基于多尺度深度网络的单幅图像深度估计
原文地址:http://blog.csdn.net/hjimce/article/details/50569474
作者:hjimce
一、相关理论
本篇博文主要讲解来自2014年NIPS上的一篇paper:《Depth Map Prediction from a Single Image using a Multi-Scale Deep Network》,属于CNN应用类别的文章,主要是利用卷积神经网络进行单幅图像的深度估计。我们拍照的时候,把三维的图形,投影到二维的平面上,形成了二维图像。而深度估计的目的就是要通过二维的图片,估计出三维的信息,是一个逆过程,这个在三维重建领域相当重要。
这个如果是利用多张不同视角的图片进行三维重建,会比较简单,研究的也比较多,比如:立体视觉。然而仅仅从一张图片进行三维深度估计,确实是一个很艰难的事。因为从三维到二维,肯定会丢失掉物体的深度值;因此从二维到三维本来就是一个信息缺失的、不可逆过程。然而大牛们依旧想方设法去尝试估计深度值,其中比较牛逼的算法当属Make3D,不过再牛逼的算法也是那样,因为本来就是一个信息缺失的问题,所以深度估计的精度,依旧很烂。
然而本篇paper,通过深度学习的方法,从大量的训练数据中,进行学习,一口气提高了35%的相对精度,超出了传统方法十几条街。这个就像我们人一样,我们看一张照片中的物体的时候,虽然深度信息缺失,但是我们依旧可以估计它的形状,这是因为我们的脑海中,保存了无数的物体,有丰富的先验知识,可以结合这些先验,对一张图片中的物体做出形状估计。利用深度学习进行一张图片的深度估计,也是差不多一样的道理,通过在大量的训练数据上,学习先验知识,最后就可以把精度提高上去。
有点啰嗦了,回归正题吧,估计都等得不耐烦了,我们下面开始讲解文献:《Depth Map Prediction from a Single Image using a Multi-Scale Deep Network》的算法原理,及其实现。
二、网络总体架构
先贴一下,网络架构图:
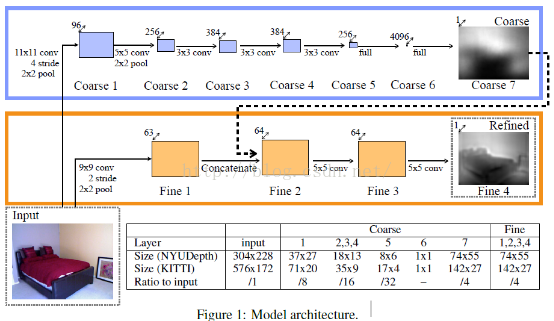
网络分为全局粗估计和局部精估计,这个跟人脸特征点的DCNN网络有点类似,都属于deep network。全局粗估计CNN:这个网络包含了五个特征提取层(每层包好了卷积、最大池化操作),在这五个卷积层后面,有链接了两个全连接层,我们最后的输出图片的宽高变为原来的1/4。
不管是粗还是精网络,两个网络的输入图片是一样的,输出图片的大小也是一样的。对于粗网络和精网络的训练方法,paper采用的方法是,先训练粗网络,训练完毕后,固定粗网络的参数,然后在训练精网络,这个与另外一篇paper:《Predicting Depth, Surface Normals and Semantic Labels》的训练方法不同,这篇paper前面两个scale的训练是一起训练的,参数一起更新。
三、coarse的网络结构
网络结构方面,基本上是模仿Alexnet的,具体可以看一下,上面的表格。我们以NYU数据集上,为例,进行下面网络结构讲解。
1、输入图片:图片大小为304*228
2、网络第一层:卷积核大小为11*11,卷积跨步大小为4,卷积后图片大小为[(304-11)/4+1,(228-11)/4+1]=[74,55],特征图个数为96,即filter_shape = (96, 3, 11, 11)。池化采用最大重叠池化size=(3,3),跨步为2。因此网络输出图片的大小为:[74/2,55/2]=[37,27]。为了简单起见,我们结合文献作者给的源码进行讲解,paper主页:http://www.cs.nyu.edu/~deigen/depth/,作者提供了训练好的模型,demo供我们测试,训练部分的源码没有提供,后面博文中贴出的源码均来自于paper的主页。本层网络的相关参数如下:
[imnet_conv1]
type = conv
load_key = imagenet
filter_shape = (96, 3, 11, 11)
stride = 4
conv_mode = valid
init_w = lambda shp: 0.01*np.random.randn(*shp)
learning_rate_scale_w = 0.001
learning_rate_scale_b = 0.001
weight_decay_w = 0.0005
[imnet_pool1]
type = maxpool
load_key = imagenet
poolsize = (3,3)
poolstride = (2,2)
3、网络第二层
:卷积核大小为5*5,卷积跨步为1,接着进行最大重叠池化,得到图片大小为[18,13](需要加入pad)。网络结构设计方面可以参考Alexnet网络。源码如下:
[imnet_conv2]
type = conv
load_key = imagenet
filter_shape = (256, 96, 5, 5)
conv_mode = same
stride = 1
init_w = lambda shp: 0.01*np.random.randn(*shp)
learning_rate_scale_w = 0.001
learning_rate_scale_b = 0.001
weight_decay_w = 0.0005
[imnet_pool2]
type = maxpool
load_key = imagenet
poolsize = (3,3)
