Tokenizer
诸如GPT-3/4以及LlaMA/LlaMA2大语言模型都采用了token的作为模型的输入输出,其输入是文本,然后将文本转为token(正整数),然后从一串token(对应于文本)预测下一个token。
进入OpenAI官网提供的tokenizer可以看到GPT-3tokenizer采用的方法。这里以Hello World为例说明。
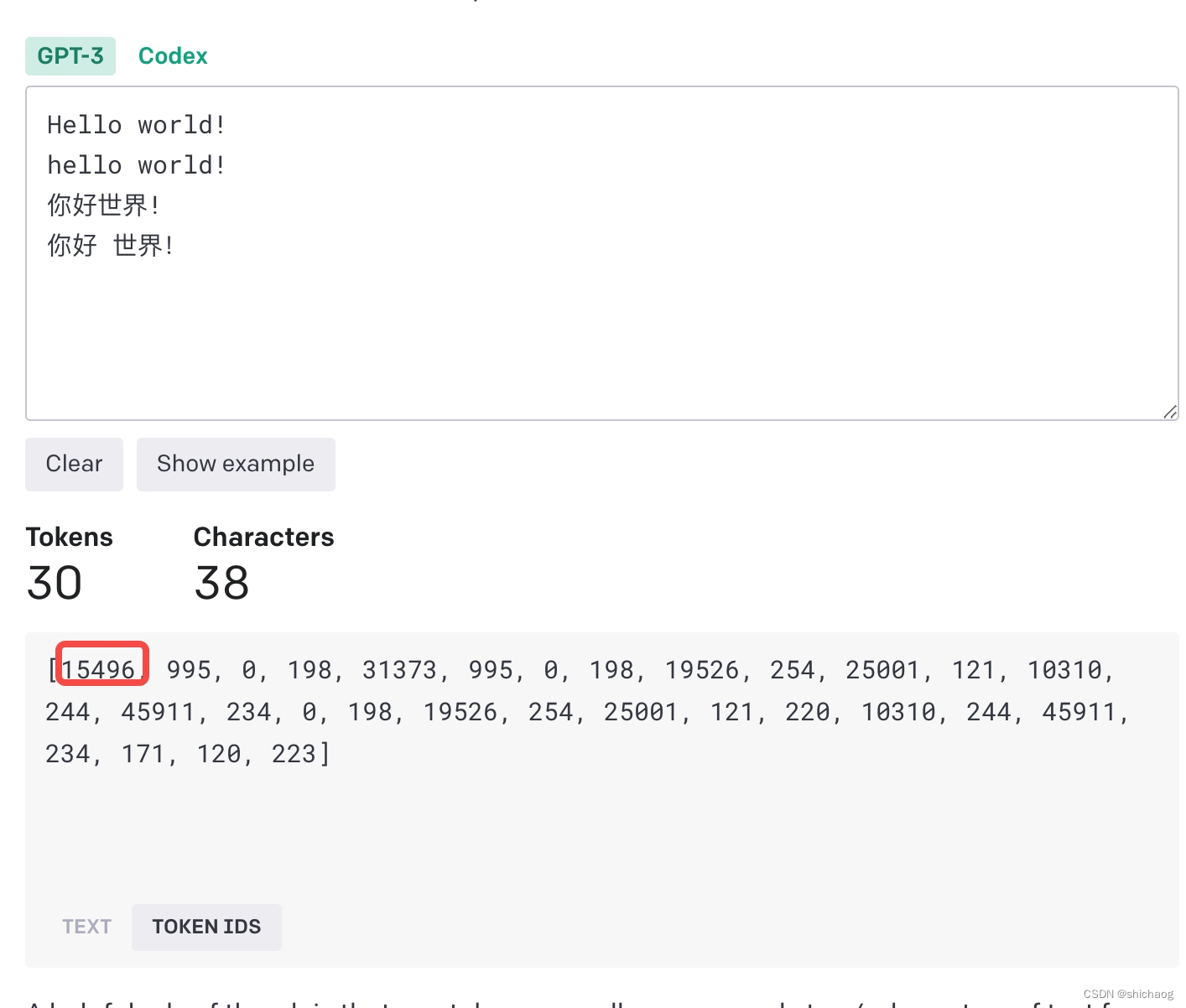
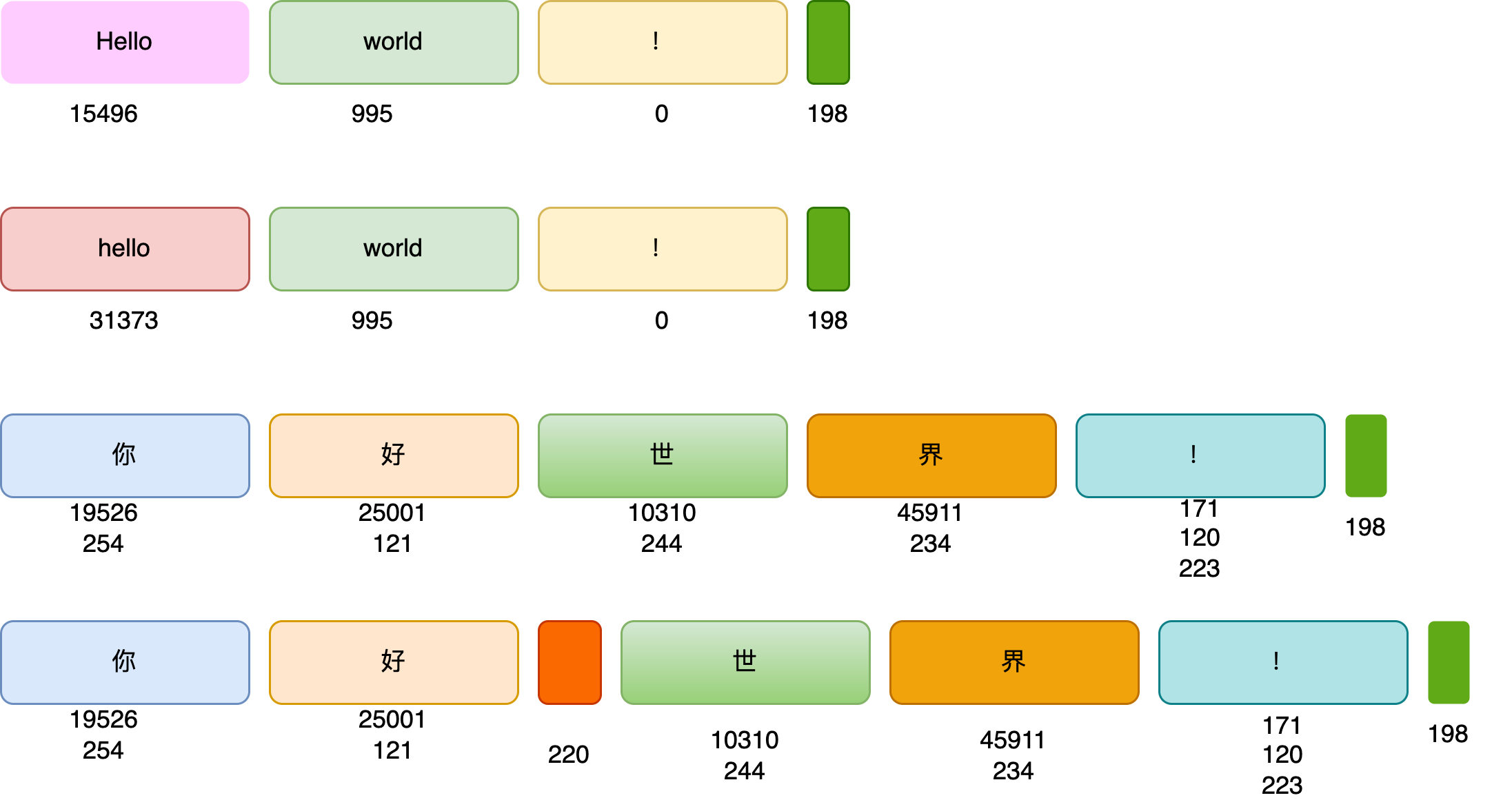
总共30个token,英文单词一般会用单独的token表示,大小写也会区分不同的token,如Hello和hello,另外有一些由空格前导的单词也会单独编码,这会使得编码整个句子效率更高(这将省去每个空格的编码),对于中文token化,会使用两到三个ID(正整数表示),比如上面的中英文的!。
BPE编码算法
Byte Pair Encoding则是大语言模型当前使用最多的Tokenizer方法。一个直观的tokenize的方法是:
将每个单词看成一个token,然后对其编号,这符合人类语言习惯,但这并不是一个高效的编码方式,这是因为一门语言通常有几万到几十万的单词量,而现在的大语言模型都是支持多国的,如果每个单词独立编码,这就需要语言模型在预测的时候从几万到几百万这样规模的词汇表中选择一个(预测这些词的概率情况),这样的计算量是非常大的。
BPE 是一种简单的数据压缩算法,它在 1994 年发表的文章“A New Algorithm for Data Compression”中被首次提出。其核心思想是:
BPE每一步都将最常见的一对相邻数据单位替换为该数据中没有出现过的一个新单位,反复迭代直到满足停止条件。其目的是用一个有限的词表在token数量降到最低的情况下解决所有单词的分词,这是可能的,英文单词词根、词源以及时态等语法,这就意味着很多词都有着相同的部分,
如aaabdaaabac这个序列,首先a频率是最高的,其次是aa,这是用Z替换aa,然后两个字符连在一起频率最高的是ab,因而用Y替换ab,得到ZYdZYac,可以依次类推,这样将第一行的原始序列压缩为了最后一样的序列。
 摘自Byte Pair Encoding — The Dark Horse of Modern NLP
摘自Byte Pair Encoding — The Dark Horse of Modern NLP
NLP BPE
NLP中的Subword基于BPE算法,其过程主要如下:
1.准备语料库,确定subword此表总数;
2.在每个单词的末尾添加后缀,统计每个单词出现的词频,如nice的词频为5,则其可记为:“nice ”:5
3.计算语料库中两个字符组成的词频,用新标记替换语料库中两个字符频率最高的,将新标记n-gram添加到词汇表中。
4.递归进行步骤3中的高频词频合并,当词表数量大于subword的总数时,递归进行合并统计词频,知道设置的subword数达到为止。
