) * min + (max - start) * (max - start - 1) / 2 * dig);
if( loc < 10 )
cout<<loc<<endl;
else
{
long long j = 0;
for( j = 1 ; j <= dig ; j++ )
{
if( digit2[j] > loc )
{
site = loc - digit2[j - 1];
break;
}
}
long long k1 = site / j;
long long k2 = site % j;
if( k2 == 0 )
{
origin = powing(1, j - 1) + k1 - 1;
cout<<origin % 10<<endl;
}
else
{
origin = powing(1, j - 1) + k1;
long long k3 = j - k2;
origin = origin / powing(1, k3);
cout<<origin % 10<<endl;
}
}
}
}
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)