MyBatis笔记(一)–核心配置文件、sql映射文件、多对一、一对多
MyBatis学习笔记(一), 内容包括:
- MyBatis入门案例
- MyBatis核心配置文件结构说明
- sql映射文件结构说明
- 查询结果封装resultMap
- 多对一查询association、一对多查询collection
学习视频:尚硅谷雷丰阳老师MyBatis
https://www.bilibili.com/video/BV1bb411A7bD
1. MyBatis简介
连接数据库的方法:
工具: JDBC→Dbutils(QueryRunner)→JdbcTemplate

框架: 整体解决方案
Hibernate: 全自动全映射ORM(Object Relation Mapping)框架,旨在消除SQL

缺点:
- 长难复杂SQL,对于Hibernate而言处理也不容易
- 内部自动生产的SQL,不容易做特殊优化。对开发人员而言,核心sql还是需要自己优化( HQL)
- 基于全映射的全自动框架,大量字段的POJO进行部分映射时比较困难,导致数据库性能下降
SQL和Java编码分开,功能边界清晰,一个专注业务、一个专注数据。
MyBatis: 半自动,轻量级的框架,sql语句提取到配置文件中编写

-
MyBatis 是一个半自动化的持久化层框架,支持自定义 SQL、存储过程以及高级映射。
-
MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。
-
MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO映射成数据库中的记录。
-
项目地址:https://github.com/mybatis/mybatis-3/
-
Maven 依赖:
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>x.x.x</version>
</dependency>
官方文档:https://mybatis.org/mybatis-3/zh/index.html
2. MyBatis案例之HelloWorld
核心步骤:
- 数据库表与对应的实体类Employee、接口EmployeeMapper
- 全局配置文件(核心配置文件)mybatis-config.xml
- 根据全局配置文件创建SqlSessionFactory对象,SqlSessionFactoryBulid→SqlSessionFactory→SqlSession
- sql映射文件EmployeeMapper.xml,配置了每一个sql,以及sql的封装规则,需要在全局配置文件中注册sql映射文件
- 由sqlSession对象实例执行sql语句,或者获取接口的代理对象执行
2.1 数据库环境
创建tbl_employee表并插入三条数据:
CREATE TABLE tbl_employee(
id INT(10) PRIMARY KEY AUTO_INCREMENT,
last_name VARCHAR(255),
gender CHAR(1),
email VARCHAR(255)
)ENGINE=INNODB DEFAULT CHARSET=utf8;
INSERT INTO tbl_employee VALUES
(1,"zhansgan",0,"zhangsan@qq.com"),
(2,"lisi",0,"lisi@163.com"),
(3,"wangwu",1,"wangwu@126.com");
2.2 创建实体类
- 新建一个普通的Maven项目;
- 在pom.xml文件中导入Maven依赖,包括:mysql-connector-java,mybatisjuint,log4j
- 创建与数据库表对应的实体类Employee,名称与数据库表的字段保持一致。如果不一致查询会出问题,可以用别名解决
<dependencies>
<!--mybatis-->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.4</version>
</dependency>
<!--mysql-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<!--junit-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
</dependency>
<!--log4j -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>
- 实体类com.xiao.pojo.Employee:
public class Employee {
private Integer id;
private String lastName; //注意,该名称与数据库表的字段名不一致,查询会出现问题,可以用别名解决
private String email;
private String gender;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender;
}
@Override
public String toString() {
return "Employee{" +
"id=" + id +
", lastName='" + lastName + '\'' +
", email='" + email + '\'' +
", gender='" + gender + '\'' +
'}';
}
}
2.3 MyBatis核心配置文件
- 在resources目录下编写mybatis核心配置文件:mybatis-config.xml
包含信息:数据库连接参数、事务类型、注册映射文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<!--mybatis核心配置文件-->
<configuration>
<!--配置环境组,选择默认的环境id-->
<environments default="development">
<!--配置单个环境并指定id为development-->
<!--可以同时配置多个环境,但是只能选择一个使用-->
<environment id="development">
<!--配置事务管理类型,JDBC-->
<transactionManager type="JDBC"/>
<!--配置连接池POOLED-->
<dataSource type="POOLED">
<!--数据库连接池4个参数-->
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mybatis?useSSL=false&useUnicode=true&characterEncoding=UTF-8"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</dataSource>
</environment>
</environments>
<!--配置映射,注册Mapper文件-->
<mappers>
<mapper resource="com/xiao/dao/EmployeeMapper.xml"/>
</mappers>
</configuration>
注意:
在xml配置文件中,url中的 &符号需要写成 &
2.4 sql映射文件
在resources目录下表编写sql映射文件:EmployeeMapper.xml
sql语句的参数用#获取
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--namespace:名称空间,可以绑定一个Mapper接口-->