poolstride = (2,2)
4、细节方面
:除了网络的最后一层输出层之外,其它的激活函数都是采用Relu函数。因为最后一层是线性回归问题,因此最后一层的激活函数应该是线性函数。在全连接层layer6,采用Dropout。
5、参数初始化:参数初始化,采用迁移学习的思想,直接把Alexnet的网络训练好的参数的前面几层拿过来,进行fine-tuning。文章提到,采用fine-tuning的方法,效果会比较好。通过阅读源码可以判断,paper除了全连接层之外,粗网络卷积层的参数都是利用Alexnet进行fine-tuning。
四、精细化网络结构-Fine scale Network
精网络的结构,采用的是全连接卷积神经网络,也就是不存在全连接层,这个如果搞过FCN语义分割的,应该会比较明白。这个网络包含了三个卷积层。
通过上面粗网络的深度值预测,我们得到的深度图是比较模糊的,基本上没有什么边缘信息,接着接着我们需要精细化,使得我们的深度预测图与图像的边缘等信息相吻合,因为一个物体的边缘,也就是相当于深度值发生突变的地方,因此我们预测出来的深度值图像也应该是有边缘的。从粗到精的思想就像文献《Deep Convolutional Network Cascade for Facial Point Detection》,从粗估计到精预测的过程一样,如果你之前已经搞过coarse to refine 相关的网络的话,那么学习这篇文献会比较容易。为了简单起见,我这边把本层网络称之为:精网络。精网络的结构如下:
1、输入层:304*228 大小的彩色图片
2、第一层:输入原始图片,第一层包含卷积、RELU、池化。卷积核大小为9*9,卷积跨步选择2,特征图个数选择64个(这个文献是不是中的图片是不是错了,好像标的是63),即:filter_shape = (64,3,9,9)。最大池化采用重叠池化采样size=(3,3),跨步选择2,即poolsize = (3,3),poolstride = (2,2)。这一层主要用于提取边缘特征。因为我们通过粗网络的输出可以看出,基本上没有了边缘信息,因此我们需要利用精网络,重构这些边缘信息。本层网络的相关参数:
[conv_s2_1]
type = conv
load_key = fine_stack
filter_shape = (64,3,9,9)
stride = 2
init_w = lambda shp: 0.001*np.random.randn(*shp)
init_b = 0.0
conv_mode = valid
weight_decay_w = 0.0001
learning_rate_scale_w = 0.001
learning_rate_scale_b = 0.001
[pool_s2_1]
type = maxpool
poolsize = (3,3)
poolstride = (2,2)
经过卷积层,我们可以得到大小为(110*148)的图片,然后在进行pooling,就可以得到55*74的图片了。这样经过这一层,我们就得到了与粗网络的输出大小相同的图片了。
3、第二层:这一层的输入,除了第一层得到的特征图外,同时还额外添加了粗网络的输出图(作为特征图,加入网络输入)。
网络细节基本和粗网络相同,这里需要注意的是,我们训练网络的时候,是先把粗网络训练好了,然后在进行训练精网络,精网络训练过程中,粗网络的参数是不用迭代更新的。DCNN的思想都是这样的,如果你有看了我的另外一篇关于特征点定位的博文DCNN,就知道怎么训练了。
还有我们这一层的输入图片的大小,已经和输出层所要求的大小一样了,因此后面卷积的时候,卷积要保证图片大小还是一样的。
[conv_s2_2]
type = conv
load_key = fine_stack
filter_shape = (64,64,5,5)
init_w = lambda shp: 0.01*np.random.randn(*shp)
init_b = 0.0
conv_mode = same
weight_decay_w = 0.0001
learning_rate_scale_w = 0.01
learning_rate_scale_b = 0.01
4、第三层
:也就是连接到输出层去
[conv_s2_3]
type = conv
load_key = fine_stack
filter_shape = (64,1,5,5)
transpose = True
init_w = lambda shp: 0.01*np.random.randn(*shp)
init_b = 0.0
conv_mode = same
weight_decay_w = 0.0001
learning_rate_scale_w = 0.001
learning_rate_scale_b = 0.001
五、尺度不变损失函数
这个是文献的主要创新点之一,主要是提出了尺度不变的均方误差函数:
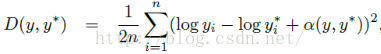
其中y和y*就是我们的图片标注数据和预测数据了,本文指的是每个像素点的实际的深度值和预测的深度值。α的计算公式如下:
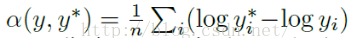
根据上面定义的损失函数,paper训练过程中采用如下的损失函数:

其中参数λ取值为0.5。具体的源码如下:
#定义损失函数 缩放不变损失函数,pred预测值,y0标准值、m0为mask(为0表示无效点,为1表示有效点)
def define_cost(self, pred, y0, m0):
