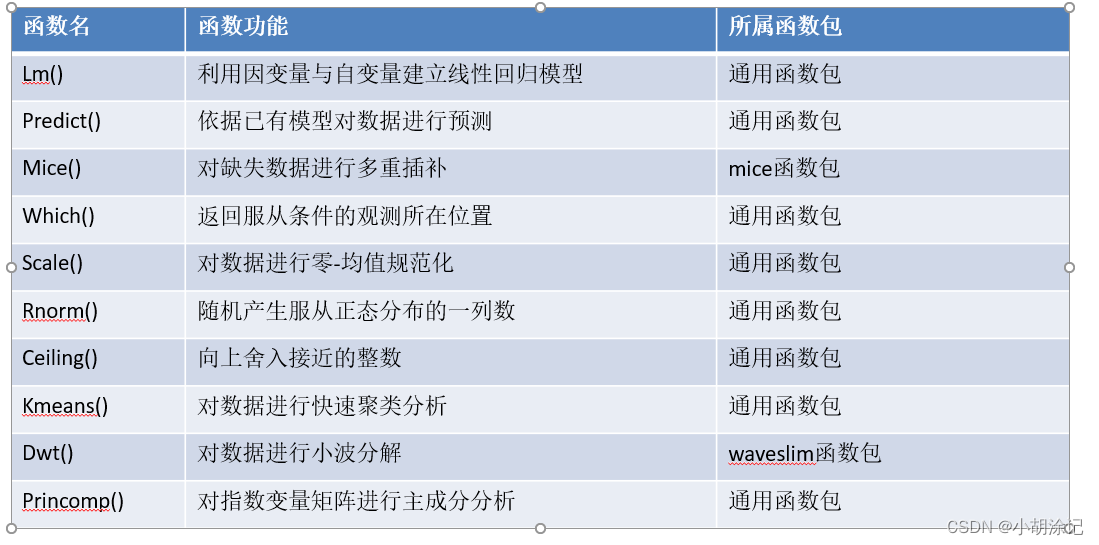
缺失值处理 :使用is.na()判断缺失值是否存在,complete.cases()可以识别样本数据是否完整从而判断缺失情况。删除法 (na.omit()函数移除所有含有缺失数据的行,data[ ,-p]删除p列)、替换法 (均值、中位数、众数替换)、插补法 (用lm()回归预测补缺,用mice函数包进行多重插补,思想是生成数据组的随机数),插值有很多方法主要有拉格朗日法和牛顿法,之前在非参数统计中有看到许多。
# 设置工作空间
# 把“数据及程序”文件夹拷贝到F盘下,再用setwd设置工作空间
setwd( "F:/数据及程序/chapter4/示例程序" )
# 读取销售数据文件,提取标题行
inputfile <- read.csv( './data/catering_sale.csv' , header = TRUE )
# 变换变量名
inputfile <- data.frame( sales = inputfile$ '销量' , date = inputfile$ '日期' )
# 数据截取
inputfile <- inputfile[ 5 : 16 , ]
# 缺失数据的识别
is.na( inputfile) # 判断是否存在缺失
n <- sum( is.na( inputfile) ) # 输出缺失值个数
# 异常值识别
par( mfrow = c( 1 , 2 ) ) # 将绘图窗口划为1行两列,同时显示两图
dotchart( inputfile$ sales) # 绘制单变量散点图
boxplot( inputfile$ sales, horizontal = TRUE ) # 绘制水平箱形图
# 异常数据处理
inputfile$ sales[ 5 ] = NA # 将异常值处理成缺失值
fix( inputfile) # 表格形式呈现数据
# 缺失值的处理
inputfile$ date <- as.numeric( inputfile$ date) # 将日期转换成数值型变量
sub <- which( is.na( inputfile$ sales) ) # 识别缺失值所在行数
inputfile1 <- inputfile[ - sub, ] # 将数据集分成完整数据和缺失数据两部分
inputfile2 <- inputfile[ sub, ]
# 行删除法处理缺失,结果转存
result1 <- inputfile1
# 均值替换法处理缺失,结果转存
avg_sales <- mean( inputfile1$ sales) # 求变量未缺失部分的均值
inputfile2$ sales <- rep( avg_sales, n) # 用均值替换缺失
result2 <- rbind( inputfile1, inputfile2) # 并入完成插补的数据
# 回归插补法处理缺失,结果转存
model <- lm( sales ~ date, data = inputfile1) # 回归模型拟合
inputfile2$ sales <- predict( model, inputfile2) # 模型预测
result3 <- rbind( inputfile1, inputfile2)
# 多重插补法处理缺失,结果转存
library( lattice) # 调入函数包
library( MASS)
library( nnet)
library( mice) # 前三个包是mice的基础
imp <- mice( inputfile, m = 4 ) # 4重插补,即生成4个无缺失数据集
fit <- with( imp, lm( sales ~ date, data = inputfile) ) # 选择插补模型
pooled <- pool( fit)
summary( pooled)
result4 <- complete( imp, action = 3 ) # 选择第三个插补数据集作为结果
将多个数据集合并,R中用merge()函数实现。
简单函数变换 :平方(
x
′
=
x
2
x'=x^2
x ′ = x 2
x
′
=
x
x'=\sqrt{x}
x ′ = x
x
′
=
log
(
x
)
x'=\log(x)
x ′ = log ( x )
▽
f
(
x
k
)
=
f
(
x
k
+
1
)
−
f
(
x
k
)
\bigtriangledown f(x_k)=f(x_{k+1})-f(x_k)
▽ f ( x k ) = f ( x k + 1 ) − f ( x k ) 规范化 :最小-最大规范化(
x
∗
=
x
−
m
i
n
m
a
x
−
m
i
n
x*=\frac{x-min}{max-min}
x ∗ = ma x − min x − min
x
∗
=
x
−
x
ˉ
σ
x*=\frac{x-\bar x}{\sigma}
x ∗ = σ x − x ˉ
x
∗
=
x
1
0
k
x*=\frac{x}{10^k}
x ∗ = 1 0 k x
# 设置工作空间
# 把“数据及程序”文件夹拷贝到F盘下,再用setwd设置工作空间
setwd( "F:/数据及程序/chapter4/示例程序" )
# 读取数据
data <- read.csv( './data/normalization_data.csv' , header = FALSE )
# 最小-最大规范化
b1 <- ( data[ , 1 ] - min( data[ , 1 ] ) ) / ( max( data[ , 1 ] ) - min( data[ , 1 ] ) )
