目录
一、从键盘输入数据
二、函数方法读取
1.读取数据文件
2.从屏幕读取数据
1.scan
2.readline
3. 读取固定宽度数据文件
三、读取csv文件
四、读取表格数据文件
五、从网络中读取表格或者CSV数据文件
一、从键盘输入数据
mydata <- data.frame(age=numeric(0), gender=character(0),
weight=numeric(0))
mydata <- edit(mydata)
输入了我们的上述代码之后,我们就进入了一个编辑文本模式,我们可以使用vim的编辑文本的语法命令来编辑我们的数据

二、函数方法读取
1.读取数据文件
x<-scan(text = "1 2 3")
x

#输入需要读取的文件路径,并且将读取到的数据作为一个向量存储
w <- scan("/Users/Documents/R/city.txt")
w

w<-scan("/Users/Documents/R/data/weight.data")
w

2.从屏幕读取数据
1.scan
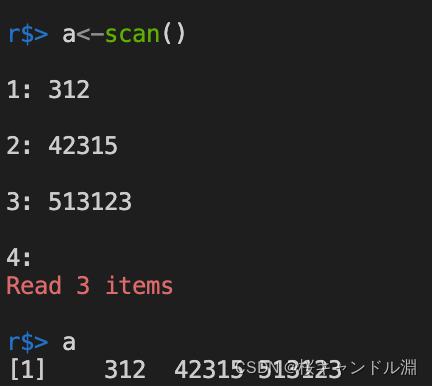
从屏幕读取数值型数据,当我们输入完了我们的数据之后,我们连续两下回车,就能够结束输入,生成一个数值型的向量。
x<-scan()
x
从屏幕读取字符串型数据
y <- scan(what="")
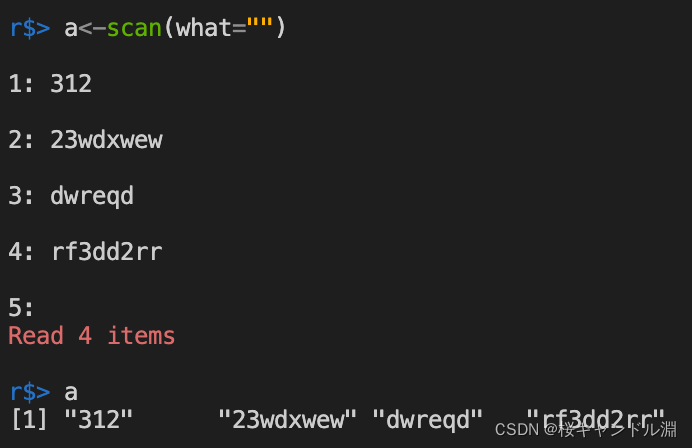
或者采用下面的方式
2.readline
readline能够支持读取从键盘输入的一行数据,按回车之后就将这一整行数据传入变量中
x=readline()

3. 读取固定宽度数据文件
第一个参数为我们文件的完整的路径名,宽度为一个向量,w1表示第一个变量的宽度,w2表示第二个变量的宽度,以此类推。
mydata <- read.fwf("filename",widths=c(W1,W2,...,Wn))
mydata1 <- read.fwf("/Users/Documents/R/city.txt",widths=c(4))
mydata1

mydata<-read.fwf("/Users/Documents/R/data/FixWideData.txt",widths=c(10,10,4,-1,4))

我们同样可以使用指定col.names的方法指定我们索引的名称,其中-1参数是指忽略两个年份之间的空格。(正如我们R语言入门博客中写的,-1表示忽略一列数据)
mydata2<-read.fwf("/Users/Documents/R/data/FixWideData.txt",widths=c(10,10,4,-1,4),col.names=c("Last","First","Born","Died"))
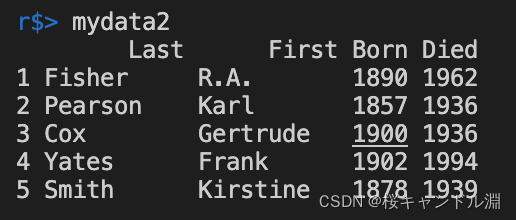
下面的图像时我们的数据文件,我们发现我们的数据虽然长长短短,但是通过空格进行对齐了,所以我们可以指定文件的宽度来读取到我们的具体的数据

