前面的7次笔记介绍的都是分类问题,本次开始介绍聚类问题。分类和聚类的区别在于前者属于监督学习算法,已知样本的标签;后者属于无监督的学习,不知道样本的标签。下面我们来讲解最常用的kmeans算法。
1:kmeans算法
算法过程:Kmeans中文称为k-均值,步骤为:(1)它事先选定k个聚类中心,(2)然后看每个样本点距离那个聚类中心最近,则该样本就属于该聚类中心。(3)求每个聚类中心的样本的均值来替换该聚类中心(更新聚类中心)。(4)不断迭代(2)和(3), 直到收敛。
复杂度:Kmeans算法的时间复杂度为O(m*n*k*d),其中m为样本的个数,n为维数,k为迭代的次数,d为聚类中心的个数。空间复杂度为O(m*n)。
Costfunction: kmeans聚类是使得SSE(sum of squared error)达到最小,SSE公式表示为:
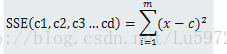
由于SSE为非凸函数,因此每次聚类并不一定能使SSE达到全局最小值,只能使其达到局部最优解。但是可以重复执行几次kmeans,选取SSE最小的一次作为最终的聚类结果。
2:python代码的实现
from numpy import *
#加载数据
def loadDataSet(fileName):
dataMat = []
fr = open(fileName)
for line in fr.readlines():
curLine = line.strip().split('\t')
fltLine = map(float, curLine) #变成float类型
dataMat.append(fltLine)
return dataMat
# 计算欧几里得距离
def distEclud(vecA, vecB):
return sqrt(sum(power(vecA - vecB, 2)))
#构建聚簇中心
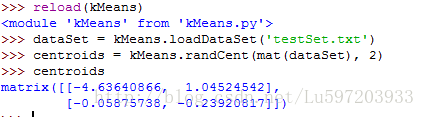
def randCent(dataSet, k):
n = shape(dataSet)[1]
centroids = mat(zeros((k,n)))
for j in range(n):
minJ = min(dataSet[:,j])
maxJ = max(dataSet[:,j])
rangeJ = float(maxJ - minJ)
centroids[:,j] = minJ + rangeJ * random.rand(k, 1)
return centroids
#k-means 聚类算法
def kMeans(dataSet, k, distMeans =distEclud, createCent = randCent):
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m,2))) #用于存放该样本属于哪类及质心距离
centroids = createCent(dataSet, k)
clusterChanged = True
while clusterChanged:
clusterChanged = False;
for i in range(m):
minDist = inf; minIndex = -1;
for j in range(k):
distJI = distMeans(centroids[j,:], dataSet[i,:])
if distJI < minDist:
minDist = distJI; minIndex = j
if clusterAssment[i,0] != minIndex: clusterChanged = True;
clusterAssment[i,:] = minIndex,minDist**2
print centroids
for cent in range(k):
ptsInClust = dataSet[nonzero(clusterAssment[:,0].A == cent)[0]] # 去第一列等于cent的所有列
centroids[cent,:] = mean(ptsInClust, axis = 0)
return centroids, clusterAssment
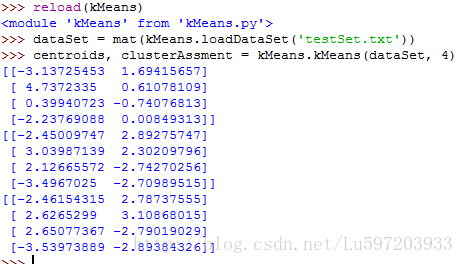
注意:度量聚类效果的指标是SSE(Sum of Squared Error, 误差平方和),即属于同一聚类中心的所有样本点到该聚类中心的距离和。通常有以下两种后处理的方法来提高算法的聚类性能。
(1) 将具有最大SSE值的簇划分成两个簇。
(2) 合并最近的质心或者合并两个使得SSE增幅最小的质心。
3:二分k-均值算法
为了克服k-均值算法收敛于局部最小值的问题,有人提出了另外一种称为二分k-均值的算法。该算法首先将所有点作为一个簇,然后将该簇一分为二。之后选择其中一个簇继续进行划分,选择哪一个簇进行划分有两种方法。(1)该划分是否可以最大程度地降低SSE的值。(2)选择SSE最大的簇进行划分。划分过程不断重复,直到簇的数目达到用户指定数目为止。
#2分kMeans算法 #两种方法:(1)是否可以最大程度的降低SSE的值 (2)选择SSE最大的簇进行划分
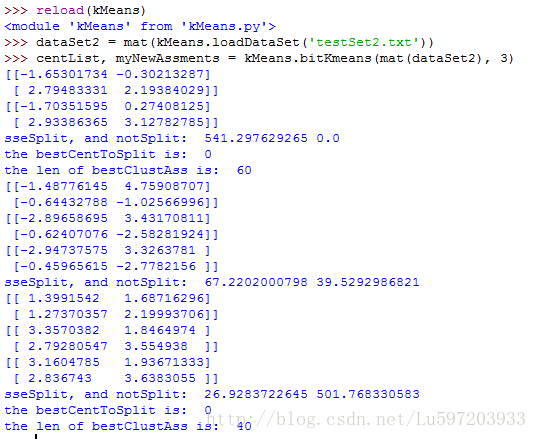
def bitKmeans(dataSet, k, distMeas=distEclud):
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m,2)))
centroid0 = mean(dataSet, axis=0).tolist()[0]
centList =[centroid0]
for j in range(m):
clusterAssment[j,1] = distMeas(mat(centroid0), dataSet[j,:])**2
while (len(centList) < k):
lowestSSE = inf #无穷大
for i in range(len(centList)):
ptsInCurrCluster = dataSet[nonzero(clusterAssment[:,0].A==i)[0],:]
centroidMat, splitClustAss = kMeans(ptsInCurrCluster, 2, distMeas)
sseSplit = sum(splitClustAss[:,1])
sseNotSplit = sum(clusterAssment[nonzero(clusterAssment[:,0].A!=i)[0],1])
print "sseSplit, and notSplit: ",sseSplit,sseNotSplit
if (sseSplit + sseNotSplit) < lowestSSE:
bestCentToSplit = i
bestNewCents = centroidMat
bestClustAss = splitClustAss.copy()
lowestSSE = sseSplit + sseNotSplit
bestClustAss[nonzero(bestClustAss[:,0].A == 1)[0],0] = len(centList) #二分后标签更新
bestClustAss[nonzero(bestClustAss[:,0].A == 0)[0],0] = bestCentToSplit
print 'the bestCentToSplit is: ',bestCentToSplit
print 'the len of bestClustAss is: ', len(bestClustAss)
centList[bestCentToSplit] = bestNewCents[0,:].tolist()[0] #加入聚类中心
centList.append(bestNewCents[1,:].tolist()[0])
clusterAssment[nonzero(clusterAssment[:,0].A == bestCentToSplit)[0],:]= bestClustAss #更新SSE的值(sum of squared errors)
return mat(centList), clusterAssment
此外:还有层次聚类算法和密度聚类算法
层次聚类算法有两种,一种是凝聚的聚类算法,另外一种是层次的聚类算法

密度聚类算法用的比较少,这里不做详细讲解
DBSCAN是一个比较有代表性的密度聚类算法。