<!--编写sql语句-->
<!--id:唯一标识,如果有Mapper接口文件,需要对应其中的方法名-->
<!--resultType:对应返回结果类型-->
<!--#{id}:从传递过来的参数中取出id值-->
<mapper namespace="com.xiao.dao.EmployeeMapper">
<select id="selectEmp" resultType="com.xiao.pojo.Employee">
select * from tbl_employee where id = #{id}
</select>
</mapper>
2.5 测试
根据全局配置文件创建SqlSessionFactory对象,SqlSessionFactoryBulid→SqlSessionFactory→SqlSession。由sqlSession对象实例执行sql语句。
public class MyBatisTest {
@Test
public void test() throws IOException {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
//由SqlSessionFactoryBuilder对象获取SqlSessionFactory对象
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//由SqlSession工厂获得SqlSession对象,使用其进行增删改查
SqlSession sqlSession = sqlSessionFactory.openSession();
try {
//sqlSession,直接执行已经映射的sql语句
//selectOne()中两个参数:sql的唯一标识(对应sql映射文件中的namespace.id)和执行sql需要的参数
Employee employee = sqlSession.selectOne("com.xiao.dao.EmployeeMapper.selectEmp", 1);
System.out.println(employee);
} finally {
//一个sqlSession就是和数据库的一次会话,使用完之后需要关闭资源
sqlSession.close();
}
}
}
查询结果:
Employee{id=1, lastName='null', email='zhangsan@qq.com', gender='0'}
由于实体类的成员变量名和字段名不一致,因此lastName查询结果为null,可以在sql语句中取别名解决,也可以在sql映射文件中配置,后面会讲到。
修改sql语句:
select id,last_name lastName,gender,email from tbl_employee where id = #{id}
查询结果:
Employee{id=1, lastName='zhansgan', email='zhangsan@qq.com', gender='0'}
2.6 接口文件
一种更有效的方法:创建接口文件com.xiao.dao.EmployeeMapper与sql映射文件绑定,在接口文件中定义方法,可以声明操作的返回值和参数。
注意:
- sql映射文件中的namesapce要与对应的接口文件全路径名一致
- sql映射文件中的sql语句标签中的id要与对应的接口文件中的方法名一致
public interface EmployeeMapper {
//定义一个查询方法
Employee selectEmployeeById(Integer id);
}
测试文件:
try { //获得接口文件的代理对象,执行方法
EmployeeMapper mapper = sqlSession.getMapper(EmployeeMapper.class);
System.out.println(mapper.selectEmployeeById(1));
} finally {
sqlSession.close();
}
3. 几个类的说明
3.1 SqlSessionFactoryBuilder
3.2 SqlSessionFactory
- SqlSession工厂,每个基于 MyBatis 的应用都以一个 SqlSessionFactory 的实例为核心,由SqlSessionFactoryBuilder类创建。
- SqlSessionFactory类可以用于创建SqlSession类,方法:
openSession(),传入参数true可以设置为自动提交事务。
3.3 SqlSession
- SqlSession代表和数据库的一次会话,用完必须关闭,是非线程安全的。可以从SqlSessionFactory中获得 SqlSession 的实例;
- SqlSession 提供了在数据库执行 SQL 命令所需的所有方法,可以通过 SqlSession 实例来获得映射器接口的代理对象,即接口和xml文件进行绑定。方法:
getMapper(),需要传入dao接口的class类型参数UserDao.class
3.4 作用域(Scope)和生命周期
-
SqlSessionFactoryBuilder:
可以理解为数据库连接池对象,一旦创建了 SqlSessionFactory,就不再需要它了,因此最佳作用域是方法作用域(也就是局部方法变量);
-
SqlSessionFactory:
可以理解为数据库连接对象,一旦被创建就应该在应用的运行期间一直存在,因此 SqlSessionFactory 的最佳作用域是应用作用域。使用单例模式或者静态单例模式。
-
SqlSession:
连接到连接池的一个请求,每个线程都有它自己的 SqlSession 实例。SqlSession 的实例不是线程安全的,因此是不能被共享的,所以它的最佳的作用域是请求或方法作用域。
为了确保每次都能执行关闭操作,把关闭操作放到 finally 块中。
4. 全局配置文件
约束文件:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
MyBatis 的配置文件包含了会深深影响 MyBatis 行为的设置和属性信息。 配置文档的顶层结构如下,必须按顺序配置
-
configuration(配置)
- properties(属性)
- settings(设置)
- typeAliases(类型别名)
- typeHandlers(类型处理器)
- objectFactory(对象工厂)
- plugins(插件)
-
environments(环境配置)
- environment(环境变量)
- transactionManager(事务管理器)
- dataSource(数据源)
- databaseIdProvider(数据库厂商标识)
- mappers(映射器)
4.1 属性(properties)
通过properties属性可以实现引用配置文件,这些属性都是可以外部配置且可动态替换的。
- 可以在核心配置文件中配置数据库连接池的4个参数,设置好的参数可以在整个配置文件中替换需要动态配置的属性值:
<properties>
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mybatis"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</properties>
....
<!--使用${name}引用相应的值-->
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
....
