cuda小白
原始API链接 NPP
GPU架构近些年也有不少的变化,具体的可以参考别的博主的介绍,都比较详细。还有一些cuda中的专有名词的含义,可以参考《详解CUDA的Context、Stream、Warp、SM、SP、Kernel、Block、Grid》
常见的NppStatus,可以看这里。
Resize
图像尺寸的resize操作。
// 指定x和y的resize尺寸
NppStatus nppiResizeSqrPixel_8u_C3R(const Npp8u *pSrc,
NppiSize oSrcSize,
int nSrcStep,
NppiRect oSrcROI,
Npp8u *pDst,
int nDstStep,
NppiRect oDstROI,
double nXFactor,
double nYFactor,
double nXShift,
double nYShift,
int eInterpolation);
// x和y的resize尺寸自动计算
NppStatus nppiResize_8u_C3R(const Npp8u *pSrc,
int nSrcStep,
NppiSize oSrcSize,
NppiRect oSrcRectROI,
Npp8u *pDst,
int nDstStep,
NppiSize oDstSize,
NppiRect oDstRectROI,
int eInterpolation);
// 多batch的resize
// 涉及到一个新的数据类型,NppiResizeBatchCXR
NppStatus nppiResizeBatch_8u_C3R(NppiSize oSmallestSrcSize,
NppiRect oSrcRectROI,
NppiSize oSmallestDstSize,
NppiRect oDstRectROI,
int eInterpolation,
NppiResizeBatchCXR *pBatchList,
unsigned int nBatchSize);
code
#include <iostream>
#include <cuda_runtime.h>
#include <npp.h>
#include <opencv2/opencv.hpp>
#define CUDA_FREE(ptr) { if (ptr != nullptr) { cudaFree(ptr); ptr = nullptr; } }
int main() {
std::string directory = "../";
cv::Mat image_dog = cv::imread(directory + "dog.png");
int image_width = image_dog.cols;
int image_height = image_dog.rows;
int image_size = image_width * image_height;
// =============== device memory ===============
// input
uint8_t *in_image;
cudaMalloc((void**)&in_image, image_size * 3 * sizeof(uint8_t));
cudaMemcpy(in_image, image_dog.data, image_size * 3 * sizeof(uint8_t), cudaMemcpyHostToDevice);
// output
double scale_w = 1.0 / 4;
double scale_h = 1.0 / 4;
uint8_t *out_ptr1, *out_ptr2;
int dst_width = image_width * scale_w;
int dst_height = image_height * scale_h;
cudaMalloc((void**)&out_ptr1, dst_width * dst_height * 3 * sizeof(uint8_t)); // 三通道
cudaMalloc((void**)&out_ptr2, dst_width * dst_height * 3 * sizeof(uint8_t)); // 三通道
// roi size
NppiSize in_size, out_size;
in_size.width = image_width;
in_size.height = image_height;
out_size.width = dst_width;
out_size.height = dst_height;
NppiRect rc1, rc2;
rc1.x = 0;
rc1.y = 0;
rc1.width = image_width;
rc1.height = image_height;
rc2.x = 0;
rc2.y = 0;
rc2.width = dst_width;
rc2.height = dst_height;
cv::Mat out_image = cv::Mat::zeros(dst_height, dst_width, CV_8UC3);
NppStatus status;
// =============== nppiResizeSqrPixel_8u_C3R ===============
// resize to half
status = nppiResizeSqrPixel_8u_C3R(in_image, in_size, image_width * 3, rc1, out_ptr1,
