如何利用CloudCompare软件进行点云数据标注
https://blog.csdn.net/weixin_44603934/article/details/123591370
PointNet++训练自己的数据集(附源码)
http://www.xbhp.cn/news/39384.html
制作PointNet以及PointNet++点云训练样本
https://blog.csdn.net/CC047964/article/details/124345423
分类任务
主模块文件 train_classification.py
源代码
略
训练参数配置
def parse_args():
'''PARAMETERS'''
parser = argparse.ArgumentParser('training')
parser.add_argument('--use_cpu', action='store_true', default=False, help='use cpu mode')
parser.add_argument('--gpu', type=str, default='0', help='specify gpu device')
parser.add_argument('--batch_size', type=int, default=24, help='batch size in training')
parser.add_argument('--model', default='pointnet_cls', help='model name [default: pointnet_cls]')
parser.add_argument('--num_category', default=40, type=int, choices=[10, 40], help='training on ModelNet10/40')
parser.add_argument('--epoch', default=200, type=int, help='number of epoch in training')
parser.add_argument('--learning_rate', default=0.001, type=float, help='learning rate in training')
parser.add_argument('--num_point', type=int, default=1024, help='Point Number')
parser.add_argument('--optimizer', type=str, default='Adam', help='optimizer for training')
parser.add_argument('--log_dir', type=str, default=None, help='experiment root')
parser.add_argument('--decay_rate', type=float, default=1e-4, help='decay rate')
parser.add_argument('--use_normals', action='store_true', default=False, help='use normals')
parser.add_argument('--process_data', action='store_true', default=False, help='save data offline')
parser.add_argument('--use_uniform_sample', action='store_true', default=False, help='use uniform sampiling')
return parser.parse_args()
if __name__ == '__main__':
args = parse_args()
main(args)
执行train_classification.py时传入参数,不传入则使用parse_args()中的默认值,例如:
python train_classification.py --model pointnet2_cls_ssg --log_dir pointnet2_cls_ssg
入口函数main
一些初始操作:创建目录、log、加载训练数据到tensor
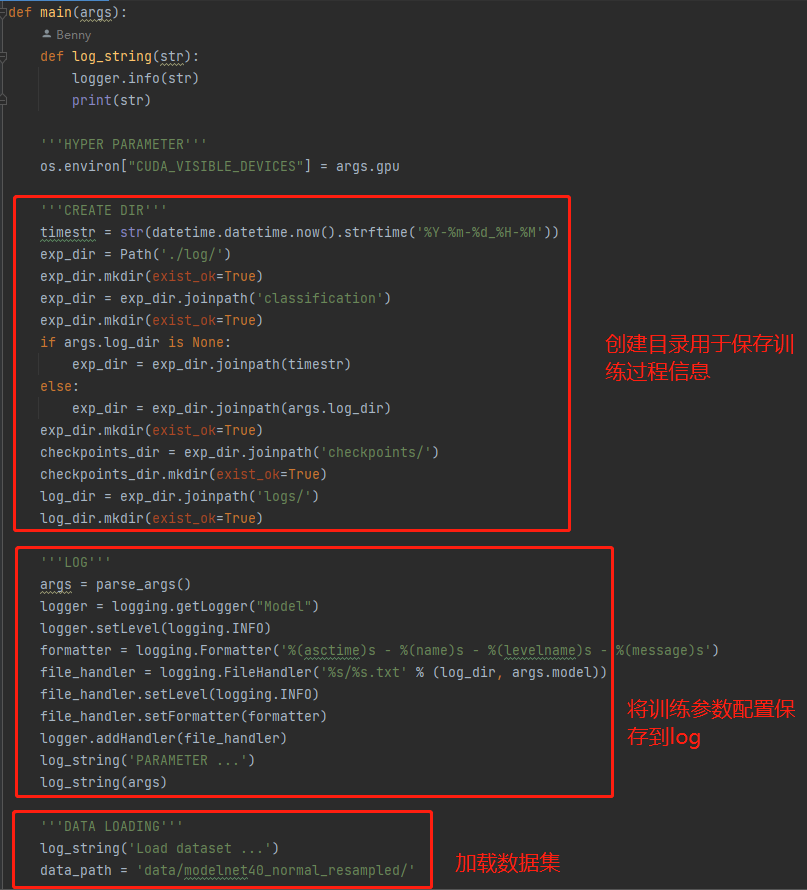
加载数据集
将自己的数据集用函数ModelNetDataLoader加载成合适的tensor形式,再用torch.utils.data.DataLoader将该tensor格式化为torch可使用的形式。