#外部配置文件
driver=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/mybatis?useSSL=false&useUnicode=true&characterEncoding=UTF-8
username=root
password=root
核心配置文件:
<!--在核心配置文件中引入外部配置文件,然后就可以使用${name}引用-->
<properties resource="db.properties">
</properties>
【注意事项】:如果一个属性在不只一个地方进行了配置,那么,MyBatis 将按照下面的顺序来加载:
- 首先读取在 properties 元素体内指定的属性。
- 然后根据 properties 元素中的 resource 属性读取类路径下属性文件,或根据 url 属性指定的路径读取属性文件,并覆盖之前读取过的同名属性。
- 最后读取作为方法参数传递的属性,并覆盖之前读取过的同名属性。
因此,通过方法参数传递的属性具有最高优先级,resource/url 属性中指定的配置文件次之,最低优先级的则是 properties 元素中指定的属性。
5.2 设置(settings)
是 MyBatis 中极为重要的调整设置,它们会改变 MyBatis 的运行时行为。
常用设置:
- mapUnderscoreToCamelCase:是否开启驼峰命名自动映射,即从经典数据库列名 A_COLUMN 映射到经典 Java 属性名 aColumn,默认为flase
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
- jdbcTypeForNull:当没有为参数指定特定的 JDBC 类型时,空值的默认 JDBC 类型。默认是 OTHER,但是如果用Oracle数据库,需要改为NULL
- autoMappingBehavior:指定 MyBatis 应如何自动映射列到字段或属性。 NONE 表示关闭自动映射;PARTIAL 只会自动映射没有定义嵌套结果映射的字段。 FULL 会自动映射任何复杂的结果集(无论是否嵌套),默认为PARTIAL
- lazyLoadingEnabled:延迟加载的全局开关。当开启时,所有关联对象都会延迟加载。 特定关联关系中可通过设置
fetchType 属性来覆盖该项的开关状态。默认是false
- aggressiveLazyLoading:开启时,任一方法的调用都会加载该对象的所有延迟加载属性。 否则,每个延迟加载属性会按需加载。
5.3 类型别名(typeAliases)
类型别名可为 Java 类型设置一个缩写名字。 仅用于 XML 配置,意在降低冗余的全限定类名书写。别名不区分大小写
- 单个类起别名,
<typeAlias>标签:
- type:指定要起别名的类型全类名,默认是类名小写employee(其实不区分大小写)
- alias:指定新的别名
<typeAliases>
<!-- type:指定要起别名的类型全类名,默认是类名小写employee-->
<!-- alias:指定新的别名-->
<typeAlias type="com.xiao.pojo.Employee"/>
</typeAliases>
<typeAliases>
<package name="com.xiao.pojo"/>
</typeAliases>
- 批量情况下,如果指定包下的子包中有同名的类,会产生冲突,可以使用注解解决:在实体类上注解
@Alias,则别名为其注解值:
@Alias("Emp")
public class Employee {
...
}
常见的 Java 类型内建的类型别名。它们都是不区分大小写的,自定义的别名不要与其重复。
基本类型前面加下划线,引用类型首字母小写:
| 别名 |
映射的类型 |
| _byte |
byte |
| _long |
long |
| _short |
short |
| _int |
int |
| _integer |
int |
| _double |
double |
| _float |
float |
| _boolean |
boolean |
| string |
String |
| byte |
Byte |
| long |
Long |
| short |
Short |
| int |
Integer |
| integer |
Integer |
| double |
Double |
| float |
Float |
| boolean |
Boolean |
| date |
Date |
| decimal |
BigDecimal |
| bigdecimal |
BigDecimal |
| object |
Object |
| map |
Map |
| hashmap |
HashMap |
| list |
List |
| arraylist |
ArrayList |
| collection |
Collection |
| iterator |
Iterator |
5.4 类型处理器(typeHandlers)
数据库里的字段类型与Java的数据类型进行映射。
在设置预处理语句(PreparedStatement)中的参数或从结果集中取出一个值时, 都会用类型处理器将获取到的值以合适的方式转换成 Java 类型。
5.5 插件(plugins)
MyBatis 允许在映射语句执行过程中的某一点进行拦截调用。默认情况下,MyBatis 允许使用插件来拦截的方法调用包括:
- Executor (update, query, flushStatements, commit, rollback, getTransaction, close, isClosed)
- 参数处理器:ParameterHandler (getParameterObject, setParameters)
- ResultSetHandler (handleResultSets, handleOutputParameters)
- sql语句处理器:StatementHandler (prepare, parameterize, batch, update, query)
5.6 环境配置(environments)
MyBatis 可以配置成适应多种环境,可以配置多个环境,但每个 SqlSessionFactory 实例只能选择一种环境。 default参数指定使用某种环境。
-
transactionManager:事务管理器,有两种类型,type="[JDBC|MANAGED]",默认的事务管理器就是JDBC。也可以自定义事务管理器:实现TransactionFactory接口,type指定为全类名
-
dataSource:数据源,有三种内建的数据源类型, type="[UNPOOLED|POOLED|JNDI]"),也可以自己实现DataSourceFactory接口自定义数据源
<environments default="development">
<environment id="development">
<transactionManager type="JDBC">
<property name="..." value="..."/>
</transactionManager>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
【注意事项】:
- 默认使用的环境 id(比如:default=“development”)。
- 每个 environment 元素定义的环境 id(比如:id=“development”)。
- 事务管理器的配置(比如:type=“JDBC”)。
- 数据源的配置(比如:type=“POOLED”)。
5.7 数据库厂商标识(databaseIdProvider)
MyBatis 可以根据不同的数据库厂商执行不同的语句,考虑了移植性。