这一过程的python代码如下:
import re
from collections import Counter, defaultdict
def build_vocab(corpus: str) -> dict:
"""Step 1. Build vocab from text corpus"""
# Separate each char in word by space and add mark end of token
tokens = [" ".join(word) + " </w>" for word in corpus.split()]
# Count frequency of tokens in corpus
vocab = Counter(tokens)
return vocab
def get_stats(vocab: dict) -> dict:
"""Step 2. Get counts of pairs of consecutive symbols"""
pairs = defaultdict(int)
for word, frequency in vocab.items():
symbols = word.split()
# Counting up occurrences of pairs
for i in range(len(symbols) - 1):
pairs[symbols[i], symbols[i + 1]] += frequency
return pairs
def merge_vocab(pair: tuple, v_in: dict) -> dict:
"""Step 3. Merge all occurrences of the most frequent pair"""
v_out = {}
bigram = re.escape(' '.join(pair))
p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)')
for word in v_in:
# replace most frequent pair in all vocabulary
w_out = p.sub(''.join(pair), word)
v_out[w_out] = v_in[word]
return v_out
vocab = build_vocab(corpus) # Step 1
num_merges = 50 # Hyperparameter
for i in range(num_merges):
pairs = get_stats(vocab) # Step 2
if not pairs:
break
# step 3
best = max(pairs, key=pairs.get)
vocab = merge_vocab(best, vocab)