b2 <- ( data[ , 2 ] - min( data[ , 2 ] ) ) / ( max( data[ , 2 ] ) - min( data[ , 2 ] ) )
b3 <- ( data[ , 3 ] - min( data[ , 3 ] ) ) / ( max( data[ , 3 ] ) - min( data[ , 3 ] ) )
b4 <- ( data[ , 4 ] - min( data[ , 4 ] ) ) / ( max( data[ , 4 ] ) - min( data[ , 4 ] ) )
data_scatter <- cbind( b1, b2, b3, b4)
# 零-均值规范化
data_zscore <- scale( data)
# 小数定标规范化
i1 <- ceiling( log( max( abs( data[ , 1 ] ) ) , 10 ) ) # 小数定标的指数
c1 <- data[ , 1 ] / 10 ^ i1
i2 <- ceiling( log( max( abs( data[ , 2 ] ) ) , 10 ) )
c2 <- data[ , 2 ] / 10 ^ i2
i3 <- ceiling( log( max( abs( data[ , 3 ] ) ) , 10 ) )
c3 <- data[ , 3 ] / 10 ^ i3
i4 <- ceiling( log( max( abs( data[ , 4 ] ) ) , 10 ) )
c4 <- data[ , 4 ] / 10 ^ i4
data_dot <- cbind( c1, c2, c3, c4)
# 打印结果
options( digits = 4 ) # 控制输出结果的有效位数
data; data_scatter; data_zscore; data_dot
连续属性离散化 :等宽法、等频法、(一维)聚类。
# 设置工作空间
# 把“数据及程序”文件夹拷贝到F盘下,再用setwd设置工作空间
setwd( "F:/数据及程序/chapter4/示例程序" )
# 读取数据文件,提取标题行
data <- read.csv( './data/discretization_data.csv' , header = TRUE )
# 等宽离散化
v1 <- ceiling( data[ , 1 ] * 10 )
# 等频离散化
names( data) <- 'f' # 变量重命名
attach( data)
seq( 0 , length( f) , length( f) / 6 ) # 等频划分为6组
v <- sort( f) # 按大小排序作为离散化依据
v2 <- rep( 0 , 930 ) # 定义新变量
for ( i in 1 : 930 ) {
v2[ i] <- ifelse ( f[ i] <= v[ 155 ] , 1 ,
ifelse ( f[ i] <= v[ 310 ] , 2 ,
ifelse ( f[ i] <= v[ 465 ] , 3 ,
ifelse ( f[ i] <= v[ 620 ] , 4 ,
ifelse ( f[ i] <= v[ 775 ] , 5 , 6 ) ) ) ) )
}
detach( data)
# 聚类离散化
result <- kmeans( data, 6 )
v3 <- result$ cluster
# 图示结果
plot( data[ , 1 ] , v1, xlab = '肝气郁结证型系数' )
plot( data[ , 1 ] , v2, xlab = '肝气郁结证型系数' )
plot( data[ , 1 ] , v3, xlab = '肝气郁结证型系数' )
属性构造 :构造中间变量或者虚拟变量。小波变换 :具有多分辨率的特点,在时域 和频域 都有表征信号局部特征的能力。
# 数据生成,信号模拟
N <- 1024 ; k <- 6 # 参数赋值
x <- ( ( 1 : N) - N/ 2 ) * 2 * pi * k / N
y <- ifelse( x > 0 , sin( x) , sin( 3 * x) ) # 划分低频波动段和高频波动段
signal <- y + rnorm( N) / 10 # 添加扰动项,生成信号变量
# 调用函数包
library( waveslim)
# 对信号z进行小波分解
d <- dwt( signal, n.levels = 4 )
# 输出各层小波系数
data.frame( d$ d1, d$ d2, d$ d3, d$ d4)
寻找出最小的属性子集并确保新数据子集的概率分布尽可能地接近原来数据集的概率分布。属性规约 :合并属性、向前向后法、决策树归纳、主成分分析。
# 设置工作空间
# 把“数据及程序”文件夹拷贝到F盘下,再用setwd设置工作空间
setwd( "F:/数据及程序/chapter4/示例程序" )
# 数据读取
inputfile <- read.csv( './data/principal_component.csv' , header = FALSE )
# 主成分分析
PCA <- princomp( inputfile, cor = FALSE )
names( PCA) # 查看输出项
( PCA$ sdev) ^ 2 # 主成分特征根
summary( PCA) # 主成分贡献率
PCA$ loadings # 主成分载荷
PCA$ scores # 主成分得分
数值规约 :直方图、聚类、抽样、参数回归。