目录
文字识别(OCR)介绍与开源方案对比
一、OCR是什么
二、OCR基本原理说明
三、OCR基本实现流程
四、OCR开源项目调研
1、tesseract
2、PaddleOC
3、EasyOCR
4、chineseocr
5、chineseocr_lite
6、cnocr
7、商业付费OCR
1)腾讯OCR(付费) - AI 基础产品模块
2)阿里OCR(付费) - 阿里灵杰AI开放服务
3) 百度OCR (付费) - 百度AI开放能力
五、主要开源项目对比和结论
1、项目优缺点对比
2、综合对比
一、OCR是什么
OCR (Optical Character Recognition,光学字符识别)技术是一种将印刷体或手写文字转化为可编辑文本的技术。亦即将图像中的文字进行识别,并以文本的形式返回。
从图像化的文本信息中提取到文字符号做表征的语义信息,其重要性不言而喻,在实际应用场景中也比较容易想到跟NLP技术结合来完成比较优质的人机交互等任务。

二、OCR基本原理说明
为了识别一张图片中的文字,通常包含两个步骤:
1)、文本检测:检测出图片中文字所在的位置;
2)、文字识别:识别包含文字的图片局部,预测具体的文字。
三、OCR基本实现流程
OCR(光学字符识别)的简单实现流程通常包括以下步骤:
1、图像预处理:首先,对输入的图像进行预处理,包括灰度化、二值化、去噪等操作。这些操作有助于提高字符识别的准确性和稳定性。
2、文本区域检测:使用图像处理技术(如边缘检测、轮廓分析等),找到图像中可能包含文本的区域。这些区域通常是字符或文本行的边界。
3、字符分割:对于文本行,需要将其分割为单个字符。这可以通过字符之间的间距、连通性等特征进行分割。
4、特征提取:对于每个字符,提取其特征表示。常见的特征包括形状、角度、纹理等。特征提取有助于将字符转化为可供分类器处理的数值表示。
5、字符分类:使用分类器(如机器学习算法或深度学习模型)对提取的字符特征进行分类,将其识别为相应的字符类别。分类器可以是预训练模型,也可以是自定义训练的模型。
6、后处理:对识别的字符进行后处理,如纠正错误、校正倾斜、去除冗余等。这可以提高最终结果的准确性和可读性。
7、输出结果:将识别的字符组合成最终的文本输出,可以是单个字符、单词或完整的文本。
四、OCR开源项目调研
1、tesseract
https://github.com/tesseract-ocr/tesseract

Tesseract是一个开源的OCR(光学字符识别)引擎,由Google开发和维护。它能够将图像中的文本转换为可编辑的文本,并且支持多种语言的文本识别。Tesseract已经成为广泛使用的OCR工具之一,具有较高的准确率和可扩展性。
