论文链接:https://arxiv.org/pdf/2108.08810.pdf
出处:NeurIPS2021
一、背景
Transformer 现在在视觉方面取得了超越 CNN 的效果,所以作者就有一个问题:Transformer 是如何处理视觉的相关任务的呢?
基于此,作者对 ViT 和 CNN 在分类任务上进行了一系列分析,发现两者有着很大的不同。
- ViT 在所有层上都有更一致的表达特征,而造成这一现象的原因在于 self-attention,self-attention 能够在浅层就聚合全局特征。
- 而且残差连接对于特征从底层到高层的传递起了很大的作用
- ViT 能更好的保持输入的空间信息
二、方法
作者在 JFT-300M 数据集上对 ResNet50x1, ResNet152x2, ViT-B/32, ViT-B/16, ViT-L/16 和 ViT-H/14 进行了对比。
作者使用了两个度量方式进行特征对比:
- Representation Similarity
- CKA (centered kernel alignment):CKA 是一种相似性指数,可以定量的对比网络之间的特征表达。
CKA 的输入:两层不同网络的特征表达
X
∈
R
m
×
p
1
X\in R^{m\times p_1}
X∈Rm×p1 和
Y
∈
R
m
×
p
2
Y\in R^{m\times p_2}
Y∈Rm×p2
每层网络内部的特征相似度:
K
=
X
X
T
K=XX^T
K=XXT,
L
=
Y
Y
T
L=YY^T
L=YYT
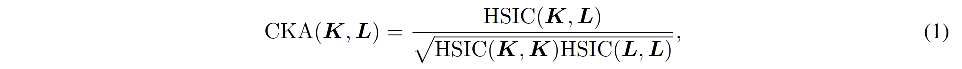
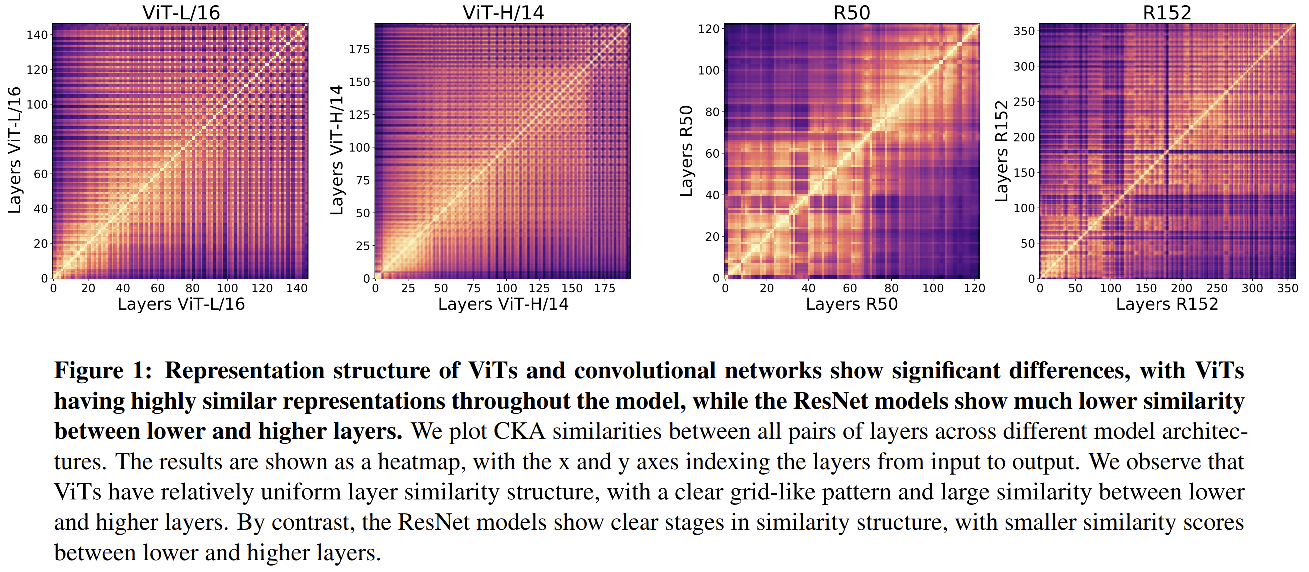
1、ViT 和 ResNet 内部层相似度的对比
图 1 展示了 ViT 和 ResNet 的中间层和最后一层输出的 CKA 相似性图:
- ViT 的相似性更有一致性,是整洁的棋盘格,颜色越亮,相似性越大,每层网络和自己的相似性是最大的,所以对角线最亮。
- ViT 的低层和高层相似度比 ResNet 的低层和高层相似度更高一些
- ResNet 不同 stage 的相似度有很大不同,低层和低层相似度大,高层和高层相似度大
2、ViT 和 ResNet 层间相似度的对比
作者通过图 2 发现:
- ResNet 的前 60个层和 ViT 的前1/4层(约前40层)相似度较大
- ResNet 的后半部分层和 ViT 的中间 1/3 层相似度较大
- ViT 的最后 1/3 层和 ResNet 的层相似度都较低,这可能是由于这些层主要是再抽取 cls token 的特征。
