1. 从https://github.com/BVLC/caffe/通过git clone下载caffe源码,master分支,版本号为09868ac:$ git clone https://github.com/BVLC/caffe.git ;
2. 先使用cmake-gui构建生成vs2013工程,发现有很多错误,提示缺少各种依赖库,根据错误提示,分别编译各种依赖库,下面通过vs2013安装、编译各种依赖库;
3. 安装、配置NVIDIA CUDA 7.0(网上说使用GPU和不使用,速度上caffe至少要差10倍左右,如果想不使用GPU,在cmake-gui中勾选CPU_ONLY即可):可以参考http://blog.csdn.net/fengbingchun/article/details/44963681;
4. 安装、配置Boost:Boost库是一个可移植、提供源代码的C++库,它是为C++语言标准库提供扩展的一些C++程序库的总称:
(1)、从http://sourceforge.net/projects/boost/files/boost/1.58.0/下载Boost稳定版本1.58.0,如果不想自己编译Boost源码,则从http://sourceforge.net/projects/boost/files/boost-binaries/1.58.0/直接下载对应的二进制文件即可,我这里下载的是boost_1_58_0-msvc-12.0-64.exe ;
(2)、双击进行安装,将其安装到D:\ProgramFiles\local\boost_1_58_0目录下;
(3)、将D:\ProgramFiles\local\boost_1_58_0\lib64-msvc-12.0添加到系统环境变量Path中;
(4)、添加系统变量,变量名:BOOST_1_58_0,变量值:D:\ProgramFiles\local\boost_1_58_0,重启电脑;
5. 从https://github.com/gflags/gflags下载GFlags,解压缩,编译GFlags,google gflags是google使用的一个开源库,用于解析命令行标记:
(1)、打开cmake-gui,source code路径:E:/GitCode/Caffe/src/thirdparty/GFlags/gflags-master和build thebinaries路径:E:/GitCode/Caffe/src/thirdparty/GFlags/vs2013 ;
(2)、点击Configure,选择Visual Studio 12 2013 Win64;
(3)、CMAKE_INSTALL_PREFIX设置为::/GitCode/Caffe/src/thirdparty/GFlags/install;
(4)、点击Generate,生成vs2013gflags.sln工程;
(5)、打开gflags.sln工程,分别在x64Debug和x64 Release下,点击ALL_BUILD,重新生成;点击INSTALL,生成;手动拷贝生成的库和头文件放在/install/include和/install/lib目录下;
6. 从https://github.com/google/glog下载GLog,解压缩,编译GLog,google glog是一个记录日志信息的c++库:
(1)、用vs2013打开google-glog.sln工程,需要升级到vs2013版本;
(2)、原始工程只有win32配置,需要手动添加Debug 和Release x64配置;
(3)、分别在Debug和Release下,选中解决方案google-glog,重新生成解决方案,会在/glog-master/x64目录下生成Debug和Release两个子目录,将其里面相应的库拷贝到/GLog/install相应目录下;
(4)、将源码中的.h文件拷贝到相应的/GLog/install/目录下;
7. 从https://github.com/bureau14/leveldb下载LevelDB,解压缩,编译LevelDB,它是一个google实现的非常高效的kv数据库:
(1)、打开cmake-gui,source code路径:E:/GitCode/Caffe/src/thirdparty/LevelDB/leveldb-master和build thebinaries路径:E:/GitCode/Caffe/src/thirdparty/LevelDB/vs2013 ;
(2)、点击Configure,选择Visual Studio 12 2013 Win64;
(3)、点击Advanced,将Boost_INCLUDE_DIR设置为D:/ProgramFiles/local/boost_1_58_0/,将CMAKE_INSTALL_PREFIX设置为E:/GitCode/Caffe/src/thirdparty/LevelDB/install,再次点击Configure;
(4)、点击Generate,生成vs2013 leveldb.sln工程;
(5)、打开leveldb.sln工程,分别在x64 Debug和x64 Release下,点击ALL_BUILD,重新生成;点击INSTALL,生成;手动拷贝生成的库和头文件放在/install/include和/install/lib目录下;
8. 从https://github.com/LMDB/lmdb下载LMDB,解压缩,编译LMDB,Lightning Memory-Mapped Database:
(1)、打开vs2013,新建一个名称为lmdb的空项目;
(2)、将lmdb中的相应.c文件和.h文件加入到此项目中;
(3)、打开属性页,分别在Debug和Release下将其配置类型改为:静态库(.lib);
(4)、配置x64选项;
(5)、从http://4201a5.l67.yunpan.cn/lk/ccWF2Zge3tyfb密码是6147,下载3rdparty-2015.7.18.zip,将里面的unistd.h、getopt.h、getopt.c三个文件复制到lmdb源码并加入工程中;