得到数据库厂商的标识(驱动getDatabaseProductName()),MyBatis就能根据数据库厂商标识来执行不同的sql。
- 为不同的数据库的厂商标识取别名:
- 查询语句标签中指定databaseId元素值,会优先执行带该标识的,不带标签的语句会舍弃
<databaseIdProvider type="DB_VENDOR">
<property name="SQL Server" value="sqlserver"/>
<property name="DB2" value="db2"/>
<property name="Oracle" value="oracle" />
</databaseIdProvider>
5.8 映射器(mappers)
需要告诉 MyBatis 到哪里去找到 sql语句。可以使用相对于类路径的资源引用,或完全限定资源定位符(包括 file:/// 形式的 URL),或类名和包名等。
- resource:指定sql映射文件的路径
- url:使用网上的资源或者使用本地磁盘路径上的文件
- class:注册接口,如果有sql映射文件,映射文件必须和接口同目录同名;也可以在接口上写注解,这样就不需要sql映射文件
- package:批量注册,将包内的映射器接口实现全部注册为映射器,作用同class
<mappers>
<!-- 使用相对于类路径的资源引用 -->
<mapper resource="org/mybatis/builder/AuthorMapper.xml"/>
<!-- 使用完全限定资源定位符(URL) -->
<mapper url="file:///var/mappers/AuthorMapper.xml"/>
<!-- 使用映射器接口实现类的完全限定类名 -->
<mapper class="org.mybatis.builder.AuthorMapper"/>
<!-- 将包内的映射器接口实现全部注册为映射器 -->
<package name="org.mybatis.builder"/>
</mappers>
在dao接口文件中,用注解实现查询:
public interface EmployeeMapper {
//定义一个查询方法
@Select("select * from tbl_employee where id = #{id}")
Employee selectEmployeeById(Integer id);
}
【一个小坑】:
- class:注册接口,如果有sql映射文件,映射文件必须和接口同目录同名
- 在resources中建立多级目录时,用 / 隔开,但是创建完后显示的是 . 。如果新建目录时用 .会出错。
5. 映射文件
映射文件指导MyBatis如何进行数据库增删改。
5.1 基本的增删改查
- insert –- 映射插入语句
- update –- 映射更新语句
- delete –- 映射删除语句
- select –- 映射查询语句
- 首先在接口文件com.xiao.dao.EmployeeMapper中声明对应的增删改查方法,
同时可以设置返回值类型Integer、Long、Boolean,表示被影响的行数
public interface EmployeeMapper {
//定义一个查询方法
@Select("select * from tbl_employee where id = #{id}")
Employee selectEmployeeById(Integer id);
//增加
void addEmp(Employee employee);
//根据id删除
void deleteEmpById(Integer id);
//修改
void updateEmp(Employee employee);
}
- 然后在sql映射文件EmployeeMapper.xml中编写相应的sql语句
<!--parameterType:参数类型,可以省略-->
<insert id="addEmp" parameterType="employee">
insert into tbl_employee (last_name, gender, email) value (#{lastName},#{gender},#{email})
</insert>
<delete id="deleteEmpById">
delete from tbl_employee where id = #{id}
</delete>
<update id="updateEmp">
update tbl_employee set last_name=#{lastName},email=#{email},gender=#{gender}
where id = #{id}
</update>
- 测试:
public void test2() throws IOException {
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
//默认不自动提交事务,需要手动提交,或者构造方法传入true
SqlSession sqlSession = sqlSessionFactory.openSession();
try {
EmployeeMapper mapper = sqlSession.getMapper(EmployeeMapper.class);
//增
mapper.addEmp(new Employee(4,"林青霞","lingqingxia@163.com","1"));
//删
mapper.deleteEmpById(2);
//改
mapper.updateEmp(new Employee(1,"张柏芝","zhangbozhi@qq.com","1"));
// 手动提交事务
sqlSession.commit();
} finally {
sqlSession.close();
}
}
注意事项:增删改需要提交事务
sqlSessionFactory.openSession():需要手动提交, sqlSession.commit();
sqlSessionFactory.openSession(true)是自动提交事务的
5.2 获取自增主键的值
MySQL支持自增主键,在MyBatis中也是使用statement.getGeneratedKeys()获取自增主键的值。
用法,insert标签中:
- useGeneratedKeys=“true”:使用自增主键获取主键值策略
- keyProperty=“id”:获取到的主键封装给JavaBean的id属性
<!--useGeneratedKeys="true":使用自增主键获取主键值策略-->
<!--keyProperty="id":获取到的主键封装给JavaBean的id属性-->
<insert id="addEmp" parameterType="employee" useGeneratedKeys="true" keyProperty="id">
insert into tbl_employee (last_name, gender, email) value (#{lastName},#{gender},#{email})
</insert>
测试:employee.getId()方法可以获取到自增的主键值
Employee employee = new Employee(null,"Tom","tom@126.com","0");
mapper.addEmp(employee);
System.out.println(employee.getId());
5.3 参数处理
取参数的方式:#{参数名}
01 单个参数
MyBatis不会做处理,传入id,sql语句中写 #{idabc} 也能取到参数
02 多个参数
会被封装成一个map,#{}就是从map中获取指定key值的value。
key:param1,…paramN,或者参数的索引也可以