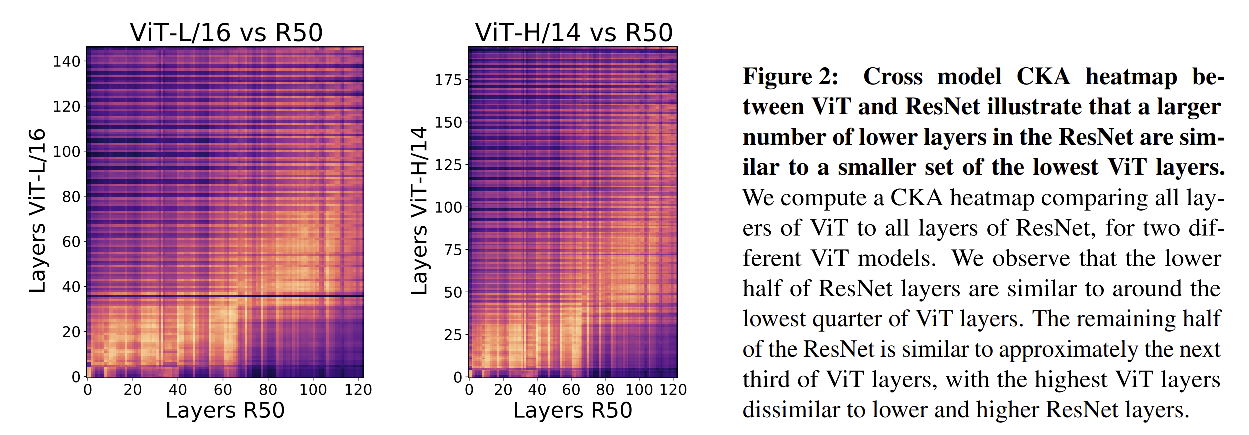
上图表明:
- ViT 的低层和 ResNet 的低层特征是有较大不同的
- ViT 能够较强的在低层和高层间进行特征传递
- ViT 的高层和 ResNet 的高层表达有较大的不同
3、聚合全局特征能力的对比
上面对比了两个不同的结构的层间相似性,作者发现 ViT 的低层和高层的特征更具有一致性,而 ResNet 需要使用更多的层来达到和 ViT 类似的特征表达效果。所以作者就从两种结构对于全局信息的聚合程度来找原因。
分析attention的距离:
ViT 提取全局特征的能力主要来源于 self-attention,所以作者计算了 query patch 位置和其关注到的位置的平均距离,这能够反映出来 self-attention layer 为该特征表达聚合了多少局部和全局的信息。
作者对每个 attention head 使用 attention weight 来衡量其 pixel distance,对 5000 个数据点做了平均,可视化结果如图 3 所示。作者发现,尽管在 ViT 的很浅的层,self-attention 就能够同时有 local heads(小距离)和 global heads(长距离)特征,而 ResNet 在浅层只有局部特征,在高层所有的 self-attention heads 都是 global 的。