以下是Tesseract的主要特点和功能:
1、多语言支持:Tesseract支持多种语言的文本识别,包括英语、中文、日语、韩语、法语、德语、西班牙语等。它具有训练和识别多种语言的能力,并且用户可以根据需要添加自定义语言模型。
2、高准确率:Tesseract使用了一系列的图像处理和机器学习算法,以实现高准确率的文本识别。它经过大规模数据集的训练和优化,能够在各种图像条件下准确地识别出字符信息。
3、可扩展性:Tesseract具有良好的可扩展性,用户可以使用自定义训练数据来训练和优化OCR模型,以提高识别的准确性和适应性。此外,Tesseract还提供了API和接口,方便用户进行二次开发和集成。
4、平台兼容性:Tesseract支持多种操作系统,包括Windows、Mac和Linux等。它可以在各种平台上运行,并且提供了与不同编程语言(如Python、Java、C++等)的接口,方便开发者进行集成和使用。
5、开源和社区支持:Tesseract是一个开源项目,具有活跃的社区支持。用户可以自由查看和修改源代码,并参与社区讨论和贡献。这使得Tesseract成为一个不断发展和改进的OCR工具。
2、PaddleOC
https://github.com/PaddlePaddle/PaddleOCR

PaddleOCR是一个基于飞桨(PaddlePaddle)深度学习平台的开源OCR(光学字符识别)工具,旨在提供高性能和准确率的文本识别功能。它可以识别和提取多语言文本中的字符信息,并具有广泛的应用场景,包括文档处理、图像文字提取、自动化数据录入等。
以下是PaddleOCR的主要特点和功能:
1、多语言支持:PaddleOCR支持多种语言的文本识别,包括英语、中文、日语、韩语、法语、德语、西班牙语等。它可以处理不同语言的文本,并满足跨国应用的需求。
2、多种模型选择:PaddleOCR提供了多种预训练的OCR模型供选择,包括文本检测模型和文本识别模型。文本检测模型用于检测文本区域,而文本识别模型用于识别文本内容。用户可以根据自己的需求选择适合的模型。
3、高准确率和性能:PaddleOCR采用了深度学习技术,利用预训练的神经网络模型实现高准确率的文本识别。它在大规模数据集上进行了训练和优化,能够在各种图像条件下识别出准确的字符信息,并具有较高的性能和效率。
4、强大的功能扩展性:PaddleOCR提供了丰富的功能扩展接口和工具,使用户可以自定义和定制OCR模型。用户可以根据自己的数据集和应用场景进行模型训练、微调和优化,以进一步提高识别的准确性和适应性。
5、开源和社区支持:PaddleOCR是一个开源项目,具有活跃的社区支持。用户可以自由查看和修改源代码,也可以参与社区讨论和贡献。这为用户提供了一个共享和合作的平台,以促进OCR技术的发展和应用。
