概要:首先介绍了切比雪夫不等式,然后介绍大数定律概念和3种大数定律及证明。
切比雪夫不等式
已知随机变量X的期望EX和方差DX,对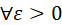 ,可得
,可得 的一个上界。
的一个上界。
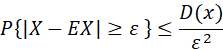

解释:不论X服从什么分布,X在E(x)的ε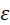 邻域内取值的概率不小于1-Dxε2
邻域内取值的概率不小于1-Dxε2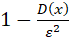 。
。
证明:

本质: 随机变量X偏离E(X)越大,则其概率越小。

若方差越小,随机变量X集中在期望附近的可能性就越大,所以方差刻画了随件变量的离散程度。
随机变量X的分布未知的情况下,只利用X的期望和方差, 即可对X的概率分布进行估计。
大数定律:
依概率收敛:
X1,X2,…,Xn,…是一随机变量序列,如果存在一个常数a,对∀ε>0,总有limn→∞PXn-a<ε=1成立。则称{Xn}依概率收敛于a,记为Xn→a
理解:随机变量Xn在n无穷大的时候无限趋近于常数a。
依概率收敛比普通意义的收敛弱些,具有某种不确定性。
大数定律的客观背景:
在大量随机试验中,事件发生的频率稳定于某一常数,测量值的算术平均值具有稳定性。
大数定律的概念:
当样本数据无限大时,样本均值趋于总体均值。现实生活中,无法进行无穷多次试验,大数定律说用频率近似替代概率,用样本均值近似代替总体均值。
用数学语言表示:
大数定律就是研究随机变量序列在什么条件下, 依概率收敛于0。
依概率收敛于0。
为什么使用求和符号?
样本均值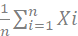
总体均值
切比雪夫大数定律
设随机变量序列{Xn}是相互独立的序列,如果存在常数C,使得 ,则此随机变量序列
,则此随机变量序列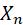 服从大数定律。
服从大数定律。
证明:

伯努利大数定律
设 是
是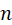 重伯努利试验中事件
重伯努利试验中事件 发生的次数,
发生的次数, ,则对任意
,则对任意 有
有
当伯努利重复试验次数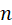 充分大时,事件
充分大时,事件 发生的频率
发生的频率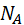 与事件A的概率
与事件A的概率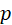 有较大偏差的概率很小。
有较大偏差的概率很小。
证明:

辛钦大数定律
在独立同分布场合,不需要方差的存在
设X1,X2,…,Xn是一个独立同分布的随机变量序列,且E(Xi)=u,则随机变量序列符合大数定律。
将随机变量X独立重复地观察n次, X1,...,Xn相互独立,且与X具有相同的分布。由辛钦大数定律, 可知当n充分大时, 可将n次结果的平均值作为E(X)的近似。