下图中,两个偏绿色的是高层的head,两个偏蓝色的是低层的head。
低层的不同 head 会分工关注长距离/短距离的特征,高层的不同 head 基本都关注于长距离特征。
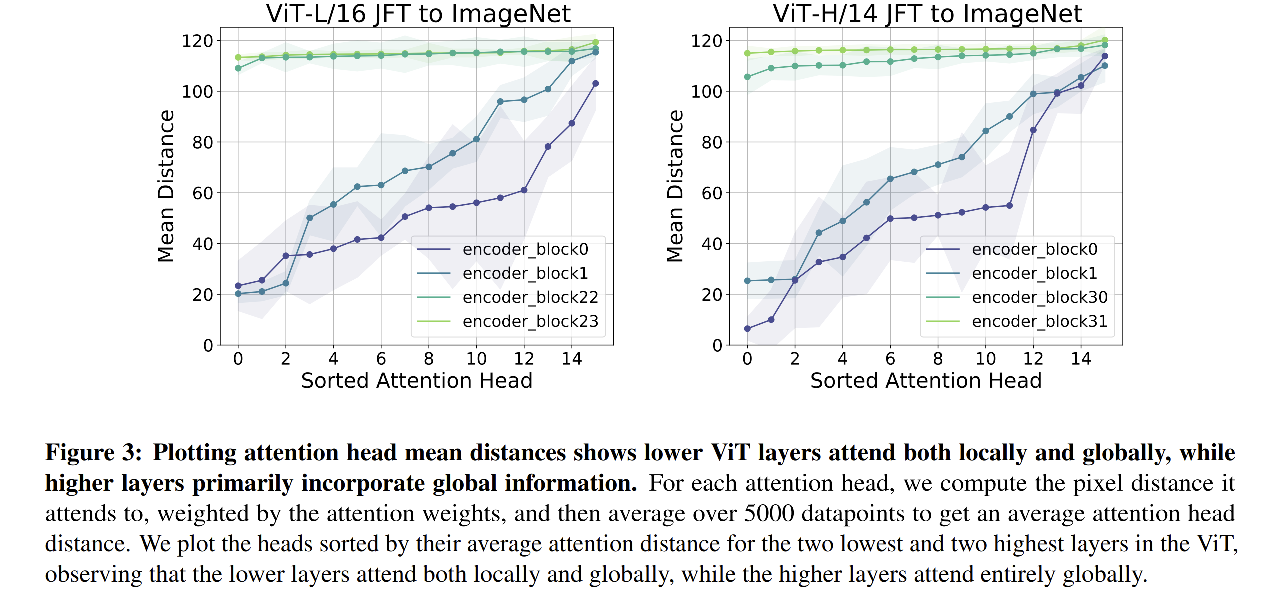
同样的,从图 4 可以发现,当仅仅在 ImageNet 上训练时(没有大尺度数据的预训练),ViT-L/16 和 ViT-H/14 效果都不太好,结合图 3 来看,可以知道当没有大量的数据时,ViT 无法在浅层学习到局部的特征。这也说明,在浅层中尽早的使用 local 信息,对网络的效果尤为重要。
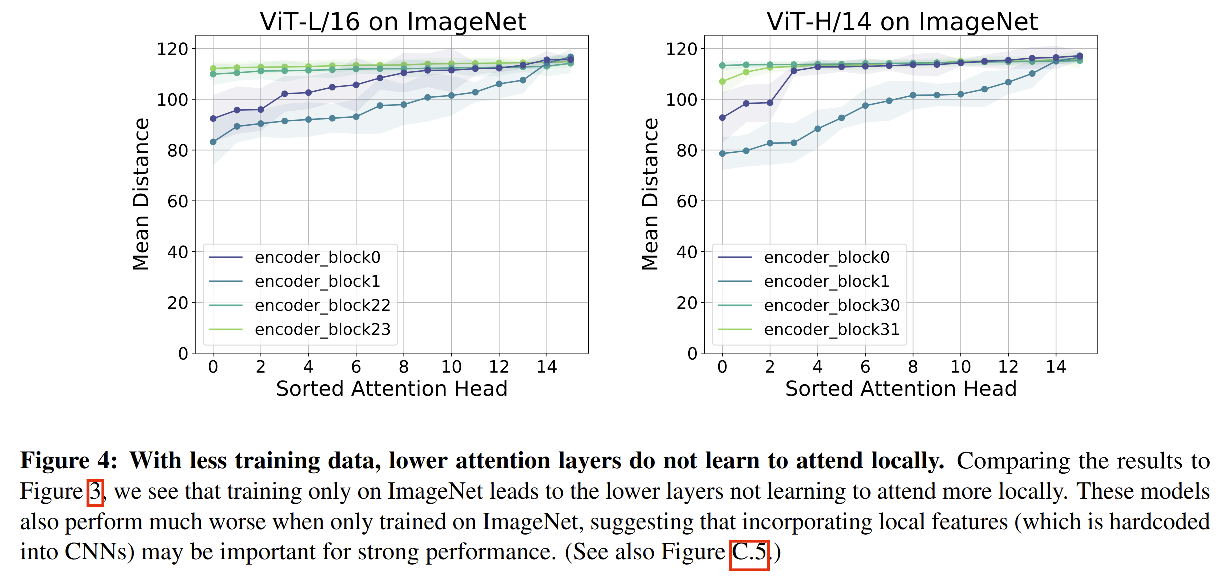
分析全局信息的不同是否会导致学习到的特征不同:
从图 5 可以看出,随着 mean distance 的增加,CKA 相似性会逐步减小,这也说明, global 信息学习到的特征和使用 local 信息学习到的特征有较大的不同。
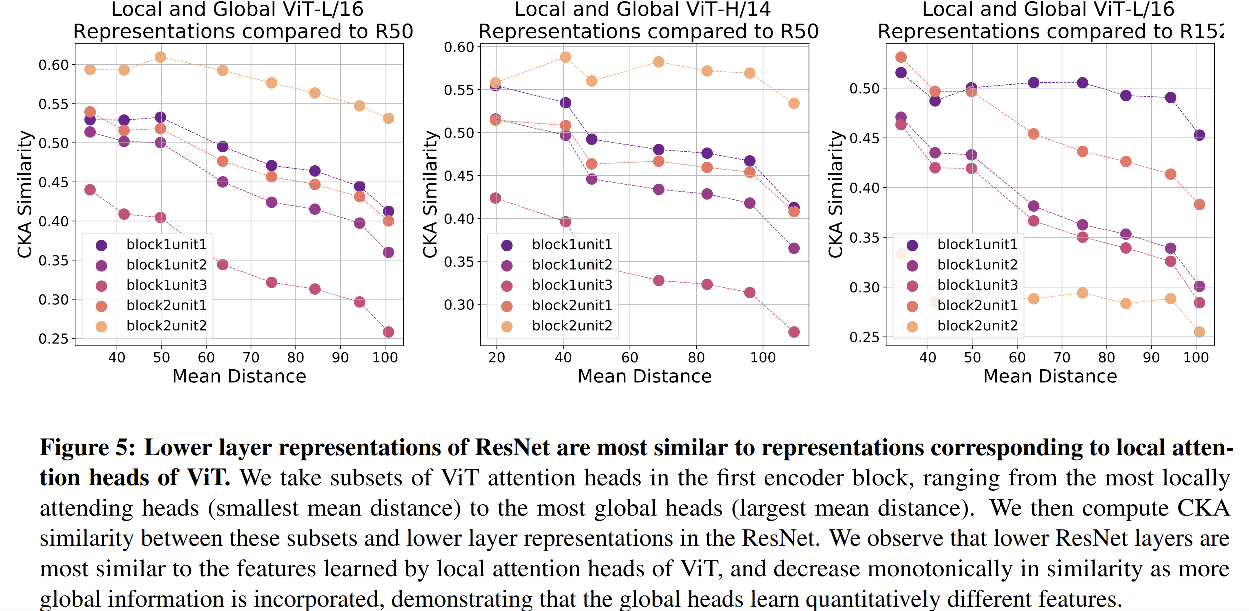
分析感受野大小:
从图 6 中可以看出,ViT 在低层的时候,就已经能够有比 ResNet 更大的感受野,尽管 CNN 的感受野会逐步增大,但 ViT 的感受野也会同时增大。