3、EasyOCR
https://github.com/JaidedAI/EasyOCR

EasyOCR是一种简单易用的开源OCR(光学字符识别)工具,旨在识别和提取多语言文本中的字符信息。它提供了一种快速而准确的方式来将印刷体字符转换为可编辑的文本,可以应用于多种场景,包括文档扫描、图像文字提取、自动化数据录入等。EasyOCR 是由 Jaided AI 公司创建的。全语种的(包括80+门外语识别),不单单针对中文,所以它的官方文档是英文。
以下是EasyOCR的主要特点和功能:
1、多语言支持:EasyOCR支持多种语言的文本识别,包括英语、中文、日语、韩语、法语、德语、西班牙语等。这使得它能够处理不同语言的文本,并满足跨国应用的需求。
2、高准确率:EasyOCR采用了基于深度学习的方法,利用深度神经网络模型来实现高准确率的文本识别。这些模型经过大规模数据的训练和优化,能够在各种图像条件下识别出准确的字符信息。
3、简单易用:EasyOCR注重用户友好性,提供了简单易用的API和命令行界面,使用户能够轻松集成和使用该工具。无需复杂的配置和调优,即可进行快速的文本识别。
4、支持多种图像格式:EasyOCR能够处理多种常见的图像格式,包括JPEG、PNG、BMP等。这使得用户可以使用各种图像来源,如扫描仪、手机拍摄等,进行文本识别。
5、高性能:EasyOCR针对效率进行了优化,能够在较短的时间内处理大量的图像并进行文本识别。这对于需要处理大批量图像或实时应用的场景非常有用。
官方demo:
https://www.jaided.ai/easyocr/
4、chineseocr
https://github.com/chineseocr/chineseocr

它基于 YOLO V3 与 CRNN 实现中文自然场景文字检测及识别
如果要做个性化的话,Chineseocr框架相对来说非常方便,只需要修改对应模块的函数就可以,因为本身这些模块其实就是可扩展的,比如后续pull request到项目里的lstm推理和ncnn核扩展。
5、chineseocr_lite
https://github.com/DayBreak-u/chineseocr_lite

ChineseOCR Lite是一种基于深度学习的开源OCR(光学字符识别)引擎,旨在识别和提取中文文本中的字符信息。它使用深度神经网络来实现高准确率的文本识别功能,并且具有较小的模型体积和较快的识别速度。
以下是一些ChineseOCR Lite的主要特点和功能:
1、中文文本识别:ChineseOCR Lite专注于中文文本的识别和提取。它可以处理印刷体中文字符,并能够在各种图像中准确识别和提取文本信息。
