文章目录
- 一、开发环境配置
- 1.1,python安装
-
- 1.2 请求库的安装
- requests
- Selenium
- ChromeDriver
- GeckoDriver
- PhantomJS(版本2.1.1)
- 安装方式一:放到系统目录(推荐)
- 安装方式二:放到用户目录
- 错误解决
- aiohttp
- 1.3解析库的安装
- lxml
- Beautiful Soup
- pyquery
- tesserocr(先安装tesseract)
- 1.4 数据库的安装
- MySQL安装
- MongoDB安装及使用
-
- Redis
- 1.5 存储库的安装
- PyMySQL
- PyMongo
- redis-py
- RedisDump
- 1.6 web库的安装
-
- 1.7 App爬取相关库的安装
-
- 1.8 爬虫框架的安装
- pyspider
- 运行命令`pyspider all`之前,先输入:
- 依赖解决
- 语法错误解决
- Error: Could not create web server listening on port 25555
- Scrapy
- Scarpy-Splash
- Scrapy-Redis
- 1.9 部署相关库的安装
- Docker
- Scrapyd
- Scrapyd-Client
- Scrapyd API
- Scrapyrt
- Gerapy
- 二、爬虫基础
- HTTP基本原理
- URI和URL
- 超文本
- HTTP和HTTPS
- HTTP请求过程及响应
- 网页基础
-
- 爬虫的基本原理
- 爬虫概述
- 能抓怎样的数据
- JavaScript 渲染页面
- 会话和Cookies
-
- 代理的基本原理
-
- 三、基本库的使用
-
一、开发环境配置
1.1,python安装
Windows(设置环境变量)
Linux
Mac
1.2 请求库的安装
requests
Selenium
selenium==2.48.0下这个老版本,新版不支持phantomjs
ChromeDriver
淘宝镜像站:http://npm.taobao.org/mirrors/chromedriver
GeckoDriver
PhantomJS(版本2.1.1)
安装依赖:
sudo apt-get install build-essential chrpath libssl-dev libxft-dev
sudo apt-get install libfreetype6 libfreetype6-dev libfontconfig1 libfontconfig1-dev
下载地址(淘宝镜像):https://npmmirror.com/mirrors/phantomjs?spm=a2c6h.24755359.0.0.6d443dc1T0AXPt
安装方式一:放到系统目录(推荐)
原名太长,重命名,移动到/usr/local/share目录下
sudo mv phantomjs211 /usr/local/share/
创建启动软链接:
sudo ln -s /usr/local/share/phantomjs211/bin/phantomjs /usr/local/bin/
安装方式二:放到用户目录
下载包解压后解压,文件夹移到home目录下,
并设为隐藏文件(文件夹名称前加.号),
修改~/.profile文件:
sudo vim ~/.profile
末尾添加phantomjs执行文件路径,如:
export PATH="$HOME/.phantomjs版本号/bin:$PATH"
错误解决
Auto configuration failed
140277513316288:error:25066067:DSO support routines:DLFCN_LOAD:could not load the shared library:dso_dlfcn.c:185:filename(libssl_conf.so): libssl_conf.so: 无法打开共享对象文件: 没有那个文件或目录
140277513316288:error:25070067:DSO support routines:DSO_load:could not load the shared library:dso_lib.c:244:
140277513316288:error:0E07506E:configuration file routines:MODULE_LOAD_DSO:error loading dso:conf_mod.c:285:module=ssl_conf, path=ssl_conf
140277513316288:error:0E076071:configuration file routines:MODULE_RUN:unknown module name:conf_mod.c:222:module=ssl_conf
解决方法:
export OPENSSL_CONF=/etc/ssl/
aiohttp
1.3解析库的安装
lxml
Beautiful Soup
pyquery
tesserocr(先安装tesseract)
(在windows下因为兼容问题,所以用pytesseract替代tesseroct,然后设置tesseract的环境变量。)
tesseract语言下载包:https://codechina.csdn.net/mirrors/tesseract-ocr/tessdata?utm_source=csdn_github_accelerator
测试安装是否成功:
tesseract image.png result -l eng |type result.txt
tesseract image.png result -l eng |cat result.txt
import pytesseract
from PIL import Image
im=Image.open('image.png')
print(pytesseract.image_to_string(im))
import pytesseract
from PIL import Image
image = Image.open("./NormalImg.png")
text = pytesseract.image_to_string(image)
print(text)
1.4 数据库的安装
windows下修改存储位置、日志位置,设置环境变量。
MySQL安装
(win10:计算机–管理–服务,开启和关闭MySQL服务。)
net stop mysql
MongoDB安装及使用
安装gnupg软件包
sudo apt-get install gnupg
导入包管理系统使用的公钥:
wget -qO - https://www.mongodb.org/static/pgp/server-4.4.asc | sudo apt-key add -
添加MongoDB存储库:(ubuntu20.04)
echo "deb [ arch=amd64,arm64 ] https://repo.mongodb.org/apt/ubuntu bionic/mongodb-org/4.4 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.4.list
更新存储库:
sudo apt-get update
安装mongodb:
sudo apt install mongodb-org
启动mongodb,设置开机自启动
sudo systemctl start mongod.service
sudo systemctl enable mongod
检查MongoDB服务的状态:
sudo systemctl status mongod
关闭MongoDB服务:
sudo systemctl stop mongod
重新启动MongoDB服务:
sudo systemctl restart mongod
关闭开机启动:
sudo systemctl disable mongod
进入MongoDB shell:
mongo
启动错误
● mongod.service - MongoDB Database Server
Loaded: loaded (/lib/systemd/system/mongod.service; disabled; vendor preset: enabled)
Active: failed (Result: exit-code) since Mon 2020-04-20 13:32:29 IST; 6min ago
Docs: https://docs.mongodb.org/manual
Process: 27917 ExecStart=/usr/bin/mongod --config /etc/mongod.conf (code=exited, status=14)
Main PID: 27917 (code=exited, status=14)
Apr 20 13:32:29 manojkumar systemd[1]: Started MongoDB Database Server.
Apr 20 13:32:29 manojkumar systemd[1]: mongod.service: Main process exited, code=exited, status=14/n/a
Apr 20 13:32:29 manojkumar systemd[1]: mongod.service: Failed with result ‘exit-code’.
解决办法:
sudo chown -R mongodb:mongodb /var/lib/mongodb
sudo chown mongodb:mongodb /tmp/mongodb-27017.sock
sudo service mongod restart
windows下:
配置文件,bin目录下有一个mongod.cfg的文件,即为MongoDB的配置文件。可利用记事本等工具打开进行一些配置。 例如修改数据文件保存位置连接端口号等。
storage块下dbpath为数据文件存放目录 ,
systemlog块下path为日志文件保存位置。
如果指定目录或日志不存在启动失败,可手动创建
如果进行修改想要时修改生效的话,需关闭服务并重新启动。
Redis
windows免费版Redis-x64-3.2.100.msi
1.5 存储库的安装
PyMySQL
PyMongo
redis-py
RedisDump
1.6 web库的安装
Flask
Tornado
1.7 App爬取相关库的安装
Charles
mitmproxy
7.*版本有依赖问题,换低版本(如5.0.0)
Appium
1.8 爬虫框架的安装
pyspider
运行命令pyspider all之前,先输入:
export OPENSSL_CONF=/etc/ssl/
依赖解决
先安装phantomjs
其他软件要求版本
Wsgidav==2.3.0
Werkzeug==0.16.1
Flask==1.1.1(不行就试试0.1.0)
其他相关依赖一般互相有提示
语法错误解决
由于async和await从 python3.7 开始已经加入保留关键字中,所以修改/home/san/.local/lib/python3.9/site-packages/pyspider/下的python文件的async为shark(全部替换),在替换是要注意:只替换名为async 的变量或参数名,不要图省事选择“全部替换”,导致引用的类名被修改,如下图。
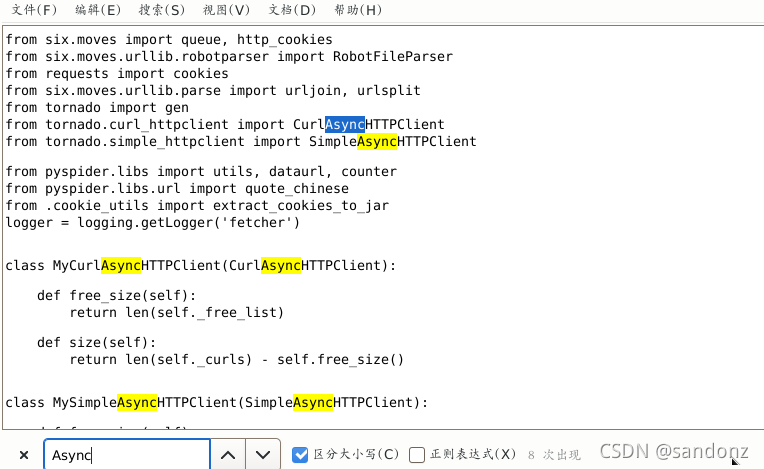
注意:例如文件tornado_fetcher.py中如果全部替换是17处,便会报错 from tornado.curl_httpclient import CurlAsyncHTTPClient
from tornado.simple_httpclient import SimpleAsyncHTTPClient
如果已经全部替换完,请回去手动将其中几处引用类名改回来。
要替换的文件如下:
1.run.py
2.fetcher\tornado_fetcher.py
3.webui\app.py
Error: Could not create web server listening on port 25555
查看25555端口占用:
lsof -i:25555
找到占用进程PID,kill掉
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
phantomjs 8982 san 7u IPv4 194586 0t0 TCP *:25555 (LISTEN)
kill 8982
重新运行
pyspider all
Scrapy
Scarpy-Splash
splash需要通过Docker安装
Scrapy-Redis
1.9 部署相关库的安装
Docker
Scrapyd
Scrapyd-Client
Scrapyd API
Scrapyrt
Gerapy
二、爬虫基础
HTTP基本原理
URI和URL
URI统一资源标志符
URL统一资源定位符
URL是URI的子集
超文本
HTTP和HTTPS
HTTP超文本传输协议,Hyper Text Transfer Protocol
HTTPS是HTTP的安全版,即HTTP下加入SSL层,Hyper Text Transfer Protocol over Secure Socket Layer
HTTP请求过程及响应