并且,ViT 的感受野也强依赖于其 center patch(由于残差结构的存在)。
4、残差连接对特征传播的影响
既然 ViT 的浅层和深层的特征具有高度一致性,那么也就说明浅层的特征很好的传递到了高层。作者证明了残差连接对这一现象的影响,同时发现其有保存 cls token 特征(浅层)到spatial token 特征(高层)的 phase transition。
作者使用 norm ratio (
∣
∣
z
i
∣
∣
/
∣
∣
f
(
z
i
)
∣
∣
||z_i||/||f(z_i)||
∣∣zi∣∣/∣∣f(zi)∣∣) 来作为展示,
z
i
z_i
zi 是第 i 层的隐层特征(直接来自于残差结构的输出),
f
(
z
i
)
f(z_i)
f(zi) 是经过长分支(mlp等)处理后的。
在网络的前半部分,cls token(token 0)特征是主要通过残差连接来传递的(high norm ratio),但 spatial token 特征的很大贡献来自长分支(lower norm ratio),在后半部分是相反的。
-
ratio 越小(下图颜色越暗),假设为 1 的时候,那么说明经过长分支后处理后的与未处理的特征一致性越大。
spatial token 在浅层 ratio 小,高层 ratio 大,说明浅层主要靠长分支来进行特征传递,在深层主要靠残差连接来传递信息。
-
ratio 越大(下图颜色越亮),假设为 12 的时候,那么说明两者一致性越小。
token 0(cls token)在浅层颜色亮,说明其 ratio 越大,所以在浅层 cls token 的特征主要是靠残差连接来传递的,在深层主要靠长分支来传递信息。
图 7 右半部分展示了不同结构的 norm ratio,说明跳连结构对于 ViT 比 ResNet 更重要。
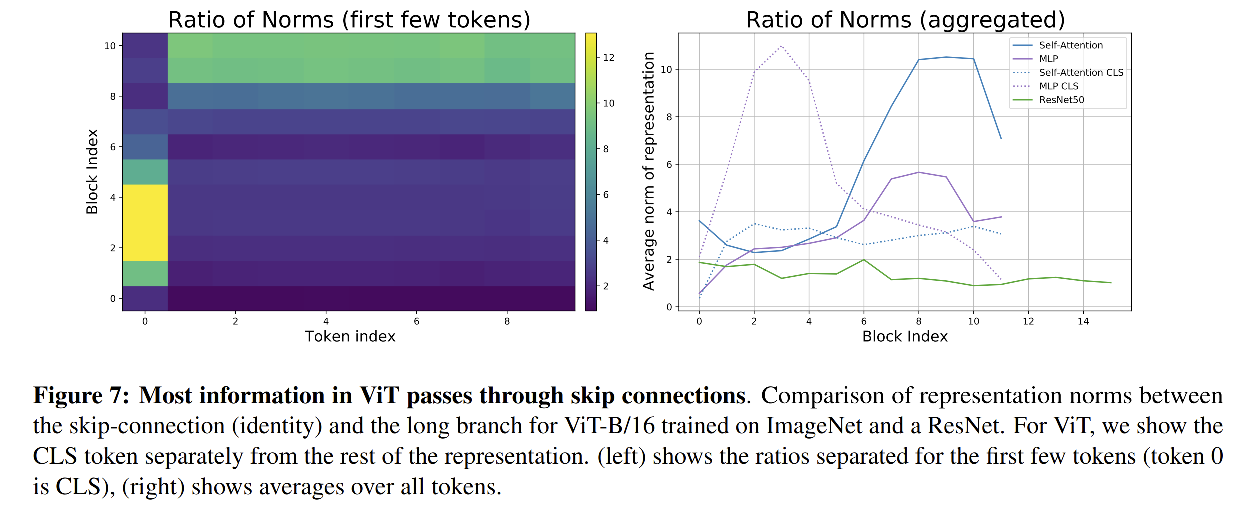
图 8 展示了 ViT 不使用跳连结构的效果,在中间的 block 移除残差结构会导致 4% 的性能下降。

ViT 如何学习空间信息来定位
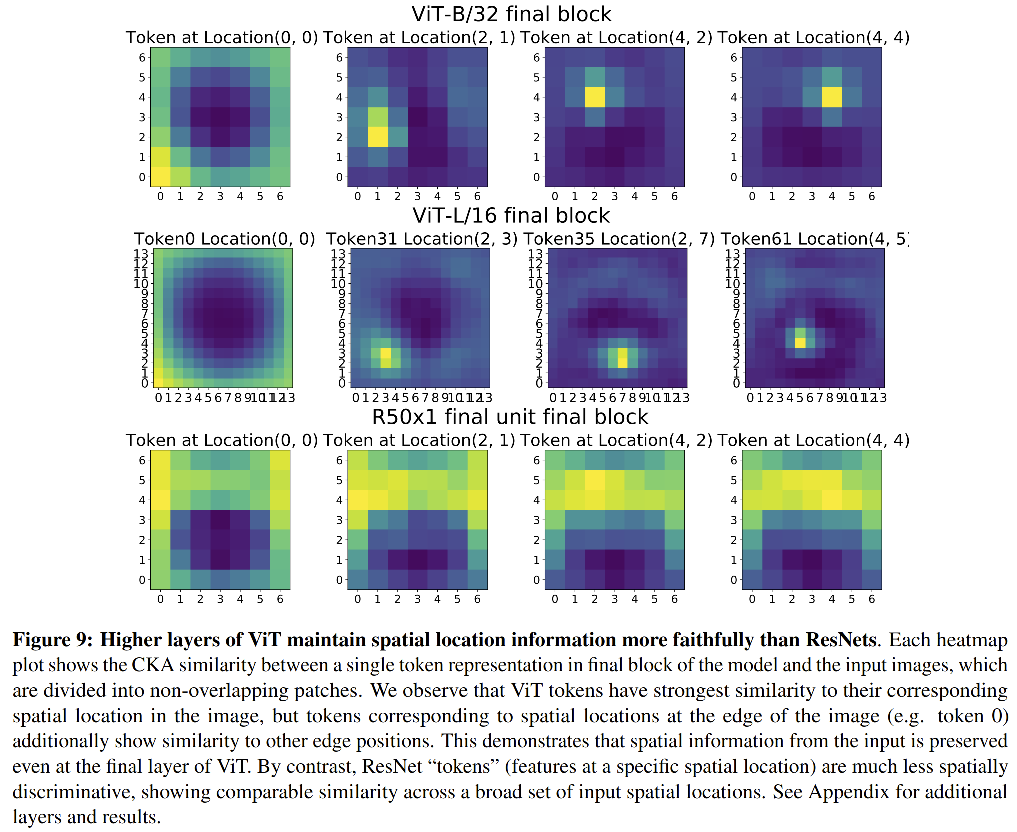
作者从对比 ViT(ResNet)的高层特征和输入 patch 来开始探索
对于ViT token有一个对应的输入 patch,因此有一个对应的输入空间位置。图 9 说明 ViT token 和其对应的图像中的空间位置有很强的相似性。
对于ResNet,作者定义在一个特定位置上的所有卷积通道为一个 token, 这也给了它一个相应的输入空间位置。然后,我们可以取一个 token,并计算其和输入图像 patch 在不同的位置的CKA得分。图9展示了不同标记(标记了它们的空间位置)的结果。