(6)、修改属性,将C/C++下SDL检查设为否(/sdl-),并且将_CRT_SECURE_NO_WARNINGS、_CRT_SECURE_NO_DEPRECATE、_CRT_NONSTDC_NO_DEPRECATE三个宏添加到预处理定义中;
(7)、分别在Debug和Release下编译,生成lmdb.lib库,将其库和相应的头文件,拷贝到/install/include和install/lib相应目录下;
9. 从https://github.com/google/protobuf下载ProtoBuf,解压缩,编译ProtoBuf,它是一种轻便高效的结构化数据存储格式:
(1)、打开Cmake-gui,source code路径:E:/GitCode/Caffe/src/thirdparty/ProtoBuf/protobuf-master/cmake和build thebinaries路径:E:/GitCode/Caffe/src/thirdparty/ProtoBuf/vs2013;
(2)、点击Configure,选择Visual Studio 12 2013 Win64;
(3)、去掉BUILD_TESTING的勾选,将CMAKE_INSTALL_PREFIX设置为E:/GitCode/Caffe/src/thirdparty/ProtoBuf/install,再次点击Configure;
(4)、点击Generate,生成vs2013 protobuf.sln工程;
(5)、打开protobuf.sln工程,分别在x64 Debug和x64 Release下,点击ALL_BUILD,重新生成;点击INSTALL,生成;手动拷贝生成的库和头文件放在/install/include和/install/lib目录下,将protoc.exe放在/install/bin目录下;
10. 从https://www.hdfgroup.org/HDF5/release/obtainsrc.html下载HDF5,解压缩,编译HDF5,它是一个层次型的数据存储格式:
(1)、打开cmake-gui,source code路径:E:/GitCode/Caffe/src/thirdparty/HDF5/hdf5-1.8.15-patch1和build thebinaries路径:E:/GitCode/Caffe/src/thirdparty/HDF5/vs2013;
(2)、点击Configure,选择Visual Studio 12 2013 Win64;
(3)、再次点击Configure,点击Generate,生成HDF5.sln工程;
(4)、打开HDF5.sln工程,分别在x64 Debug和x64 Release下,点击ALL_BUILD,重新生成;手动拷贝生成的库和头文件放在/install/include和/install/lib目录下;
11. 从https://github.com/google/snappy下载snappy,解压缩,从https://github.com/kmanley/snappy-msvc下载snappy-msvc,解压缩,它是一个用C++实现的用来压缩和解压缩的库:
(1)、打开snappy-msvc-master目录下的snappy.sln工程,升级到vs2013;
(2)、添加x64解决方案平台;
(3)、从http://www.maspick.co.il/ddd/chromium/src/third_party/snappy/win32/snappy-stubs-public.h下载snappy-stubs-pulic.h文件,将其拷贝到/snappy-master目录下;
(4)、解决工程的error C2589:打开snappy属性页,分别在Debug和Release下,预处理定义中添加NOMINMAX;
(5)、在Debug和Release下,分别点击snappy工程,重新生成,会生成snappy.lib静态库;
(6)、将生成的静态库和头文件拷贝到/install/include和/install/lib目录下;
12. 编译不带CUDA支持的OpenCV2.4.9 x64动态库:可以参考http://blog.csdn.net/fengbingchun/article/details/8778121;
13. 从http://sourceforge.net/projects/openblas/files/v0.2.14/下载OpenBLAS-v0.2.12-Win64-int64.zip,解压缩,它是一个优化的Blas库,将里面的libopenblas.dll.a改成libopenblas.lib;
14. 使用CMake(cmake-gui)生成Caffe.sln工程:暂时没有成功,先作个记录,后面有时间再调试吧
(1)、打开vs2013,新建一个空项目caffe-vs2013,分别在Debug和Release下,配置解决方案平台为x64,将配置属性中的配置类型改为动态库(.dll);
(2)、利用ProtoBuf中的protoc.exe,通过/caffe/caffe/src/caffe/proto/caffe.proto文件生成caffe.pb.h和caffe.pb.cc:打开命令提示符,将protoc.exe拷贝到/proto目录下,执行:protoc.exe caffe.proto --cpp_out=./ ;
(3)、在/caffe/caffe/include/caffe目录下新建一个proto子目录,将caffe.pb.h和caffe.pb.cc两个文件拷贝到此目录下;
(4)、打开cmake-gui,source code路径:E:/GitCode/Caffe/src/caffe/caffe和build the binaries路径:E:/GitCode/Caffe/src/caffe/vs2013;
(5)、点击Configure,选择Visual Studio 12 2013 Win64;
(6)、设置Boost_INCLUDE_DIR为D:/ProgramFiles/local/;
(7)、设置GFlags选项见下图:

(8)、设置GLog选项见下图:

(9)、设置ProtoBuf选项见下图:

(10)、设置HDF5选项见下图:

(11)、设置LMDB选项见下图:

(12)、设置LevelDB选项见下图:

(13)、设置Snappy选项见下图:

(14)、设置OpenCV_DIR为D:/soft/OpenCV2.4.9/opencv/sources;
(15)、设置OpenBLAS选项见下图:

(16)、再次点击Configure,点击Generate,生成Caffe.sln工程。
15. 上面直接用CMake没有成功,下面手动添加生成Caffe.sln工程:
(1)、用vs2013新建一个控制台空工程caffe-vs2013,解决方案平台由Win32设置成x64;
(2)、设置CUDA支持:项目(P) -> 生成自定义(B)… -> 勾选CUDA 7.0(.targets, .props),点击确定,默认先使用不支持GPU进行编译,在工程中添加CPU_ONLY宏;
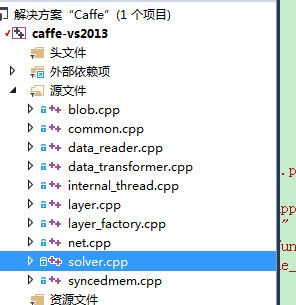
(3)、添加/caffe/src/caffe目录下的文件逐个进行编译,先编译/src/caffe当前目录下的10个.cpp文件,如下图:
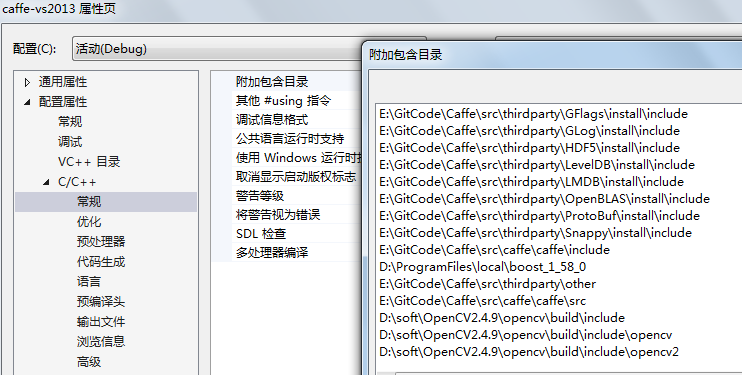
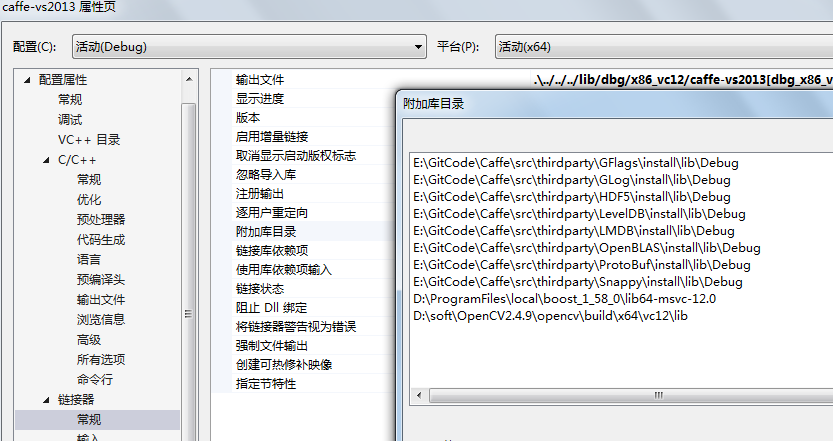
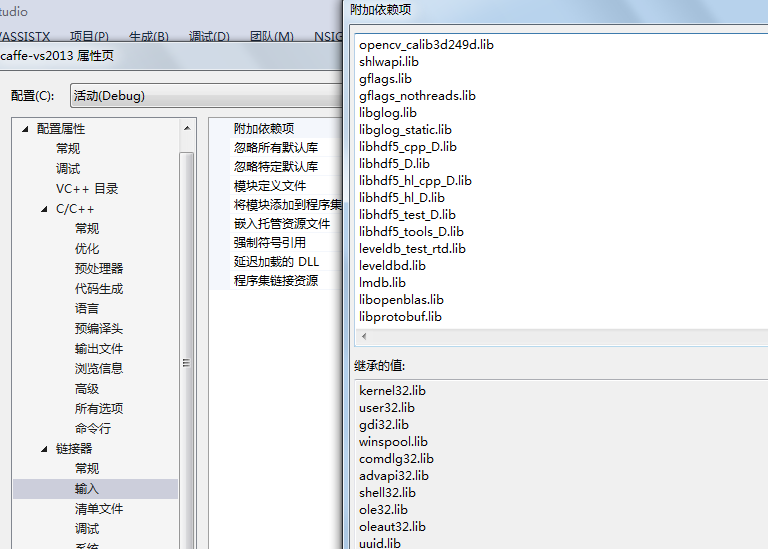
(4)、caffe所有的依赖文件全部放在thirdparty目录下,将相应的头文件以及库文件加入到工程中,见下图:
(5)、对以上11个.cpp文件逐个进行编译,根据错误提示进行逐一解决;