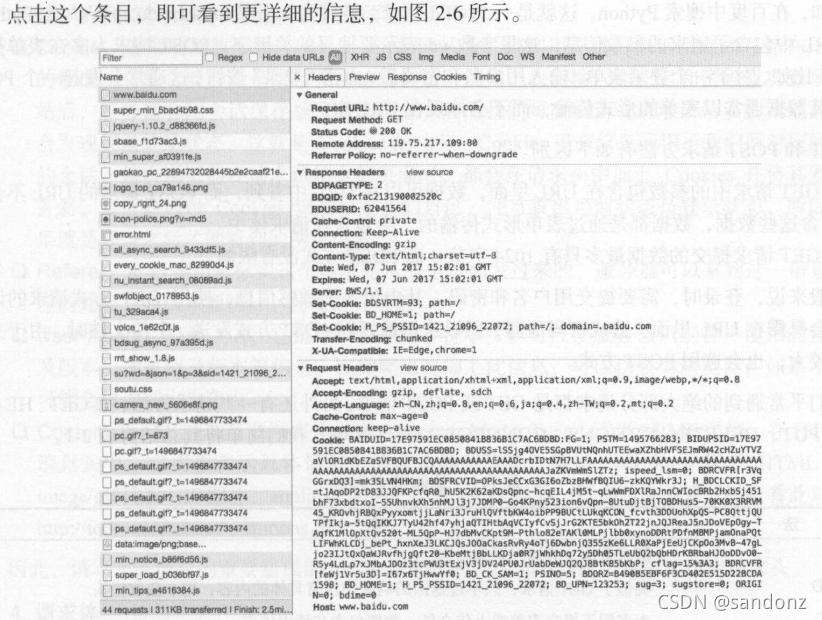





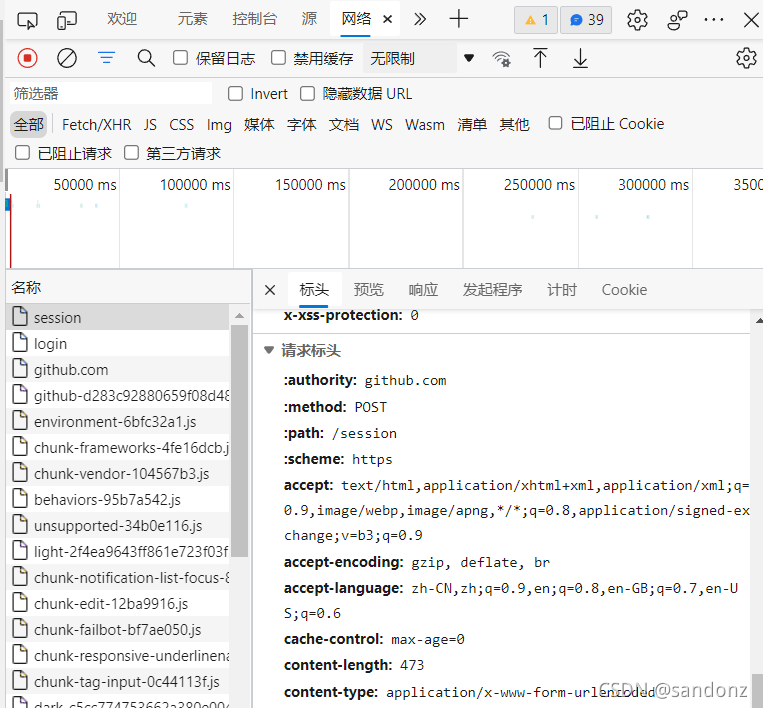






网页基础
网页的组成
HTML
CSS
JavaScript
网页的结构
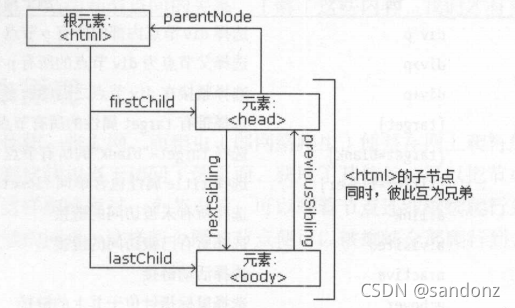