value:传入的参数值
如果按照之前的写法会报异常:
Employee employee = mapper.selectEmpByIdAndName(6, "Tom");
<select id="selectEmpByIdAndName" resultType="employee">
select * from tbl_employee where id = #{id} and last_name=#{lastName}
</select>
BindingException: Parameter ‘id’ not found. Available parameters are [arg1, arg0, param1, param2]
正确写法,但是一般不这么用:
select * from tbl_employee where id = #{param1} and last_name=#{param2}
常规用法:在接口方法中加注解@Param: 相当于key中保存的是@Param注解指定的值
Employee selectEmpByIdAndName(@Param("id") Integer id, @Param("lastName") String lastName);
03 传入对象
- 如果多个参数正好是业务逻辑的数据模型,就可以直接传入POJO,#{属性名}取出传入的POJO的属性值
- 如果不是业务模型中的数据,没有对应的POJO,也可以传入map,#{key}取出map中对应的值,或者编写一个TO(Transfer Object )数据传输对象。
//封装传入参数为Map,查询
Employee selectEmpByMap(Map<String,Object> map);
HashMap<String,Object> map = new HashMap<>();
//注意sql语句中#{id},#{lastName}与map中的键字段名称一一对应
map.put("id",6);
map.put("lastName","Tom");
Employee employee = mapper.selectEmpByMap(map);
System.out.println(employee);
select * from tbl_employee where id = #{id} and last_name=#{lastName}
04 几种情况小结
-
Employee getEmp(@Param("id") Integer id, String lastName)
取值:id ==> #{id}或者#{param1},lastName ==> #{param2}
-
Employee getEmp(Integer id, @Param("e") Employee emp)
取值:id ==> #{param1},lastName ==> #{e.lastName}或者 #{param2.lastName}
-
如果传入的是Collection类型或者是数组,则会把传入的集合或者数组封装在map中
key:collection,list,array
Employee getEmp(List<Integer> ids)
取值:取出第一个id的值 #{list[0]}
总结:参数多时封装成map,结合@Param指定封装时使用的key,#{key}取出map中的值
05 #{}和${}的区别
#{}:是以预编译的形式,即占位符,将参数设置到sql语句中,类似于JDBC中的PreparedStament,防止sql注入
${}:取出的值直接拼装在sql语句中,会有安全问题。
原生JDBC中不支持占位符的地方就可以用${取值},比如表名、排序字段等
select * from ${year}_salary where …
select * from tbl_employee order by ${name}
5.4 select的结果映射
01 返回的是集合
select语句中resultType写的是集合中元素的类型
//查询所有,返回一个集合
List<Employee> selectAll();
<select id="selectAll" resultType="employee">
select * from tbl_employee
</select>
测试:
List<Employee> employees = mapper.selectAll();
for (Employee employee : employees) {
System.out.println(employee);
}
结果:
Employee{id=1, lastName='张曼玉', email='zhangmanyu@163.com', gender='1'}
Employee{id=3, lastName='wangwu', email='wangwu@126.com', gender='0'}
Employee{id=5, lastName='林青霞', email='lingqingxia@163.com', gender='1'}
Employee{id=6, lastName='Tom', email='tom@126.com', gender='0'}
02 返回一条记录的map
如果想把一条记录的返回值类型封装为map,key值为字段名,value值。则指定resultType为map,查询到的结果会将指定的列映射到Map 的键上,结果映射到值上。
//返回一条记录的map,key是列名,值就是对应的值
Map<String,Object> selectEmpByIdToMap(Integer id);
<!--查询并返回一条记录的map-->
<select id="selectEmpByIdToMap" resultType="map">
select * from tbl_employee where id = #{id}
</select>
测试:
Map<String, Object> map = mapper.selectEmpByIdToMap(1);
System.out.println(map);
结果:
{gender=1, last_name=张曼玉, id=1, email=zhangmanyu@163.com}
03 多条记录封装为map
如果想封装多条记录到map中,key是主键值,value是JavaBean对象,则在接口方法上使用@MapKey注解指定key的属性; resultType依然为map中的value类型
//返回多条记录封装到map中,key是主键值,value是JavaBean对象
//@MapKey;指定返回的map的key
@MapKey("id")
Map<Integer,Employee> selectAllToMap();
<!-- 返回多条记录封装到map中,key是主键值,value是JavaBean对象-->
<select id="selectAllToMap" resultType="employee">
select *
from tbl_employee
</select>
测试:
Map<Integer, Employee> map = mapper.selectAllToMap();
System.out.println(map);
结果:
{1=Employee{id=1, lastName='张曼玉', email='zhangmanyu@163.com', gender='1'}, 3=Employee{id=3, lastName='wangwu', email='wangwu@126.com', gender='0'}, 5=Employee{id=5, lastName='林青霞', email='lingqingxia@163.com', gender='1'}, 6=Employee{id=6, lastName='Tom', email='tom@126.com', gender='0'}}
