Numpy与Pandas是进行数据分析最常用的包。其中,Numpy(Numerical Python)是用来处理矩阵运算的,其运算效率高于列表;Pandas则是基于Numpy的数据分析工具,其能更方便地操作大型数据集,功能比Numpy更强大。
一、Numpy
由于Numpy包是第三方工具,因此每次使用前必须在代码中导入,其格式如下。其中,np为Numpy包约定俗成的简写,以便在后续程序中引用。
Numpy中用array函数可创建一维或多维数组(矩阵),与列表类似,其索引从0开始,可用切片的方式来访问数组(矩阵)中的数值。
值得注意的是:array内部的元素必须为相同的类型。


除上述基础操作外,Numpy还有实现数据的统计与向量加减等功能。但总体而言,Numpy可视作列表功能的扩展与延伸,其比列表更高效。后面将重点介绍作为主要数据分析工具的Pandas。
二、Pandas
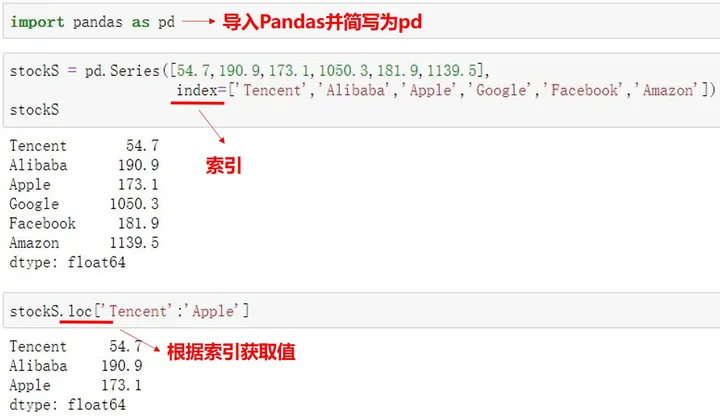
Pandas有两个主要的数据结构:Series和DataFrame(须区分大小写)。
Series用于创建一维数组,由一组数据和数据索引组成。数据索引是Pandas区别于Numpy的重要特征。不同于Array或列表,Series的索引不一定从0开始,它可以被定义,在Series创建的一位数组可通过定义的索引来获取值。
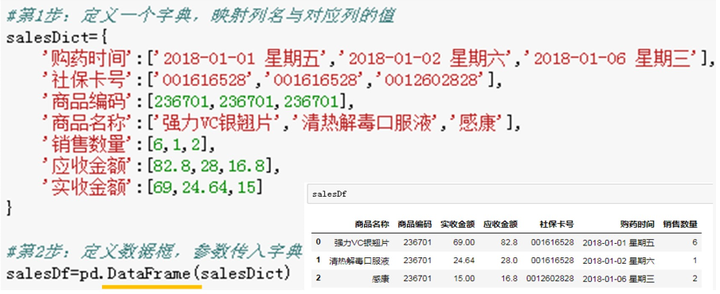
DataFrame是一个表格型的数据结构,它含有不同的列,每列都可以是不同的数据类型。类似一张excel表格或者SQL,其功能更强大。
定义DataFrame最常用的方法是导入一个字典。其中,DataFrame将字典的key作为列索引,可自行定义,而行索引则是从0开始定义。
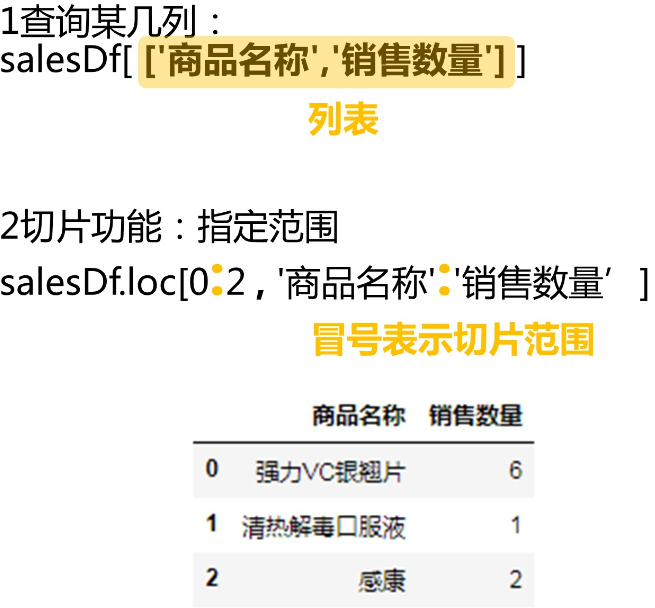
通过行列索引即可获取DataFrame中的各数值。
三、用Pandas进行数据分析
除了导入字典以外,还可通过直接读取Excel文件来定义DataFrame。