节点树及节点间的关系
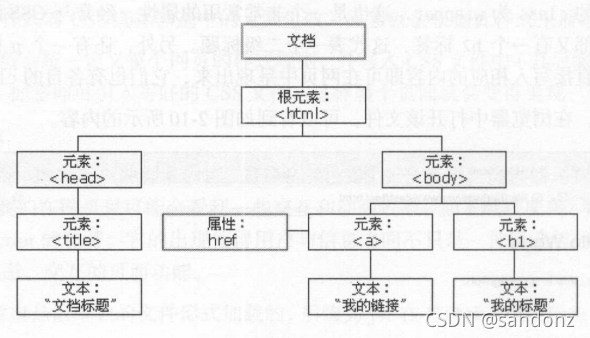
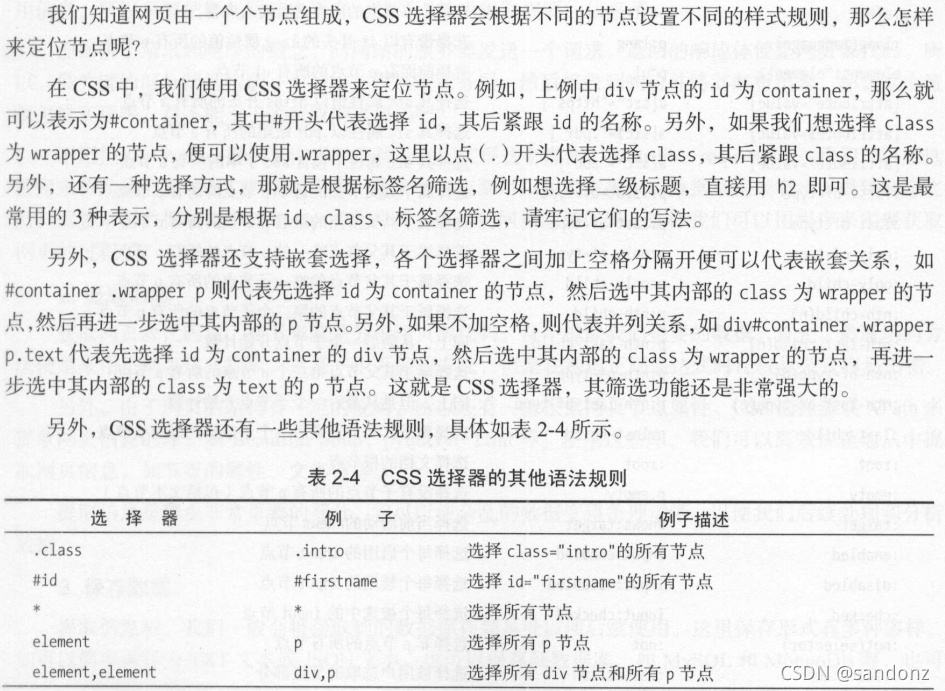
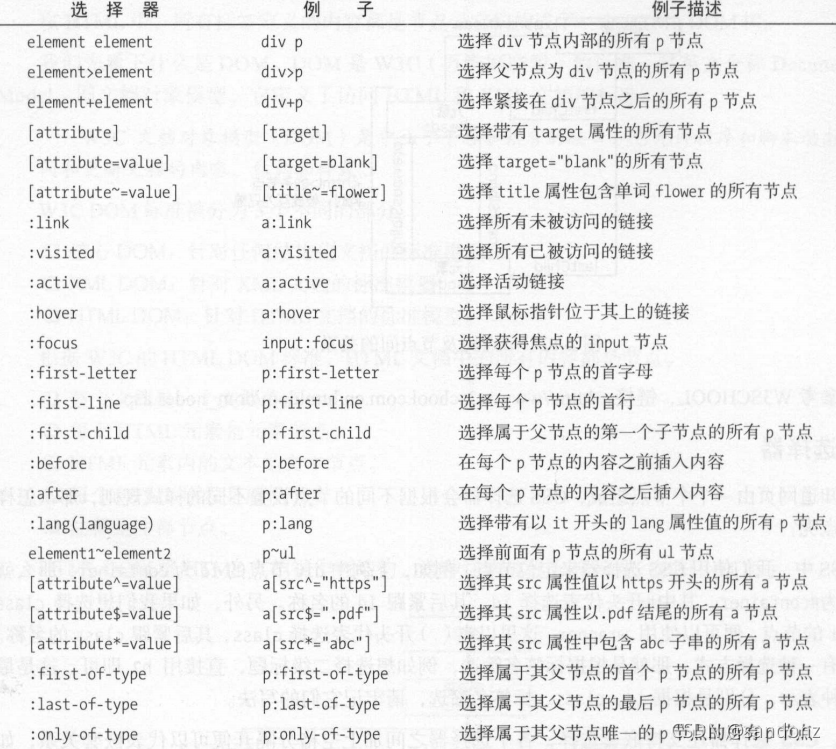
选择器