bsize = self.bsize
npix = int(np.prod(test_shape(y0)[1:]))
y0_target = y0.reshape((self.bsize, npix))
y0_mask = m0.reshape((self.bsize, npix))
pred = pred.reshape((self.bsize, npix))
#因为在mask中,所有的无效的像素点的值都为0,所以p、t中对应的像素点的值也为0,这样我们的损失函数,这些像素点的值也为0,对参数不起更新作用
p = pred * y0_mask
t = y0_target * y0_mask
d = (p - t)
nvalid_pix = T.sum(y0_mask, axis=1)#这个表示深度值有效的像素点
#文献中公式4 ,参数λ取值为0.5.公式采用的是简化为(n×sum(d^2)-λ*(sum(d))^2)/(n^2)
depth_cost = (T.sum(nvalid_pix * T.sum(d**2, axis=1))
- 0.5*T.sum(T.sum(d, axis=1)**2)) \
/ T.maximum(T.sum(nvalid_pix**2), 1)
return depth_cost
六、数据扩充
1、缩放:缩放比例s取(1,1.5),因为缩放深度值并不是不变的,所以文献采用把深度值对应的也除以比例s。(这一点我有点不明白,难道一张图片拍好了,我们把它放大s倍,那么会相当于摄像头往物体靠近了s倍进行拍照吗?这样解释的,让我有点想不通)。
2、旋转数据扩充,这个比较容易
3、数据加噪扩充:主要是把图片的每个像素点的值,乘以一个(0.8,1.2)之间的随机数。
4、镜像数据扩充,用0.5的概率,对数据进行翻转。
5、随机裁剪扩充,跟Alexnet一样。
在测试阶段,采用中心裁剪的方式,和Alexnet的各个角落裁剪后平均有所不同。
七、训练相关细节
这边我只讲解NYU数据集上的训练。NYU训练数据可以自己网上下载,NYU原始的数据中,每张图片的每个像素点label、depth值,其中label是物体标签,主要用于图像分割,后面paper的作者也发表了一篇关于语意分割、法矢估计的文献:《Predicting Depth, Surface Normals and Semantic Labels》。
NYU原始的训练数据有个特点,就是图片并不是每个像素点都有depth值,这个可能是因为设备采集深度值的时候,会有缺失的像素点。首先NYU数据是640*480的图片,depth也是640*480,因为每个像素点,对应一个深度值嘛,可是这些深度值,有的像素点是无效的,有效和无效的像素点我们可以用一个mask表示。那么我们如何进行训练呢?
我们知道网络采用的是对320*240的图片,进行random crop的,因此首先我们需要把image、depth、mask都由640*480缩小到320*240。这边需要注意的是这里的缩小,是采用直接下采样的方法,而不是采用线性插值等方法。因为我们需要保证图片每个像素点和depth、mask都是对应的,而不是采用插值的方法,如果采用插值,那么我们的mask就不再是mask了,这个小细节一开始困扰了我好久。还有需要再提醒一下,320*240不是网络的输入大小,我们还要采用random crop,把它裁剪成304*228,这个才是网络的输入。
另一方面就是depth的问题,我们知道我们输出的depth的大小是74*55。而网络输入数据image、depth、mask的大小是304*228,因此我们在构造损失函数,需要把标注数据depth、mask又采用直接下采样的方法缩小到74*55(下采样比例为4),这样才能与网络的输出大小相同,构造损失函数。相关源码如下:
y0 = depths#深度值
m0 = masks#mask
#图片采用的是直接下采样,而不是用双线性插值进行插值得到训练的depths,下采样的比例是4
m0 = m0[:,1::4,1::4]
y0 = y0[:,1::4,1::4]
个人总结:这篇文献的深度估计,文献上面可以说是深度学习领域崛起的一个牛逼应用,相比于传统的方法精度提高了很多。不过即便如此,精度离我们要商用的地步还是有一段的距离要走。从这篇文献我们主要学习到了两个知识点:1、多尺度CNN模型 。2、标注数据部分缺失的情况下,网络的训练,这个文献给了最大的启发就是:在kaggle竞赛上面有个人脸特征点定位,但是有的图片的标注数据,是部分缺失的,这个时候我们就可以借用这篇文献的训练思路,采用mask的方法。3、文献提出了Scale-Invariant损失函数,也是文献的一大创新点。
参考文献:
1、《Depth Map Prediction from a Single Image using a Multi-Scale Deep Network》
2、《Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture》
3、http://www.cs.nyu.edu/~deigen/depth/
4、《Make3d: Learning 3-d scene structure from a single still image》
**********************作者:hjimce 时间:2016.1.23 联系QQ:1393852684 地址:http://blog.csdn.net/hjimce 原创文章,转载请保留本行信息************