dst_width * 3, rc2, scale_w, scale_h, 10.0, 50.0,
NPPI_INTER_LINEAR);
if (status != NPP_SUCCESS) {
std::cout << "[GPU] ERROR nppiResizeSqrPixel_8u_C3R failed, status = " << status << std::endl;
return false;
}
cudaMemcpy(out_image.data, out_ptr1, dst_width * dst_height * 3, cudaMemcpyDeviceToHost);
cv::imwrite(directory + "resize_sqr.jpg", out_image);
// =============== nppiResize_8u_C3R ===============
// resize to half
status = nppiResize_8u_C3R(in_image, image_width * 3, in_size, rc1, out_ptr2,
dst_width * 3, out_size, rc2, NPPI_INTER_LINEAR);
if (status != NPP_SUCCESS) {
std::cout << "[GPU] ERROR nppiResize_8u_C3R failed, status = " << status << std::endl;
return false;
}
cudaMemcpy(out_image.data, out_ptr2, dst_width * dst_height * 3, cudaMemcpyDeviceToHost);
cv::imwrite(directory + "resize.jpg", out_image);
// free
CUDA_FREE(in_image)
CUDA_FREE(out_ptr1)
CUDA_FREE(out_ptr2)
}
make
cmake_minimum_required(VERSION 3.20)
project(test)
find_package(OpenCV REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS})
find_package(CUDA REQUIRED)
include_directories(${CUDA_INCLUDE_DIRS})
file(GLOB CUDA_LIBS "/usr/local/cuda/lib64/*.so")
add_executable(test test.cpp)
target_link_libraries(test
${OpenCV_LIBS}
${CUDA_LIBS}
)
result
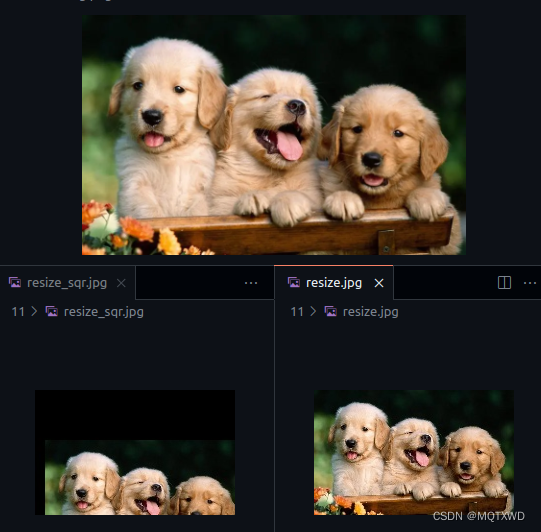
注意:
1.resizesqr的接口支持x和y不同scale的resize操作,并且可以添加左上角的offset值(result中的x和y分别添加了10像素和50像素的offset)
Remap
重映射,remap实现功能与原始的Opencv的功能一致。
NppStatus nppiRemap_8u_C3R(const Npp8u *pSrc,
NppiSize oSrcSize,
int nSrcStep,
NppiRect oSrcROI,
const Npp32f *pXMap,
int nXMapStep,
const Npp32f *pYMap,
int nYMapStep,
Npp8u *pDst,
int nDstStep,
NppiSize oDstSizeROI,
int eInterpolation);
code
#include <iostream>
#include <cuda_runtime.h>
#include <npp.h>
#include <opencv2/opencv.hpp>
#define CUDA_FREE(ptr) { if (ptr != nullptr) { cudaFree(ptr); ptr = nullptr; } }
int main() {
std::string directory = "../";
cv::Mat image_dog = cv::imread(directory + "dog.png");
int image_width = image_dog.cols;
int image_height = image_dog.rows;
int image_size = image_width * image_height;
// =============== device memory ===============
// input
uint8_t *in_image;
cudaMalloc((void**)&in_image, image_size * 3 * sizeof(uint8_t));
cudaMemcpy(in_image, image_dog.data, image_size * 3 * sizeof(uint8_t), cudaMemcpyHostToDevice);
cv::Mat mat_mapx = cv::Mat::zeros(image_height, image_width, CV_32FC1);
cv::Mat mat_mapy = cv::Mat::zeros(image_height, image_width, CV_32FC1);