爬虫的基本原理
爬虫概述
1,获取网页(源代码)
获取库urllib、requests
2,提取信息
提取库Beautiful Soup、pyquery、lxml
3,保存数据
本地:TXT、JSON或MySQL、MongoDB
远程服务器:借助SFTP操作
4,自动化程序
能抓怎样的数据


会话和Cookies

静态网页和动态网页


无状态HTTP





常见误区

代理的基本原理

基本原理

代理的作用

爬虫代理

代理分类


常见代理设置

三、基本库的使用
1,使用urllib
request:它是最基本的 HTTP 请求模块,可以用来模拟发送请求。只需要给库方法传入 URL 以及额外的参数,就可以模拟实现这个过程了 。
error:异常处理模块,如果出现请求错误 , 我们可以捕获这些异常,然后进行重试或其他操
作以保证程序不会意外终止 。
parse : 一个工具模块,提供了许多 URL 处理方法,比如拆分、解析 、 合并等 。
robot parser :主要是用来识别网站的 robots.txt 文件,然后判断哪些网站可以爬,哪些网站不
可以爬,它其实用得 比较少 。
发送请求
urlopen()
API:
urllib.request.urlopen(url, data=None, [ timeout, ]*, cafile=None, capath=None, cadefault=False, context=None )
data参数
timeout参数
context参数
cafile参数
capath参数
Request
class urllib.request.Request ( url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
高级用法
urllib.request 模块里的 BaseHandler 类,它是所有其他 Handler 的父类,它提
供了最基本的方法,例如 default_open()、 protocol_request ()等 。
各种Handler子类
HTTPDefaultErrorHandler :用于处理 HTTP 响应错误,错误都会抛出 HTTP Error 类型的异常 。
HTTPRedirectHandler :用于处理重定向 。
HTTPCookieProcessor : 用于处理 Cookies 。
ProxyHandler :用于设置代理 , 默认代理为空 。
HTTPPasswordMgr :用于管理密码,它维护了用户名和密码的表 。
HTTPBasicAuthHandler : 用于管理认证,如果一个链接打开时需要认证,那么可以用它来解
决认证问题。
处理异常
解析链接
分析Robots协议
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)