2、深度学习模型:该引擎采用深度神经网络模型,通常使用卷积神经网络(CNN)和循环神经网络(RNN)的组合。这种模型能够学习和理解字符的特征,并能够对复杂的文本进行准确的识别。
3、开源和可定制:ChineseOCR Lite是一个开源项目,这意味着用户可以自由地查看和修改源代码,以满足自己的需求。用户可以根据自己的数据集和应用场景进行训练和微调,以提高识别的准确性和性能。
4、小模型体积:ChineseOCR Lite着重于设计轻量级的模型,以减小模型的体积和内存占用。这使得它能够在嵌入式设备或资源受限的环境中运行,提供实时的文本识别能力。
5、高速识别:由于模型的小尺寸和优化,ChineseOCR Lite能够快速处理图像并进行实时的文本识别。这对于需要快速处理大量图像或实时应用的场景非常有用。
超轻量级中文ocr,支持竖排文字识别, 支持ncnn推理 , psenet(8.5M) + crnn(6.3M) + anglenet(1.5M) 总模型仅17M。
相比 chineseocr,chineseocr_lite 采用了轻量级的主干网络 PSENet,轻量级的 CRNN 模型和行文本方向分类网络 AngleNet。尽管要实现多种能力,但 chineseocr_lite 总体模型只有 17M。目前 chineseocr_lite 支持任意方向文字检测,在识别时会自动判断文本方向。
6、cnocr
https://github.com/breezedeus/CnOCR

cnocr是一个基于深度学习的中文OCR(光学字符识别)工具,专门用于识别和提取中文文本中的字符信息。它采用了深度神经网络模型,具有高准确率和较快的识别速度。
以下是cnocr的主要特点和功能:
1、中文文本识别:cnocr专注于中文文本的识别和提取。它能够处理印刷体中文字符,并能够在各种图像中准确识别和提取中文文本信息。
2、基于深度学习:cnocr使用深度神经网络模型进行文本识别。这种模型能够学习和理解字符的特征,并能够对复杂的中文文本进行准确的识别。
3、简单易用:cnocr提供了简单易用的API和命令行界面,使用户能够轻松集成和使用该工具。无需复杂的配置和调优,即可进行快速的中文文本识别。
4、高准确率:由于采用了深度学习模型,cnocr具有较高的准确率,能够识别出复杂字形和字体的中文字符。
5、快速识别:cnocr经过优化,能够在较短的时间内处理图像并进行实时的中文文本识别。这对于需要快速处理大量图像或实时应用的场景非常有用。
7、商业付费OCR
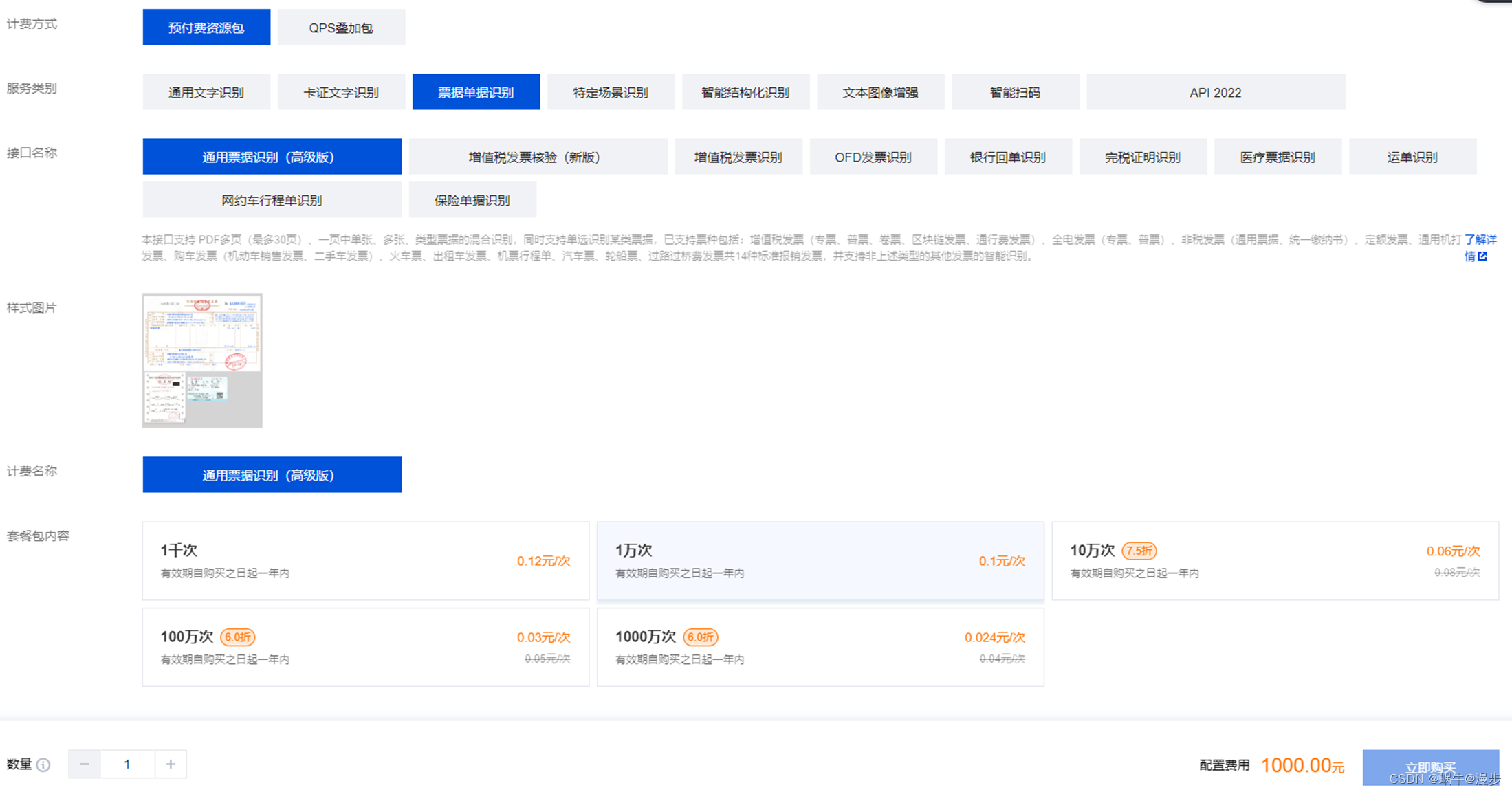
1)腾讯OCR(付费) - AI 基础产品模块
AI 基础产品