for (int i = 0; i < image_height; ++i) {
for (int j = 0; j < image_width; ++j) {
mat_mapx.at<float>(i, j) = (float)j;
mat_mapy.at<float>(i, j) = (float)(image_height - i - 1);
}
}
float *mapx, *mapy;
cudaMalloc((void**)&mapx, image_size * sizeof(float));
cudaMalloc((void**)&mapy, image_size * sizeof(float));
cudaMemcpy(mapx, mat_mapx.data, image_size * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(mapy, mat_mapy.data, image_size * sizeof(float), cudaMemcpyHostToDevice);
// output
uint8_t *out_ptr1;
cudaMalloc((void**)&out_ptr1, image_size * 3 * sizeof(uint8_t)); // 三通道
// size
NppiSize in_size, out_size;
in_size.width = image_width;
in_size.height = image_height;
out_size.width = image_width;
out_size.height = image_height;
NppiRect rc1;
rc1.x = 0;
rc1.y = 0;
rc1.width = image_width;
rc1.height = image_height;
cv::Mat out_image = cv::Mat::zeros(image_height, image_width, CV_8UC3);
NppStatus status;
// =============== nppiResizeSqrPixel_8u_C3R ===============
// resize to half
status = nppiRemap_8u_C3R(in_image, in_size, image_width * 3, rc1, mapx,
image_width * sizeof(float), mapy, image_width * sizeof(float),
out_ptr1, image_width * 3, out_size, NPPI_INTER_LINEAR);
if (status != NPP_SUCCESS) {
std::cout << "[GPU] ERROR nppiRemap_8u_C3R failed, status = " << status << std::endl;
return false;
}
cudaMemcpy(out_image.data, out_ptr1, image_size* 3, cudaMemcpyDeviceToHost);
cv::imwrite(directory + "remap.jpg", out_image);
// free
CUDA_FREE(in_image)
CUDA_FREE(mapx)
CUDA_FREE(mapy)
CUDA_FREE(out_ptr1)
}
make
cmake_minimum_required(VERSION 3.20)
project(test)
find_package(OpenCV REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS})
find_package(CUDA REQUIRED)
include_directories(${CUDA_INCLUDE_DIRS})
file(GLOB CUDA_LIBS "/usr/local/cuda/lib64/*.so")
add_executable(test test.cpp)
target_link_libraries(test
${OpenCV_LIBS}
${CUDA_LIBS}
)
result
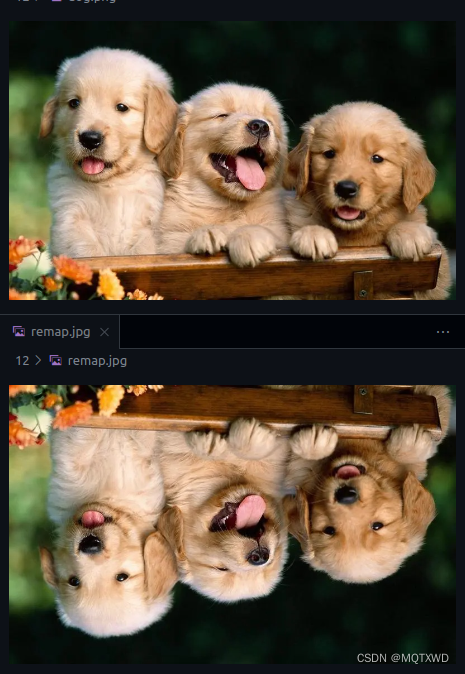
注意点:
- mapx和mapy的数据类型是NPP32f(float)类型,因此在指定x和y的step的时候需要惩乘上float的字节数,不然出来的结果不对。
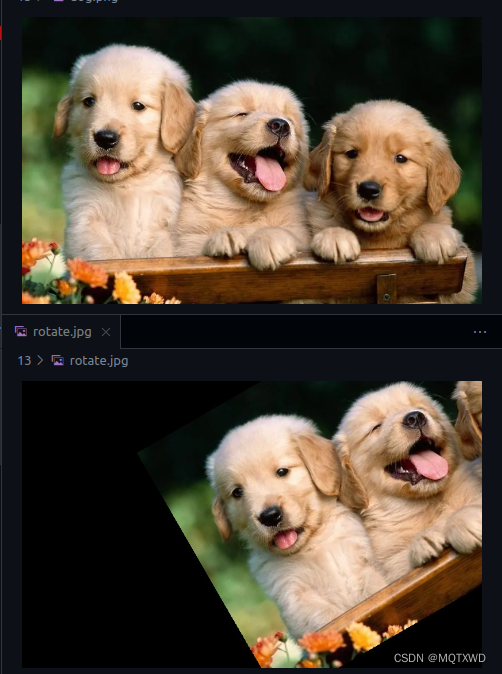
Rotate
旋转,该模块除了直接提供旋转的接口,还同步提供了根据角度和品阿姨计算旋转矩阵的接口
// 除了当前接口,还提供了一个返回四元素的接口
NppStatus nppiGetRotateBound(NppiRect oSrcROI,
double aBoundingBox[2][2],
double nAngle,
double nShiftX,
double nShiftY);
// 旋转
NppStatus nppiRotate_8u_C3R(const Npp8u *pSrc,
NppiSize oSrcSize,
int nSrcStep,
NppiRect oSrcROI,
Npp8u *pDst,
int nDstStep,
NppiRect oDstROI,
double nAngle,
double nShiftX,
double nShiftY,
int eInterpolation);
code
