与Kudu相比,Kudu是一个支持OLTP workload的数据存储系统,而Hudi的设计目标是基于Hadoop兼容的文件系统(如HDFS、S3等),重度依赖Spark的数据处理能力来实现增量处理和丰富的查询能力,Hudi支持Incremental Pulling而Kudu不支持。 Hudi能够整合Batch和Streaming处理的能力,这是通过利用Spark自身支持的基本能力来实现的。一个数据处理Pipeline通常由Source、Processing、Sink三个部分组成,Hudi可以作为Source、Sink,它把数据存储到分布式文件系统(如HDFS)中。Apache Hudi在大数据应用场景中,所处的位置,如下图所示:
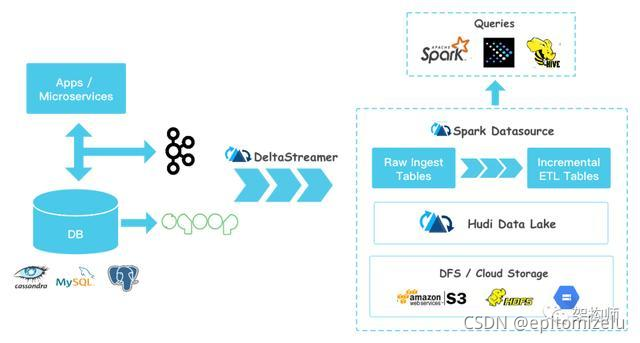
从上图中可见,Hudi能够与Hive、Spark、Presto这类处理引擎一起工作。Hudi有自己的数据表,通过将Hudi的Bundle整合进Hive、Spark、Presto等这类引擎中,使得这些引擎可以查询Hudi表数据,从而具备Hudi所提供的Snapshot Query、Incremental Query、Read Optimized Query的能力。