https://cloud.tencent.com/document/product/866/17624
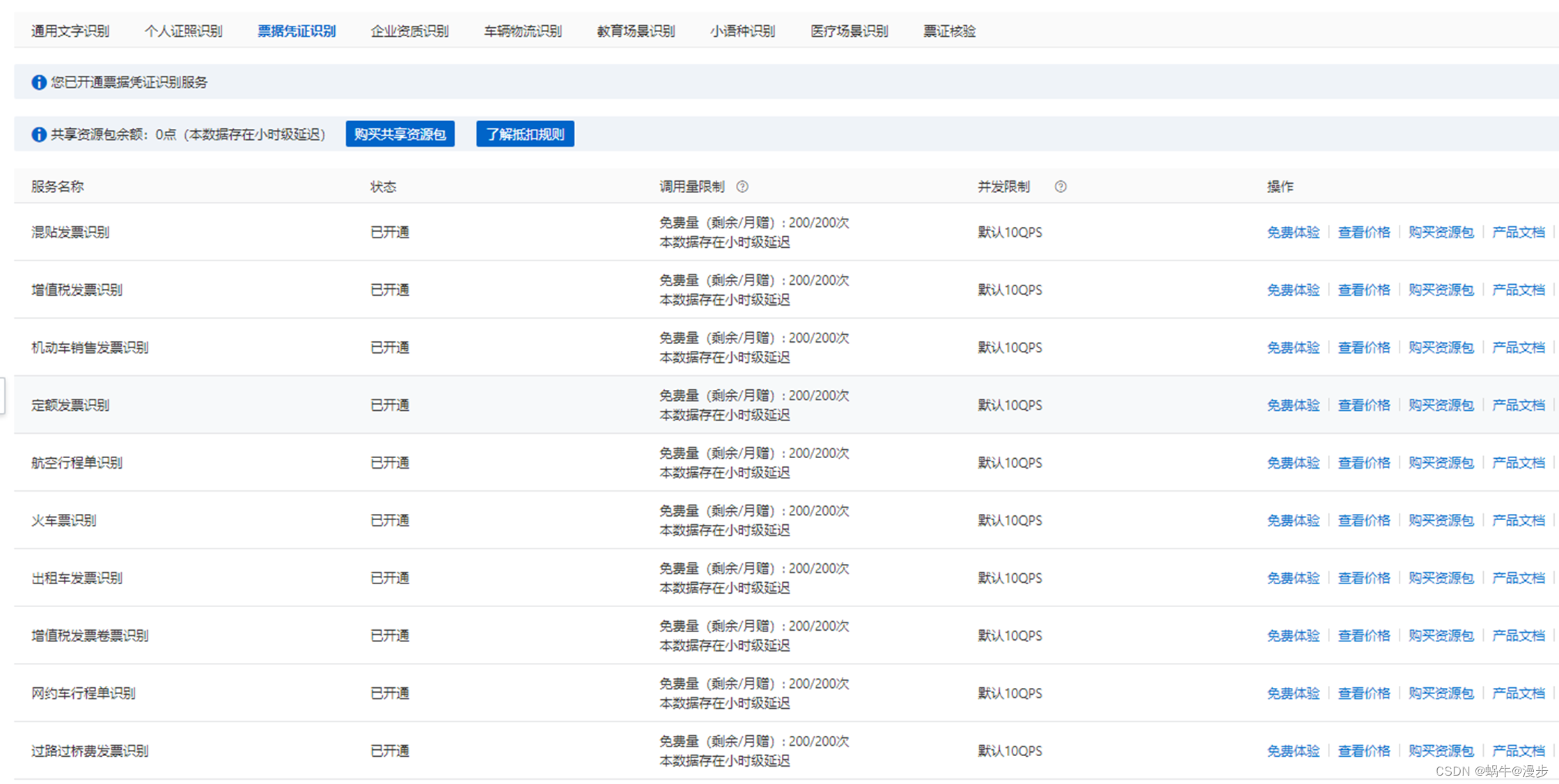
2)阿里OCR(付费) - 阿里灵杰AI开放服务
阿里灵杰AI开放服务
https://help.aliyun.com/document_detail/442328.html?spm=a2c4g.295341.0.0.5bc4525aeKeSzs
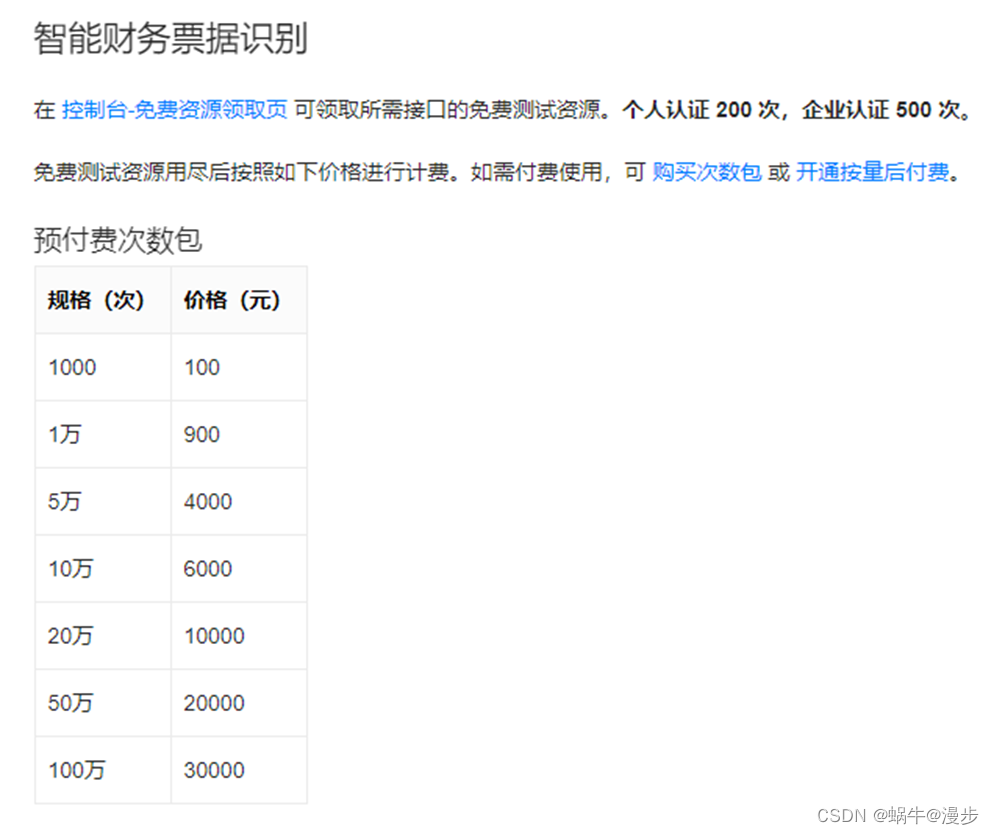
3) 百度OCR (付费) - 百度AI开放能力
百度AI开放能力
https://ai.baidu.com/tech/ocr
五、主要开源项目对比和结论
1、项目优缺点对比
| 项目 |
优点 |
缺点 |
| tesseract |
1、github上面star非常多,项目非常活跃 2、多语言支持:Tesseract支持多种语言的文本识别,可以处理多种语言的文本 3、后面做背书的公司非常强(google) 4、Tesseract提供了扩展接口和工具,可以自定义训练和优化OCR模型 |
1、不是专门针对中文场景 2、相关文档主要是英文,对于阅读和理解起来有一定困难 3、学习成本比较高 4、对于复杂字形和字体的识别准确性较低 5、与其他OCR相比,Tesseract的准确率可能相对较低 |
| PaddleOCR |
1、github上面star非常多,项目非常活跃 2、模型只针对中文进行训练 3、百度后面做背书,公司非常强 4、提供了多种预训练模型和接口,支持用户进行自定义训练和优化 5、识别的精确度比较高 |
1、安装和配置相对复杂一些,需要一定的技术知识和经验 2、对于一些较小的文字或低分辨率的图像,PaddleOCR的性能可能受到影响 3、使用的训练模型是基于百度公司自己的PaddlePaddle框架,对于小公司来说并不主流(对比于ts或者pytorch),所使用深度学习框架为后续其他深度学习无法做很好的铺垫 4、项目整体比较复杂,学习成本较高 |
| EasyOCR |
1、github上面的star也是比较多 2、支持的语言也是非常多的,多达80多种 3、识别的精确度尚可 |
1、从官方的页面体验来说识别的速度较慢 2、识别的文字种类多,学习难度较高 3、相关的官方文档是基于英文的,学习难度较高,对于新手不太友好 4、由于模型较大,EasyOCR的内存占用较高 |
| chineseocr |
1、github上面的star也是比较多 2、专门针对中文进行学习和训练的模型 3、具有一定的准确性和可扩展性 |
1、需要一定的技术知识和经验来进行安装和配置。 2、文档和社区支持相对较少 |
