报错:
torch.tensor(images).cuda(async=True)
SyntaxError: invalid syntax

解决方法:
image_var = torch.tensor(images).cuda(non_blocking=True)
label = torch.tensor(target).cuda(non_blocking=True)
模型下载比较慢,可以提前下载:
http://data.lip6.fr/cadene/pretrainedmodels/inceptionv4-8e4777a0.pth
放到C:\Users\用户名\\.cache\torch\hub\checkpoints 下
报错: UserWarning: This DataLoader will create 12 worker processes in total. Our suggested max number of worker in current system is 8 (cpusetis not taken into account), which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
意思是线程设置太多,需要减少
设置如下
workers = 8
可是又会报错
AttributeError: Can’t pickle local object ‘main..TrainDataset’
所以我们修改为:
workers = 0
接下来报错:
CUDA out of memory. Tried to allocate 72.00 MiB (GPU 0; 4.00 GiB total capacity; 2.75 GiB already allocated; 9.74 MiB free; 2.77 GiB reserved in total by PyTorch)
先修改:
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
因为我们确实只有一块GPU,并且显存确实爆了
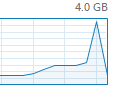
所以我们需要修改:
batch_size = 6
可以看到几乎拉满了

训练开始,然后报错:

line 2111, in _verify_batch_size raise ValueError(“Expected more than 1 value per channel when training, got input size {}”.format(size))
ValueError: Expected more than 1 value per channel when training, got input size torch.Size([1, 1536])
查看记录得知,代码这一句报错,原因是train_loader最后一张无法训练
train(train_loader, model, criterion, optimizer, epoch)
所以我们设置train_loader,加上参数:
drop_last=True
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True, pin_memory=True, num_workers=workers, drop_last=True)
最后我们就能训练出结果了:

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)