对于 ViT,可以看出在边缘附近的 token 的位置和 image patch 的位置很近似,而且在内部的 token 也被很好的定位了。但是 ResNet 的定位能力较弱。
究其差别,ResNet 是使用 global average pooling 来实现分类,而 ViT 是使用 cls token 来进行分类的,基于此,作者对 ViT 使用 GAP 训练,如图 10 所示,结果说明 GAP 确实会降低高层特征的定位能力。
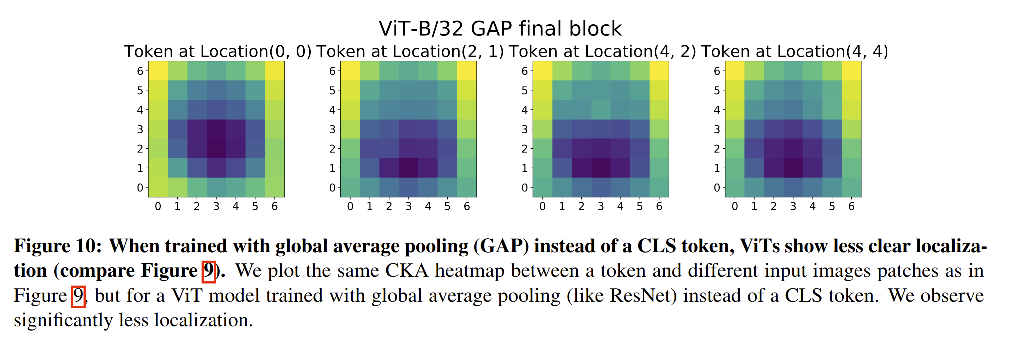
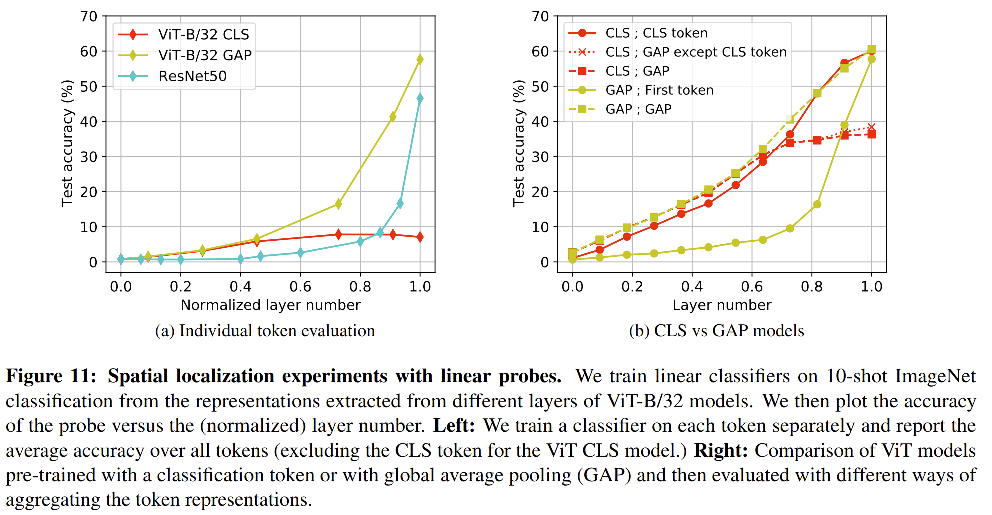
图 11 左半边图对比了单独训练每个token的分类平均准确率,ViT GAP 和 ResNet50在高层表现的较好,使用 CLS 训练的 ViT 效果较差,可能是由于他们的空间位置特征在高层被保留下来了,导致全局分类较差。
图 11 右半边图说明了使用 ViT-GAP 的单个 token 获得的效果可以和使用全部token合并起来的效果相抗衡,结合图9可知,GAP model 中的所有高层的 token 学习到了类似的全局特征表达。