(6)、将/caffe/src/caffe/layers目录下的.cpp文件加入到工程中,进行编译;
(7)、将/caffe/src/caffe/util目录下的.cpp文件加入到工程中,进行编译;
(8)、将/caffe/src/caffe/proto目录下的.cpp文件加入到工程中,进行编译,此.cc文件由上面的14.2步骤生成;
16. 编译caffe-vs2013工程,生成caffe-vs2013动态库。
说明:
(1)、以上能够正确生成caffe-vs2013动态库,但是使用的时候发现光动态库,并没有对应的静态库产生。因此为了调用的方便将工程改为生成静态库,修改方法为:将工程属性 -> 常规 -> 配置类型,由原来的动态库(.dll)改为静态库(.lib)即可,其它均无需修改,或者自己新创建一个静态库工程,将相关caffe文件加入到工程中;
(2)、若想使生成的caffe静态库能够在windows下正常使用,还需几个额外的动态库,可以直接从 https://drive.google.com/file/d/0B_G5BUend20PTEJ0cGIyZ0czVmc/view 下载。
GitHub:https://github.com/fengbingchun/Caffe_Test
参考文献:
1. https://initialneil.wordpress.com/
2. http://wenku.baidu.com/link?url=ik_0Yf6ZixtG10cXXoaDRkTVrDNf9o3mmAI8-c48AhKunsOHX0JNSG_e4yVMiH9TVcZuxggQqqMC5HhAZ46KSaAs4kmCSRfD3taWpbksDv7