而指定 resultType 属性为实体类时,查询到的结果会将指定的列映射到类的成员变量名上,结果映射到成员变量值上。
【注意】:实体类中的属性名和数据库中的字段名保持一致。否则结果值会为null。
如果列名和属性名不能匹配上,且不满足驼峰命名自动映射,可以在 SELECT 语句中设置列别名,也可以显式配置 ResultMap
04 自定义ResultMap
如果列名和属性名不能匹配上,在xml映射文件中显式配置 ResultMap标签
- type:自定义规则的Java类型
- id:唯一id,用于引用
- column:指定数据库中的字段
- property:指定对应的JavaBean中的属性
<!--自定义结果集规则-->
<!--type:自定义规则的Java类型-->
<!--id:唯一id,用于引用-->
<resultMap id="MyEmp" type="employee">
<!--用id标签定义主键底层会有优化,普通列用result标签-->
<!--column:指定哪一列-->
<!--property:指定对应的JavaBean属性-->
<!--不指定的列会自动封装-->
<id column="id" property="id"/>
<result column="last_name" property="lastName"/>
<result column="email" property="email"/>
<result column="gender" property="gender"/>
</resultMap>
<!--用resultMap取代resultType,值为自命名的id-->
<select id="selectEmp" resultMap="MyEmp">
select *
from tbl_employee
where id = #{id}
</select>
6. association–多对一查询
处理多表查询。
MyBatis 有两种不同的方式加载关联:
- 嵌套 Select 查询:通过执行另外一个 SQL 映射语句来加载期望的复杂类型。
- 嵌套结果映射:使用嵌套的结果映射来处理连接结果的重复子集。
6.1 测试环境
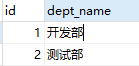
两张表,员工表tbl_employee和部门表tbl_dept,员工表中设置外键部门id,指向部门表的主键
在之前的基础上新建了部门表,并在员工表中设置外键,插入数据:
CREATE TABLE tbl_dept(
id INT(10) PRIMARY KEY AUTO_INCREMENT,
dept_name VARCHAR(255)
)ENGINE=INNODB DEFAULT CHARSET=UTF8;
ALTER TABLE tbl_employee ADD COLUMN d_id INT(10);
ALTER TABLE tbl_employee ADD CONSTRAINT fk_emp_dept FOREIGN KEY(d_id) REFERENCES tbl_dept(id);
员工表:

部门表:
Employee实体类:
public class Employee {
private Integer id;
private String lastName;
private String email;
private String gender;
private Dept dept;
//getter/setter...
}
Dept实体类:
public class Dept {
private Integer id;
private String departmentName;
//getter/setter...
}
6.2 级联属性封装结果
在接口文件中声明一个根据员工id查询员工信息的方法,因为员工信息中一个成员是部门对象,按照之前的映射关系,无法查询部门信息。
public interface EmployeeMapper {
//根据id查询员工的信息及其部门信息
Employee getEmpAndDept(Integer id);
}
采用级联属性来封装结果:
employee中有一个成员是dept,由dept.id和dept.departmentName则可以获取到部门的id和部门名称
<!--联合查询,级联属性封装结果集-->
<resultMap id="MyDifEmp" type="com.xiao.pojo.Employee">
<id column="id" property="id"/>
<result column="last_name" property="lastName"/>
<result column="gender" property="gender"/>
<result column="email" property="email"/>
<result column="did" property="dept.id"/>
<result column="dept_name" property="dept.departmentName"/>
</resultMap>
<select id="getEmpAndDept" resultMap="MyDifEmp ">
<!--给列起别名-->
select e.id id, e.last_name last_name,e.gender gender,e.email email,
d.id did,d.dept_name dept_name from tbl_employee e,tbl_dept d
where e.d_id = d.id and e.id = #{id}
</select>
测试:
Employee employee = mapper.getEmpAndDept(1);
System.out.println(employee);
结果:重点是执行的sql语句
DEBUG 06-12 20:16:45,106 ==> Preparing: select e.id id, e.last_name last_name,e.gender gender,e.email email, d.id did,d.dept_name dept_name from tbl_employee e,tbl_dept d where e.d_id = d.id and e.id = ? (BaseJdbcLogger.java:143)
DEBUG 06-12 20:16:45,213 ==> Parameters: 1(Integer) (BaseJdbcLogger.java:143)
DEBUG 06-12 20:16:45,253 <== Total: 1 (BaseJdbcLogger.java:143)
Employee{id=1, lastName='张曼玉', email='zhangmanyu@163.com', gender='1', dept=Dept{id=1, departmentName='开发部'}}
6.3 association嵌套结果集
关联(association)元素可以处理多表查询。
MyBatis 有两种不同的方式加载关联:
- 嵌套结果映射:使用嵌套的结果映射来处理连接结果的重复子集。
- 嵌套 Select 查询:即分布查询,通过执行另外一个 SQL 映射语句来加载期望的复杂类型。
查询结果本质上是Employee类,其中的成员Dept是对象,需要进行关联association,用javaType获取属性的类型。两种方式结果相同。
<!--查询结果本质上是Employee类-->
<resultMap id="MyDifEmp" type="com.xiao.pojo.Employee">
<!--对查询结果进行映射-->
<!--数据库中的字段取了别名后用别名-->
<id column="id" property="id"/>