其中ModelNetDataLoader函数要根据具体的数据集来确定实现逻辑:数据集 ~> tensor
最远点采样FPS代码解析
注意:一般深度学习框架中都会使用批操作,来加速收敛。
因此采样函数的输入输出应当也要包含批。
def farthest_point_sample(xyz, npoint):
"""
Input:
xyz: pointcloud data, [B, N, C]
npoint: number of samples
Return:
centroids: sampled pointcloud data, [B, npoint, C]
"""
device = xyz.device
B, N, C = xyz.shape
S = npoint
centroids = torch.zeros(B, S, dtype=torch.long).to(device)
distance = torch.ones(B, N).to(device) * 1e10
farthest = torch.randint(0, N, (B,), dtype=torch.long).to(device)
batch_indices = torch.arange(B, dtype=torch.long).to(device)
for i in range(S):
centroids[:, i] = farthest
centroid = xyz[batch_indices, farthest, :].view(B, 1, 3)
dist = torch.sum((xyz - centroid) ** 2, -1)
mask = dist < distance
distance[mask] = dist[mask]
farthest = torch.max(distance, -1)[1]
return centroids
知识储备
pytorch、python知识点
- nn.BatchNorm1d:批数据的归一化,详细说明可参考这里。
-
最远点采样 ( Farthest Point Sampling )
本质:一句话概括就是不断迭代地选择距离已有采样点集合的最远点。
最远点采样(Farthest Point Sampling)是一种常用的采样算法,特别是在激光雷达3D点云数据中。这篇文章介绍最远点采样方法在一维、二维、三维点集中的使用。附有numpy写的代码和实例。
FPS算法原理步骤:
- 输入点云有N个点,从点云中选取一个点P0作为起始点,得到采样点集合S={P0}。
- 计算所有点到P0的距离,构成N维数组L,从中选择最大值对应的点作为P1,更新采样点集合S={P0,P1}。
- 计算所有点到P1的距离,对于每一个点Pi,其距离P1的距离如果小于L[i],则更新L[i] = d(Pi, P1),因此,数组L中存储的 一直是每一个点到采样点集合S的最近距离。
- 选取L中最大值对应的点作为P2,更新采样点集合S={P0,P1,P2}。
- 重复2-4步,一直采样到N’个目标采样点为止。
ModelNet40数据集介绍
ModelNet40数据集是用于分类的点云数据集,包含了40个类别,训练集有9843个点云数据,验证集有2468个点云数据,数据集目录结构如下:

更多介绍请点击
代码实现(基于pytorch)
环境配置
(1)Windows系统
python 3.8 cuda 11.1 pytorch 1.8.0 torchvision 0.9.0
(2)ubuntu系统
python 3.7 cuda 11.1 pytorch 1.8.0 torchvision 0.9.0
代码解析
可参考
目录结构
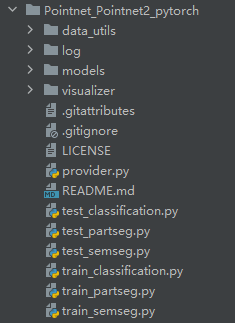
models:网络模型,如分割模型,分类模型,pointNet模型,pointNet++模型等
log??
data_utils??
visualizer:可视化
README
对于版本迭代的说明。
略…
工具链的安装
The latest codes are tested on Ubuntu 16.04, CUDA10.1, PyTorch 1.6 and Python 3.7:
conda install pytorch==1.6.0 cudatoolkit=10.1 -c pytorch
分类任务运行指南
下载数据集
- Data Preparation
Download alignment ModelNet here and save in data/modelnet40_normal_resampled/.
运行代码