目录
数据集
简介
代码
(1)数据的读入
(2)数据理解
(3)数据规整化处理(数据准备)
(4)数据建模
(5)查看模型
(6)模型预测
(7)结果输出
数据集
https://download.csdn.net/download/llf000000/86724465
简介
机器学习最担心的事情:过拟合(训练出模型在训练集里准确率非常高,在测试机上的准确率非常低)(平时成绩很好,考试很差)。
验证集:算法选择,参数调整

以下是每一个国家对不同食品的消费量

使用聚类的方法判断出哪些国家饮食结构是相似的

聚类和分类是不一样的概念:
分类的特点是:工作开始之前你知道每个类的名字是什么,比如分男女
聚类的特点是:把我们班的同学的性格聚类一下,类别的个数和名称我们在工作之前都不知道。
代码
(1)数据的读入
# 读入数据
import pandas as pd
protein = pd.read_table('data/protein.txt', sep='\t')
#之前访问的数据都是csv文件,现在我们访问的数据是txt文件
#'\t'是txt文件的分隔符,是tab键来分割的
# 查看前5条数据
protein.head()

(2)数据理解
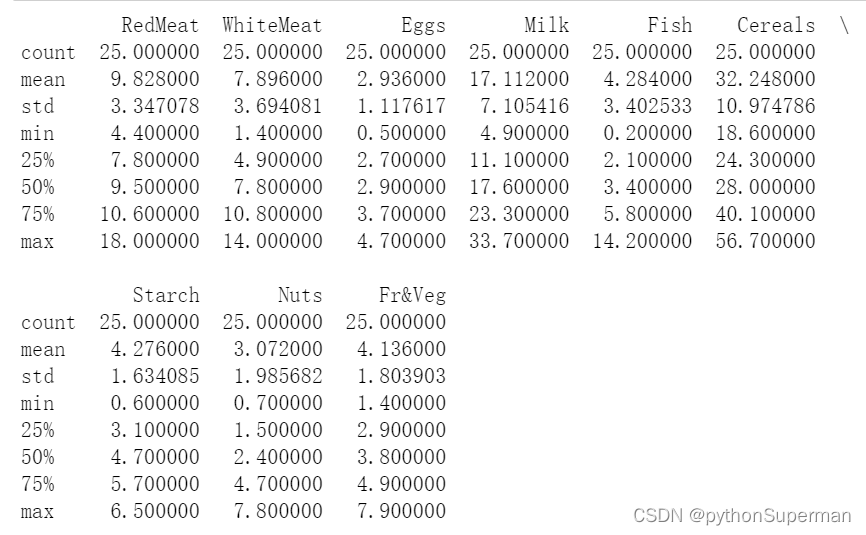
# 查看描述性统计分析
print(protein.describe())
# 查看列名
print(protein.columns)
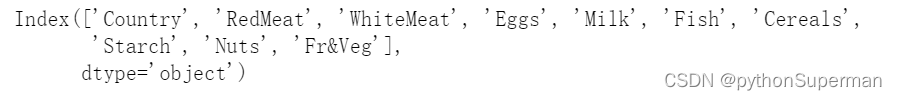
# 查看行数和列数
print(protein.shape)

(3)数据规整化处理(数据准备)
现在我们有很多的自变量,但是自变量的取值范围不同,所以我们需要对这些数据进行规整化,做一下标准化处理,需要把这些值都映射到同一区间之内。
-
## 1.单列drop,就是删除某一列
-
a = df.drop('A',axis=1)
-
print(a)
-
## 2.单列drop,就是删除某一行
from sklearn import preprocessing
# 由于Country不是一个特征值,应删掉
#
sprotein = protein.drop(['Country'], axis=1)
# 对数据进行标准化处理
sprotein_scaled = preprocessing.scale(sprotein)
# 查看处理结果
print(sprotein_scaled)

(4)数据建模
# 导入KMeans类型
from sklearn.cluster import KMeans

列表推导式 :
列表推导式可以快速生成一个列表,并筛选列表的值。

#【注意】K值的选择方法
#将K迭代,从1到20的每个数字依次地去尝试
#首先定义了一个迭代器,定义了1到19的数字
NumberOfClusters = range(1, 20)
kmeans = [KMeans(n_clusters=i) for i in NumberOfClusters]
#kmeans = [KMeans(n_clusters=i) for i in range(1, 20)]
print(kmeans)
score = [kmeans[i].fit(sprotein_scaled).score(sprotein_scaled) for i in range(len(kmeans))]
#fit.score()的值:Calinski-Harabasz score——类内的稠密程度(协方差越小越好)和类之间的离散程度(协方差越大越好)来评估聚类的效果
score
#Calinski-Harabasz score每一类的相似度非常高,不同类的相似度非常小


k = 5(或者6)的时候是非常合适的。这就是k值的选择方法,画轴线的方法,拐点那个位置就是k
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(NumberOfClusters,score)
plt.xlabel('Number of Clusters')
plt.ylabel('Score')
plt.title('Elbow Curve')
plt.show()

# 设置KMeans聚类器的超级参数
# KMeans是一个函数
# algorithm是初始结点的选择,“auto”根据数据的特点自动选择
# n_clusters就是k,表示聚类中心
# n_init表示初始结点选择次数,因为一次选择初始结点效果可能不是很好,我们可以选择十次
# max_iter表示迭代次数
myKmeans = KMeans(algorithm="auto",n_clusters=5,n_init=10,max_iter=200)
注意:初始聚类中心的选择方法——init参数,目前init参数的取值可以为:
1)k-means++算法(默认):选择彼此距离尽可能元的K个点
2)随机:random
3)指定:ndarray
# 模型训练
# 我们在标准化的数据上进行训练
myKmeans.fit(sprotein_scaled)
统计学里面称作拟合,机器学习里面称作训练 ,包里头的函数都是统一的,都是fit()

(5)查看模型
# 查看模型
print(myKmeans)

机器学习的很多模型可解释性非常低,但可用性非常高
(6)模型预测
# 预测聚类结果
y_kmeans = myKmeans.predict(sprotein)
print(y_kmeans)

(7)结果输出

def print_kmcluster(k):
'''用于聚类结果的输出
k:为聚类中心个数
'''
for i in range(k):
print('聚类', i)
ls = []
for index, value in enumerate(y_kmeans):
if i == value:#value在这里是标签
ls.append(index)
print(protein.loc[ls, ['Country', 'RedMeat', 'Fish', 'Fr&Veg']])
print_kmcluster(5)#这里是函数而已,不是print的特殊形式