BPE在字符和单词级别的混合表示之间实现了完美的平衡,使其能够管理大型语料库。这种行为还允许使用适当的子单词标记对词汇表中的任何稀有单词进行编码,而不引入任何“未知”标记。这尤其适用于德语等外语,因为德语中存在许多复合词,很难学习到丰富的词汇。有了这种标记化算法,每个单词现在都可以克服被遗忘的恐惧(athazagoraobia)。
WordPiece
Google的Bert模型在分词的时候使用的是WordPiece算法。与BPE算法类似,WordPiece算法也是每次从词表中选出两个子词合并成新的子词。与BPE的最大区别在于,如何选择两个子词进行合并:BPE选择频数最高的相邻子词合并,而WordPiece选择能够提升语言模型概率最大的相邻子词加入词表。
WordPiece选取子词的方法如下,假设句子
S
=
(
t
1
,
t
2
,
⋯
,
t
n
)
S=(t_1,t_2,\cdots, t_n)
S=(t1,t2,⋯,tn)由n个子词组成,
t
i
t_i
ti表示子词,且假设各个子词之间是独立存在的,则句子
S
S
S的语言模型似然值等价于所有子词概率的乘积:
log
P
(
s
)
=
∑
i
=
1
N
log
P
(
t
i
)
\log P(s) = \sum_{i=1}^N \log P(t_i)
logP(s)=i=1∑NlogP(ti)
设把相邻位置的x和y两个子词进行合并,合并后产生的子词记为z,此时句子
S
S
S似然值的变化可表示为:
log
P
(
t
z
)
−
(
l
o
g
P
(
t
x
)
+
l
o
g
P
(
t
y
)
)
=
log
(
P
(
t
z
)
P
(
t
x
)
P
(
t
y
)
)
\log P(t_z) -(log P(t_x)+log P(t_y))= \log(\frac{ P(t_z) }{P(t_x)P(t_y)})
logP(tz)−(logP(tx)+logP(ty))=log(P(tx)P(ty)P(tz))
似然值的变化就是两个子词之间的互信息。简而言之,WordPiece每次选择合并的两个子词,他们具有最大的互信息值,也就是两子词在语言模型上具有较强的关联性,它们经常在语料中以相邻方式同时出现。
Unigram Language Model (ULM)
与WordPiece一样,Unigram Language Model(ULM)同样使用语言模型来挑选子词。不同之处在于,BPE和WordPiece算法的词表大小都是从小到大变化,属于增量法。而Unigram Language Model则是减量法,即先初始化一个大词表,根据评估准则不断丢弃词表,直到满足限定条件。ULM算法考虑了句子的不同分词可能,因而能够输出带概率的多个子词分段。
对于句子S,
X
=
(
x
1
,
x
2
,
⋯
,
x
m
)
X=(x_1,x_2,\cdots, x_m)
X=(x1,x2,⋯,xm)为句子的一个分词结果,由m个子词组成。所以,当前分词下句子S的似然值可以表示为:
P
(
X
)
=
∏
i
=
1
m
P
(
x
i
)