<result column="last_name" property="lastName"/>
<result column="gender" property="gender"/>
<result column="email" property="email"/>
<!-- dept成员是一个对象,需要用association指定联合的JavaBean对象-->
<!-- property="dept":指定哪个属性是联合的对象-->
<!-- javaType:指定这个属性对象的类型,不能省略-->
<association property="dept" javaType="com.xiao.pojo.Dept">
<id column="did" property="id"/>
<id column="dept_name" property="departmentName"/>
</association>
</resultMap>
<select id="getEmpAndDept" resultMap="MyDifEmp">
<!--给列起别名-->
select e.id id, e.last_name last_name,e.gender gender,e.email email,
d.id did,d.dept_name dept_name from tbl_employee e,tbl_dept d
where e.d_id = d.id and e.id = #{id}
</select>
6.4 association分步查询
思路:
- 先根据输入的员工id查询员工信息
- 再根据查询到的员工信息中的d_id,查询对应的部门信息
- 将部门信息设置给员工
<!--association分步查询-->
<!--第一步,先查询员工信息-->
<!--第二步,根据查询到的员工信息的did,寻找对应的部门信息-->
<select id="getEmpAndDept" resultMap="MyDifEmp">
<!--第一步,先查询员工信息-->
select id, last_name, gender,email,d_id from tbl_employee where id = #{id}
</select>
<resultMap id="MyDifEmp" type="com.xiao.pojo.Employee">
<!--简单的属性直接写-->
<id column="id" property="id"/>
<result column="last_name" property="lastName"/>
<result column="gender" property="gender"/>
<result column="email" property="email"/>
<!--复杂的属性,需要单独处理-->
<!--select:调用指定的方法查出结果-->
<!--column:将哪一列的值传给这个方法-->
<!--property:查出的结果封装给property指定的属性-->
<association property="dept" column="d_id" javaType="com.xiao.pojo.Dept" select="getDept"/>
</resultMap>
<!--第二步,根据查询到的员工信息中的d_id,查询对应的部门信息-->
<!--可以写到部门的sql映射文件中,这里简略了-->
<select id="getDept" resultType="com.xiao.pojo.Dept">
select id,dept_name departmentName from tbl_dept where id = #{d_id}
</select>
association标签中的属性:
- select:调用指定的方法查出结果
- column:将哪一列的值传给这个方法
- property:查出的结果封装给property指定的属性
执行流程:使用select指定的方法,用传入的column指定的这列参数的值,查出对象,并封装给property属性
结果:有两条sql语句
DEBUG 06-12 20:04:49,831 ==> Preparing: select id, last_name, gender,email,d_id from tbl_employee where id = ? (BaseJdbcLogger.java:143)
DEBUG 06-12 20:04:49,945 ==> Parameters: 1(Integer) (BaseJdbcLogger.java:143)
DEBUG 06-12 20:04:50,006 ====> Preparing: select id,dept_name departmentName from tbl_dept where id = ? (BaseJdbcLogger.java:143)
DEBUG 06-12 20:04:50,008 ====> Parameters: 1(Integer) (BaseJdbcLogger.java:143)
DEBUG 06-12 20:04:50,015 <==== Total: 1 (BaseJdbcLogger.java:143)
DEBUG 06-12 20:04:50,017 <== Total: 1 (BaseJdbcLogger.java:143)
Employee{id=1, lastName='张曼玉', email='zhangmanyu@163.com', gender='1', dept=Dept{id=1, departmentName='开发部'}}
分步查询可以使用延迟加载
延迟加载(懒加载、按需加载),需要在全局配置文件中开启
- lazyLoadingEnabled:延迟加载的全局开关。当开启时,所有关联对象都会延迟加载。 特定关联关系中可通过设置
fetchType 属性来覆盖该项的开关状态。默认是false
- aggressiveLazyLoading:开启时,任一方法的调用都会加载该对象的所有延迟加载属性。 否则,每个延迟加载属性会按需加载。(在 3.4.1 及之前的版本中默认为 true,之后默认为false)
<settings>
<!--开启懒加载-->
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="aggressiveLazyLoading" value="false"/>
</settings>
测试中只使用查询到的员工信息,不使用员工信息,则只会发出一条sql语句,如果不开启延迟加载,则总是会发出两条sql语句:
Employee employee = mapper.getEmpAndDept(1);
System.out.println(employee.getEmail());
结果,只发出了第一步的sql语句:
DEBUG 06-12 20:31:55,182 ==> Preparing: select id, last_name, gender,email,d_id from tbl_employee where id = ? (BaseJdbcLogger.java:143)
DEBUG 06-12 20:31:55,290 ==> Parameters: 1(Integer) (BaseJdbcLogger.java:143)
DEBUG 06-12 20:31:55,516 <== Total: 1 (BaseJdbcLogger.java:143)
zhangmanyu@163.com
7 collection–一对多查询
查询部门,并讲部门对应的所有员工信息查询出来
public class Employee {
private Integer id;
private String lastName;
private String email;
private String gender;
//getter/setter...