| chineseocr_lite |
1、github上面的star也是比较多 2、专门针对中文进行学习和训练的模型 3、比较轻量级,具有较小的模型和内存占用 4、由于模型较小,chineseocr_lite具有较快的文本识别速度 |
1、因为没有大厂和公司的背书, 所以存在一些bug 2、对于复杂场景下的效果不佳 3、准确率相对较低 4、功能和扩展性相对有限 |
| CNOCR |
1、高准确率:cnocr利用深度学习模型实现高准确率的中文文本识别。 2、简单易用:cnocr提供了简单易用的API和命令行界面,方便用户集成和使用。 3、快速识别:cnocr经过优化,能够快速处理图像并进行实时的中文文本识别。 |
1、依赖深度学习框架:cnocr依赖于深度学习框架,因此在使用之前需要安装相应的框架和依赖库。 2、仅支持中文文本:cnocr主要用于中文文本识别,对于其他语言的文本识别支持有限。 |
| |
|
|
2、综合对比
Tesseract: Tesseract是一个成熟且广泛使用的OCR引擎,具有强大的社区支持和多语言的识别能力。它是开源的,可扩展性强,但准确度相对其他工具可能略低一些。对于简单的文本识别任务,Tesseract可能是一个简单易用的选择。
PaddleOCR: PaddleOCR是基于飞桨深度学习平台的OCR工具,具有多语言支持和较高的准确率。它提供了多种预训练模型和自定义训练的功能,适用于复杂的文本识别任务。然而,PaddleOCR的安装和配置可能相对复杂一些。
EasyOCR: EasyOCR是一个简单易用的OCR工具,支持多语言和多种字体的文本识别。它具有较高的准确率,并提供简单的API和界面,便于集成和使用。对于快速部署和简单的文本识别需求,EasyOCR可能是一个不错的选择。
chineseocr: chineseocr是一个开源的中文OCR工具,具有一定的准确性和可扩展性。然而,它的文档和社区支持相对较少,可能需要一定的技术知识和经验进行安装和配置。
chineseocr_lite: chineseocr_lite是一个轻量级的中文OCR工具,具有较小的模型和快速识别速度。然而,它的准确率相对较低,适用于一些简单的文本识别场景。
cnocr: cnocr是一个专门用于中文文本识别的OCR工具,基于深度学习模型,具有较高的准确率和较快的识别速度。它适用于中文文本的识别和提取任务,但对于其他语言的支持可能有限。
对于简单易用性和准确度高的要求,EasyOCR和cnocr可能是较好的选择。EasyOCR提供了简单易用的API和界面,适用于快速部署和简单的文本识别任务。而cnocr则专注于中文文本识别,具有较高的准确率和较快的识别速度。根据具体的需求和实际情况,可以选择适合自己的OCR工具。