FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding
以Faster RCNN 作为小样本目标检测的基本框架,采用两阶段的训练方法——第一阶段的训练集是大量标注的基本类别数据,第二阶段采用少量的基础类别和新类别进行微调。在 Faster RCNN 的 RoI feature extractor 后除了回归和分类损失,还添加了一个建议框对比编码(CPE)损失。

参考链接:
https://blog.csdn.net/qq_38701106/article/details/121151422
https://blog.csdn.net/qq_38701106/article/details/121151422?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1.no_search_link&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1.no_search_link
contrastive predictive coding ------------ CPC领域
在两阶段检测框架中,RPN将骨干特征映射作为输入并生成区域建议框,然后RoI head对每个区域建议框进行分类,如果预测包含对象,则对边界框进行回归。
Roi cls是进行分类,输出概率值;
该篇文章使用对比分支来增强感兴趣区域(RoI)的头部,对比分支度量目标提议编码之间的相似性。
即,contrastive head 进行特征处理之后::在MLP头部编码的RoI特征上,测量目标建议框表示之间的相似性分数。 并优化对比目标, 以最大化来自同一类别的目标建议框之间的一致性,并提高来自不同类别建议框的区别性。
将优化具有特定检测考虑的监督对比目标,以减少来自同一类别的目标建议框提取特征的差异,同时使不同类别实例彼此远离。

上图中,N个mini-batch, N个proposal;
p下标:∈ [0, n] ;y下标:∈ [0, m] ;
在loss中,特征z与标签y的下标一致;
在进行CPE LOSS之前,针对提取的特征Pi,已经进行了label的预测---------------bbox与cls的Loss ;
Contrastive Proposal Encoding (CPE) Loss

f(·)controls the consistency of proposals;
g(·) assigns different weight coefficients for object proposals with different level of IoU scores.
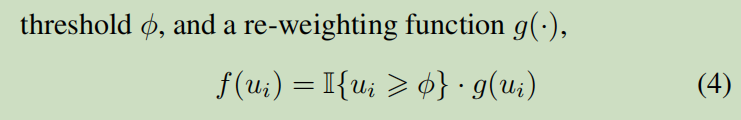
u----IOU score ::::
预测x, y, w, h之后,bbox与真实框进行了对比,然后使用f(·)进行框的阈值的筛选,排除不必要信息;去掉低阈值的框之后,进行预测框(同类别)之间的对比;
还是指,对比损失里的真实框,其实都是预测框之间的比较,非预测框与真实标签之间的对比;
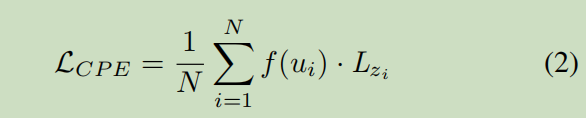
N个 ---- {z, u, y}
z----feature
y----label of GT
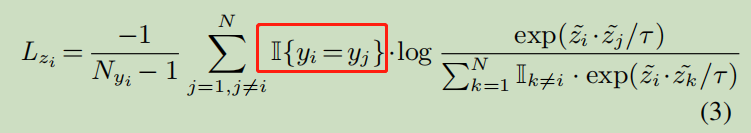
Nyi----是有几个yi
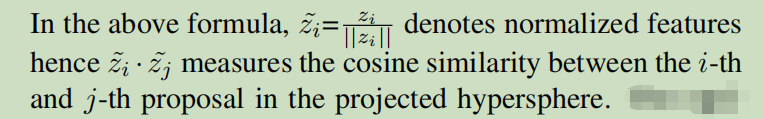
公式3----假设 i=3时,N个特征中,除却3,进行与其他N-1个特征的相似度计算; 分母不变,相似度越高,分子越大,loss越小;相似度低,loss越大;
红框公式约束label;约束 标签相同?
同类别(根据label判断)的特征向量之间的相似度;
分母: 计算一个batch中所有特征向量之间的相似度之和;
目标是让同类特征向量之间的相似度为1,不同类特征向量之间的相似度为0
公式类似于交叉熵与softmax ;
交叉熵:
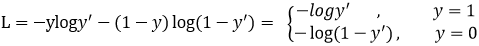
对于正样本而言,输出概率越大损失越小。[下图红线,[0, 1] ---- 区间 ]
对于负样本而言,输出概率越小则损失越小。

Softmax:

--------------------分割线------
reid–度量学习中:对比损失 (Contrastive loss );其实都是为了匹配相似性;