P(X)=\prod \limits_{i=1}^mP(x_i)
P(X)=i=1∏mP(xi)
对于句子S,挑选似然值最大的作为分词结果,则可以表示为:
x
∗
=
arg
max
x
∈
U
(
x
)
P
(
X
)
x^*=\arg \max_{x \in U(x)}P(X)
x∗=argx∈U(x)maxP(X)
这里
U
(
x
)
U(x)
U(x)包含了句子的所有分词结果。在实际应用中,词表大小有上万个,直接罗列所有可能的分词组合不具有操作性。针对这个问题,可通过维特比算法得到
x
∗
x^*
x∗来解决。
每个字词的概率
P
(
x
i
)
P(x_i)
P(xi)用最大期望的方法计算,假设当前词表V,则M步最大化对象是如下似然函数:
L
=
∑
s
=
1
∣
D
∣
log
(
P
(
X
(
s
)
)
)
=
∑
s
=
1
∣
D
∣
log
(
∑
x
∈
U
(
X
(
s
)
)
P
(
x
)
)
L=\sum_{s=1}^{|D|}\log (P(X^{(s)}))=\sum_{s=1}^{|D|}\log(\sum_{x \in U(X^{(s)})}P(x))
L=s=1∑∣D∣log(P(X(s)))=s=1∑∣D∣log(x∈U(X(s))∑P(x))
其中,|D|是语料库中语料数量。上述公式的一个直观理解是,将语料库中所有句子的所有分词组合形成的概率相加。
初始时,词表V并不存在,因而,ULM算法采用不断迭代的方法来构造词表以及求解分词概率:
1.初始时,建立一个足够大的词表,一般,可用语料中的所有字符加上常见的字符串初始化词表,也可以通过BPE初始化;
2.针对当前词表,用EM算法求解买个subword在语料上的概率;
3.对于每个字词,计算当该字词从词表中移除时,总的loss降低了多少,记为该字词的loss。
4.将字词按照loss大小进行排序,丢弃一定比例loss最小的字词(比如20%),保留下来的字词生成新的词表。这里需要注意的是,单字符不能被丢弃,这是为了避免OOV情况,
5.重复步骤2到4,直到词表大小减少到设定范围。
SentencePiece实现了直接从句子训练得到subword的方法(e.g., byte-pair-encoding (BPE) [Sennrich et al.]) and unigram language model [Kudo.]),它是谷歌推出的子词开源工具包,其中集成了BPE、ULM子词算法。除此之外,SentencePiece还能支持字符和词级别的分词。更进一步,为了能够处理多语言问题,sentencePiece将句子视为Unicode编码序列,从而子词算法不用依赖于语言的表示。
Llama使用Sentence Piece Byte-Pair编码(BPE)词元分析器,该词元分析器专为Llama模型设计,不应与OpenAI模型使用的标记器(x)混淆。
使用sentence piece编码中文的例子见Sentencepiece_python_module_example.ipynb