安装clickhosue:
Clickhouse安装(新手必看)_初念、LL的博客-CSDN博客_clickhouse安装
安装mysql:
在clickhouse创建表,字段和需导入的mysql表相同;
datax实现mysql到clickhouse同步:
官方编译的datax包默认没有clickhousewriter插件,需下载源码手动编译:
GitHub - alibaba/DataX: DataX是阿里云DataWorks数据集成的开源版本。
下载并解压到本地
安装maven环境(参考网上教程,修改mirror为阿里云源)
安装jdk1.8(建议安装1.8版本,15以上版本编译会报错)
1.编译clickhousewriter
我们只需要clickhousewriter,将其他模块从datax目录下pom.xml中删除,否则其他组件可能找不到依赖,导致编译失败。
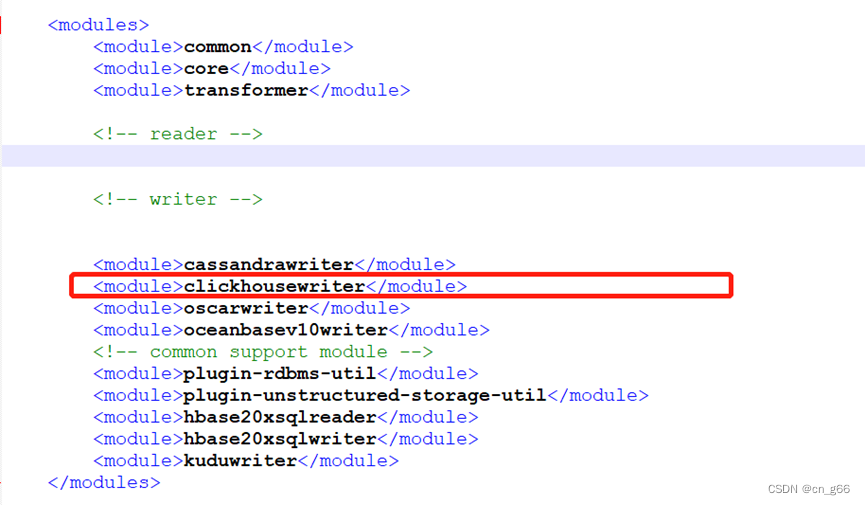
使用官方提供的命令进行编译:
mvn -U clean package assembly:assembly -Dmaven.test.skip=true
编译成功:

编译好的文件都在datax对应目录target下:

2.安装使用
下载官方编译好的包:
wget http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
下载后解压至本地某个目录,进入bin目录,即可运行同步作业:
$ cd {YOUR_DATAX_HOME}/bin
$ python datax.py {YOUR_JOB.json}
目录结构:
bin目录下是python脚本文件,主要用来执行job文件(默认需要依赖Python2的环境,也可以修改为Python3)
conf目录存放一些配置文件
job目录下存放了一个job测试文件(我们通过datax-web生成的临时job文件不会放在这里,而是在data-web里边自己配置存放目录)
lib是依赖的一些jar包
log目录存放job文件的执行日志
plugin目录存放的是对不同数据源读取(Reader)和写入(Writer)的插件支持
如果没有在plugin目录下发现自己需要的Reader或者Writer则需要自己手动安装(比如ES的Reader和Writer)。
job文件是一个JSON格式的文件,每一个job文件都代表一个同步任务,执行job文件需要使用bin目录datax.py脚本。执行命令如下命令执行job任务:
python datax.py job文件
生成模板:
执行 python datax.py -r mysqlreader -w mysql_writer,然后将控制台生成的模板,保存到 datax的job目录下,存为一个json文件。也可以执行 python datax.py -r {YOUR_READER} -w {YOUR_WRITER} > ../job/test.json 直接将输出重定至到文件中
因为官方编译包默认没有带clickhosue插件,这里提示没有clickhousewriter插件,我们将刚才编译好的clickhouse插件放到服务器datax/plugin/writer目录下。
执行python datax.py -r mysqlreader -w clickhousewriter
生成模板成功,基于模板进行修改:
| { "job": { "content": [ { "reader": { "name": "mysqlreader", "parameter": { "column": [ "id", "col1", "col2", "create_date" ], "connection": [ { "jdbcUrl": ["jdbc:mysql://127.0.0.1:3306/oms?useUnicode=true&characterEncoding=utf-8&useSSL=false"], "table": [ "test02" ] } ], "password": "xxxx", "username": "root", "where": "" } }, "writer": { "name": "clickhousewriter", "parameter": { "batchByteSize": 134217728, "batchSize": 65536, "column": [ "id", "col1", "col2", "create_date" ], "connection": [ { "jdbcUrl": "jdbc:clickhouse://127.0.0.1:8123/test", "table": [ "test02" ] } ], "dryRun": false, "password": "xxx", "postSql": [], "preSql": [], "username": "default", "writeMode": "insert" } } } ], "setting": { "speed": { "channel": "5" } } } } |
运行job
python datax.py ../job/mysql2clickhouse.json

3.增量同步
按天增量同步:

新增两条日期为今天的数据:

vi increment.sh
添加到定时,每天执行一次
#!/bin/bash
. /etc/profile
#当前时间,用于增量判断
curr_time=$(date -d last-day +%Y-%m-%d)
dodir=`pwd`
#datax增量同步
python /home/datax/datax/bin/datax.py /home/datax/datax/job/mysqlday2clickhouse.json -p "-Dcurr_time=$curr_time" >>$dodir$(date "+%Y%m%d").log 2>&1 &
json文件:
………
"where": "create_date='${curr_time}'"
………
通过datetime类型字段实现增量同步:
#!/bin/bash
. /etc/profile
set -x
#当前时间,用于增量判断
clickhouse_passwd=xxxxx
clickhouse_user=default
curr_time=$(date +%Y-%m-%d\ %H:%M:%S)
last_time=`clickhouse-client -u $clickhouse_user --password="$clickhouse_passwd" -q "select max(create_date) from test.test02"`
#datax增量同步
python /home/datax/datax/bin/datax.py /home/datax/datax/job/mysqlIncremental2clickhouse.json -p "-Dcurr_time='$curr_time' -Dlast_time='$last_time'" >>/home/datax/datax/bin/sh$(date "+%Y%m%d").log 2>&1 &
~
json:

将脚本添加到定时任务
插入几条数据

查看脚本输出,同步成功

 部分转载:
部分转载:
DataX 同步mysql到clickhouse_福州-司马懿的博客-CSDN博客_datax支持clickhouse