}
Dept实体类:
public class Dept {
private Integer id;
private String departmentName;
private List<Employee> emps;
//getter/setter...
}
DeptMapper接口文件:
public interface DeptMapper {
Dept selectDeptById(Integer id);
}
7.1 嵌套结果集
使用关联查询,根据Dept的id查询Dept信息,其中Dept中有一个成员是emps,即员工的集合,需要用到collection标签进行结果映射。
集合标签:collection
- property:指定哪个属性是集合
- ofType:获取集合中的泛型信息
sql映射文件:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xiao.dao.DeptMapper">
<!--嵌套结果查询-->
<select id="selectDeptById" resultMap="MyDept">
select d.id did, d.dept_name dept_name, e.id eid, e.last_name last_name, e.email email, e.gender gender
from tbl_dept d
left join tbl_employee e
on d.id = e.d_id
where d.id = #{id}
</select>
<resultMap id="MyDept" type="com.xiao.pojo.Dept">
<id column="did" property="id"/>
<result column="dept_name" property="departmentName"/>
<!--复杂的属性,单独处理,集合:collection,property指定哪个属性是集合,用ofType获取集合中的泛型信息-->
<collection property="emps" ofType="com.xiao.pojo.Employee">
<result column="eid" property="id"/>
<result column="last_name" property="lastName"/>
<result column="email" property="email"/>
<result column="gender" property="gender"/>
</collection>
</resultMap>
</mapper>
测试:
Dept dept = mapper.selectDeptById(1);
System.out.println(dept);
查询结果,一个部门中有两个员工信息:
DEBUG 06-12 21:24:02,595 ==> Preparing: select d.id did, d.dept_name dept_name, e.id eid, e.last_name last_name, e.email email, e.gender gender from tbl_dept d left join tbl_employee e on d.id = e.d_id where d.id = ? (BaseJdbcLogger.java:143)
DEBUG 06-12 21:24:02,675 ==> Parameters: 1(Integer) (BaseJdbcLogger.java:143)
DEBUG 06-12 21:24:02,721 <== Total: 2 (BaseJdbcLogger.java:143)
Dept{id=1, departmentName='开发部', emps=[Employee{id=1, lastName='张曼玉', email='zhangmanyu@163.com', gender='1'}, Employee{id=3, lastName='wangwu', email='wangwu@126.com', gender='0'}]}
7.2 分步查询
思路与多对一中的思路类型:
- 先根据输入的部门id查询部门信息
- 再根据查询到的部门信息中的部门id,查询对应的员工信息
- 将员工信息设置给部门
<!--分步查询-->
<select id="selectDeptById" resultMap="MyDept">
select id, dept_name
from tbl_dept
where id = #{id}
</select>
<resultMap id="MyDept" type="com.xiao.pojo.Dept">
<id column="id" property="id"/>
<result column="dept_name" property="departmentName"/>
<collection property="emps" ofType="com.xiao.pojo.Employee" select="getEmp" column="id"/>
</resultMap>
<select id="getEmp" resultType="com.xiao.pojo.Employee">
select id,last_name lastName,email,gender from tbl_employee where d_id = #{id}
</select>
7.3 补充几个小点
-
分步查询如何传递多列的值?
将多列的值封装成map传递:column={key1=column1,key2=column2…},使用时则用#{key}获取
-
开启了全局懒加载后,特定关联关系中可通过设置 fetchType 属性来覆盖该项的开关状态
- fetchType=“lazy”:懒加载
- fetchType=“eager”:立即加载
-
鉴别器discriminator
类似于 Java 语言中的 switch 语句,可以根据不同的条件封装不同的结果集。需要指定 column 和 javaType 属性。
- javaType:列值对应的java类型
- column:指定用于判定的列名
- value:进行条件的判断,满足该条件,则选择该结果封装规则
<discriminator javaType="string" column="gender">
<case value="0" resultType="com.xiao.pojo.Employee">
....
</case>
<case value="0" resultType="com.xiao.pojo.Employee">
....
</case>
</discriminator>