但是我们发现这样的数据文件会出现如下的报错 ,这是因为我们在数据文件的最后一行结束的时候没有回车,我们的编译器找不到我们的结尾的标志,只要在文件的结尾加上一个回车,就不会报错了

三、读取csv文件
#这里将我们的文件路径传入
mydata0<-read.csv("/Users/Documents/R/city.csv")
mydata0

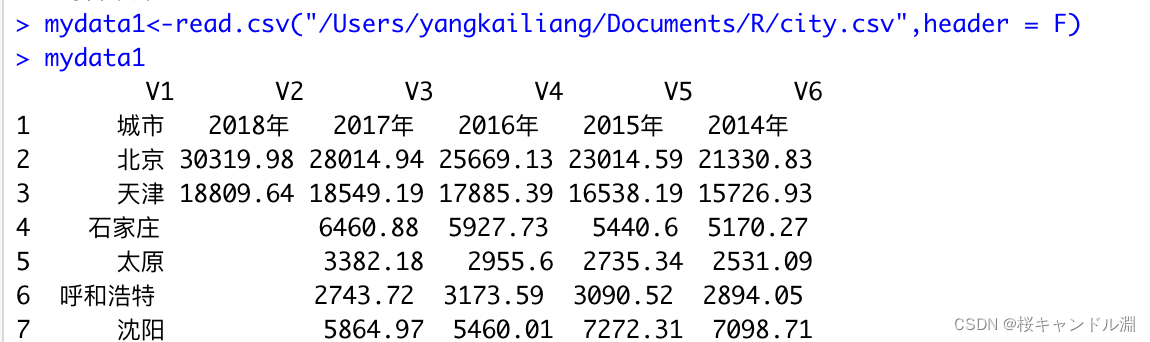
#当我们指定我们的header为F后,我们原本数据集中的列名就归入了数据中,然后会自动生成一组新的索引,如下图所示
mydata1<-read.csv("/Users/Documents/R/city.csv",header = F)
mydata1
as.is就是设置是否将字符型转化为因子型变量
mydata2 <- read.csv("/Users/Documents/R/data/TableData.txt", as.is=F)
mydata2
mydata2 <- read.csv("/Users/Documents/R/data/TableData.txt", as.is=T)
mydata2
四、读取表格数据文件
每一行数据是一个观测
在每个观测中,不同的变量由一个分隔符隔开,比如空格,tab,冒号,逗号
每个观测包含的变量数相同。
read.table( ).
mydata <- read.table(file, header= logical_value,sep="delimiter", rowname="name"
mydata0 <- read.table("/Users/Documents/R/data/TableData.txt")


当然我们也可以指定我们的分隔符
mydata1 <- read.table("/Users/Documents/R/data/CommaData.txt", sep=",")
mydata1


添加了stringAsFactor=False之后,数据框不会把字符型转换为因子
mydata2 <- read.table("/Users/Documents/R/data/TableData.txt",stringsAsFactor=FALSE)
mydata2

当我们添加参数header=T以后,我们原来的数据集中的第一行的数据就会变成我们的索引
mydata3 <- read.table("/Users/Documents/R/data/TableData.txt",header=T,stringsAsFactor=F)
mydata3

五、从网络中读取表格或者CSV数据文件
read.csv()
read.table()
scan()
都可以获取远程服务器的数据
mydata0 <- read.csv("http://www.example.com/download/data.csv")
mydata1 <- read.table("ftp://ftp.example.com/download/data.csv")