#include <iostream>
#include <cuda_runtime.h>
#include <npp.h>
#include <opencv2/opencv.hpp>
#define CUDA_FREE(ptr) { if (ptr != nullptr) { cudaFree(ptr); ptr = nullptr; } }
int main() {
std::string directory = "../";
cv::Mat image_dog = cv::imread(directory + "dog.png");
int image_width = image_dog.cols;
int image_height = image_dog.rows;
int image_size = image_width * image_height;
// =============== device memory ===============
// input
uint8_t *in_image;
cudaMalloc((void**)&in_image, image_size * 3 * sizeof(uint8_t));
cudaMemcpy(in_image, image_dog.data, image_size * 3 * sizeof(uint8_t), cudaMemcpyHostToDevice);
// output
uint8_t *out_ptr1;
cudaMalloc((void**)&out_ptr1, image_size * 3 * sizeof(uint8_t)); // 三通道
// size
NppiSize in_size, out_size;
in_size.width = image_width;
in_size.height = image_height;
out_size.width = image_width;
out_size.height = image_height;
NppiRect rc1;
rc1.x = 0;
rc1.y = 0;
rc1.width = image_width;
rc1.height = image_height;
cv::Mat out_image = cv::Mat::zeros(image_height, image_width, CV_8UC3);
NppStatus status;
// =============== nppiResizeSqrPixel_8u_C3R ===============
// resize to half
double angle = 30.0;
double shift_x = image_width / 4;
double shift_y = image_height / 4;
status = nppiRotate_8u_C3R(in_image, in_size, image_width * 3, rc1, out_ptr1, image_width * 3,
rc1, angle, shift_x, shift_y, NPPI_INTER_LINEAR);
if (status != NPP_SUCCESS) {
std::cout << "[GPU] ERROR nppiRemap_8u_C3R failed, status = " << status << std::endl;
return false;
}
cudaMemcpy(out_image.data, out_ptr1, image_size* 3, cudaMemcpyDeviceToHost);
cv::imwrite(directory + "rotate.jpg", out_image);
// free
CUDA_FREE(in_image)
CUDA_FREE(out_ptr1)
}
make
cmake_minimum_required(VERSION 3.20)
project(test)
find_package(OpenCV REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS})
find_package(CUDA REQUIRED)
include_directories(${CUDA_INCLUDE_DIRS})
file(GLOB CUDA_LIBS "/usr/local/cuda/lib64/*.so")
add_executable(test test.cpp)
target_link_libraries(test
${OpenCV_LIBS}
${CUDA_LIBS}
)
result
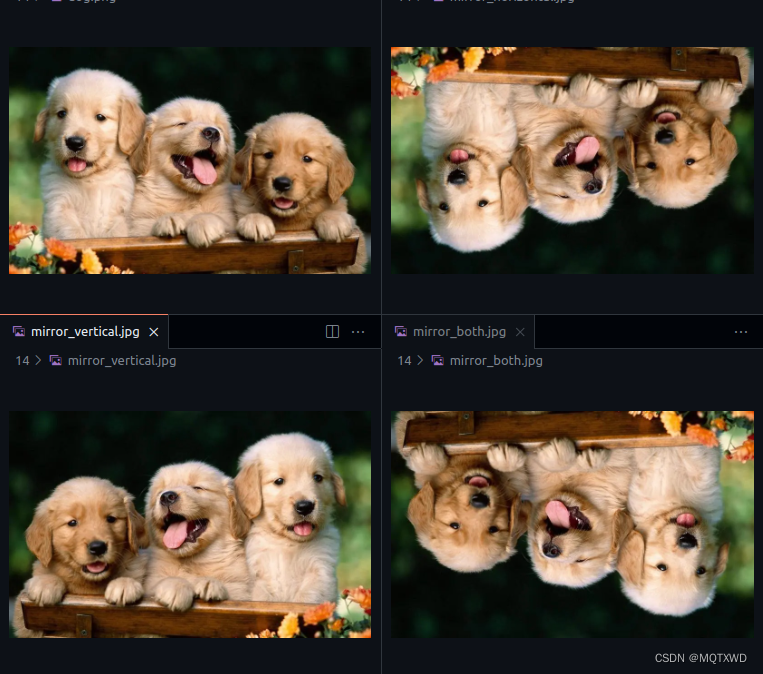
Mirror
主要是用于将图像用于镜像操作。
enum NppiAxis {
NPP_HORIZONTAL_AXIS,
NPP_VERTICAL_AXIS,
NPP_BOTH_AXIS
};
// 新增枚举,用于表示镜像的轴
NppStatus nppiMirror_8u_C3R(const Npp8u *pSrc,
int nSrcStep,
Npp8u *pDst,
int nDstStep,
NppiSize oROI,
NppiAxis flip);
code
#include <iostream>
#include <cuda_runtime.h>
#include <npp.h>
#include <opencv2/opencv.hpp>
#define CUDA_FREE(ptr) { if (ptr != nullptr) { cudaFree(ptr); ptr = nullptr; } }