在读取了待分析的数据表格后,就可对其进行数据分析。但在数据分析之前还有一个很重要的步骤:数据清洗。即:把读取到的原始数据,通过截取、重命名、类型转换、排序以及缺失/异常值处理等操作,转化为适合进行分析的干净、准确的数据形式。

现结合一个医院销售数据分析的具体项目,通过如下代码展现数据清洗的基本操作。
import pandas as pd
#导入Pandas,并简写为pd
'''数据清洗'''
#读取原始数据表格
fileNameStr = 'C:\houzi\医院销售数据.xlsx'
salesDf = pd.read_excel(fileNameStr,sheet_name='Sheet1',dtype=str)
#将表格中的“购药时间”重命名为“销售时间”
colNameDict = {'购药时间':'销售时间'}
salesDf.rename(columns=colNameDict,inplace=True)
#删除表格中销售时间或社保卡号缺失的行
salesDf = salesDf.dropna(subset=['销售时间','社保卡号'],how='any')
#将表格中的销售与金额数据转换为浮点数
salesDf['销售数量'] = salesDf['销售数量'].astype('float')
salesDf['应收金额'] = salesDf['应收金额'].astype('float')
salesDf['实收金额'] = salesDf['实收金额'].astype('float')
#定义函数处理“销售时间”中的日期
def splitSaletime(timeColSer):
timeList=[]
for value in timeColSer:
dateStr=value.split(' ')[0]
timeList.append(dateStr)
timeSer=pd.Series(timeList)
return timeSer
timeSer = salesDf.loc[:,'销售时间']
dateSer = splitSaletime(timeSer)
salesDf.loc[:,'销售时间'] = dateSer.values
#转换日期格式
salesDf.loc[:,'销售时间']=pd.to_datetime(salesDf.loc[:,'销售时间'],
format='%Y-%m-%d',
errors='coerce')
salesDf = salesDf.dropna(subset=['销售时间','社保卡号'],how='any')
#按销售日期进行升序排列,并重命名行名
salesDf = salesDf.sort_values(by='销售时间',ascending=True)
salesDf = salesDf.reset_index(drop=True)
#删除表格中销售数量异常值
querySer = salesDf.loc[:,'销售数量']>0
salesDf = salesDf.loc[querySer,:]
#打印清洗后的数据表格前6行
salesDf.head(6)
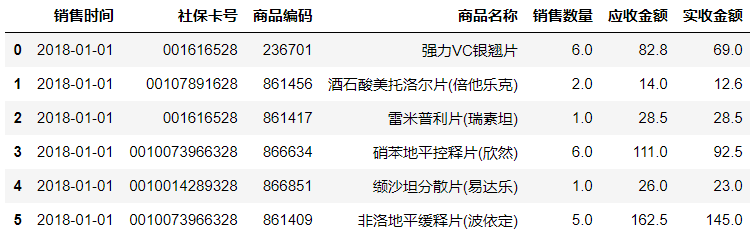
原始表格经过清洗后即得到了干净、准确、可读性强且易于分析的数据。对该数据作运算分析就能得到我们想要的信息了,比如月均消费次数、月均消费金额等。
'''数据分析或构建模型'''
#计算消费次数(同一天内、同一人发生的所有消费算作一次消费)
kpi1_Df = salesDf.drop_duplicates(subset=['销售时间','社保卡号'])#删除“销售时间”与“社保卡号”重复的行
totalI = kpi1_Df.shape[0]
print('总消费次数=',totalI)
#计算总消费金额
totalMoney = salesDf.loc[:,'实收金额'].sum()
#计算消费月份数
startTime = kpi1_Df.loc[0,'销售时间']
endTime = kpi1_Df.loc[totalI-1,'销售时间']
daysI=(endTime-startTime).days
monthsI=daysI//30
print('月份数:',monthsI)
#计算月均消费次数
kpi1_I = totalI // monthsI
print('月均消费次数=',kpi1_I)
#计算月均消费金额
monthMoney = totalMoney / monthsI
print('月均消费金额=',monthMoney)
#计算客单价
pct = totalMoney / totalI
print('客单价:',pct)