int main() {
std::string directory = "../";
cv::Mat image_dog = cv::imread(directory + "dog.png");
int image_width = image_dog.cols;
int image_height = image_dog.rows;
int image_size = image_width * image_height;
// =============== device memory ===============
// input
uint8_t *in_image;
cudaMalloc((void**)&in_image, image_size * 3 * sizeof(uint8_t));
cudaMemcpy(in_image, image_dog.data, image_size * 3 * sizeof(uint8_t), cudaMemcpyHostToDevice);
// output
uint8_t *out_ptr1;
cudaMalloc((void**)&out_ptr1, image_size * 3 * sizeof(uint8_t)); // 三通道
NppiSize in_size;
in_size.width = image_width;
in_size.height = image_height;
cv::Mat out_image = cv::Mat::zeros(image_height, image_width, CV_8UC3);
NppStatus status;
// =============== nppiMirror_8u_C3R ===============
status = nppiMirror_8u_C3R(in_image, image_width * 3, out_ptr1, image_width * 3,
in_size, NPP_HORIZONTAL_AXIS);
if (status != NPP_SUCCESS) {
std::cout << "[GPU] ERROR nppiMirror_8u_C3R failed, status = " << status << std::endl;
return false;
}
cudaMemcpy(out_image.data, out_ptr1, image_size* 3, cudaMemcpyDeviceToHost);
cv::imwrite(directory + "mirror_horizontal.jpg", out_image);
// =============== nppiMirror_8u_C3R ===============
status = nppiMirror_8u_C3R(in_image, image_width * 3, out_ptr1, image_width * 3,
in_size, NPP_VERTICAL_AXIS);
if (status != NPP_SUCCESS) {
std::cout << "[GPU] ERROR nppiMirror_8u_C3R failed, status = " << status << std::endl;
return false;
}
cudaMemcpy(out_image.data, out_ptr1, image_size* 3, cudaMemcpyDeviceToHost);
cv::imwrite(directory + "mirror_vertical.jpg", out_image);
// =============== nppiMirror_8u_C3R ===============
status = nppiMirror_8u_C3R(in_image, image_width * 3, out_ptr1, image_width * 3,
in_size, NPP_BOTH_AXIS);
if (status != NPP_SUCCESS) {
std::cout << "[GPU] ERROR nppiMirror_8u_C3R failed, status = " << status << std::endl;
return false;
}
cudaMemcpy(out_image.data, out_ptr1, image_size* 3, cudaMemcpyDeviceToHost);
cv::imwrite(directory + "mirror_both.jpg", out_image);
// free
CUDA_FREE(in_image)
CUDA_FREE(out_ptr1)
}
make
cmake_minimum_required(VERSION 3.20)
project(test)
find_package(OpenCV REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS})
find_package(CUDA REQUIRED)
include_directories(${CUDA_INCLUDE_DIRS})
file(GLOB CUDA_LIBS "/usr/local/cuda/lib64/*.so")
add_executable(test test.cpp)
target_link_libraries(test
${OpenCV_LIBS}
${CUDA_LIBS}
)
result