HDFS允许用户数据组织成文件和文件夹的方式,它提供一个叫DFSShell的接口,使用户可以和HDFS中的数据交互。命令集的语法跟其他用户熟悉的shells(bash,csh)相似。
Shell在计算机科学中俗称“壳”,是提供给使用者使用界面的进行与系统交互的软件,通过接收用户输入的命令执行相应的操作,Shell分为图形界面Shell和命令行式Shell。
文件系统(FS)Shell包含了各种的类Shell的命令,可以直接与Hadoop分布式文件系统以及其他文件系统进行交互。
启动hadoop集群
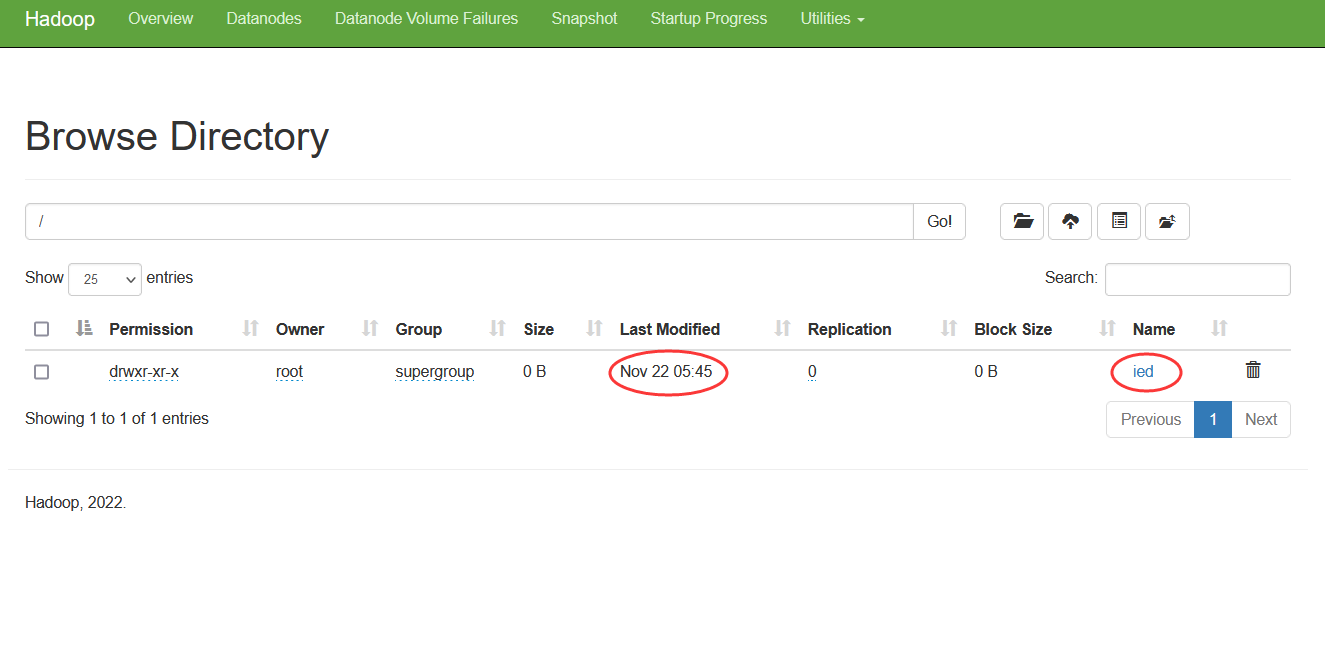
输入命令:hdfs dfs -mkdir /ied 在Hadoop WebUI查看创建的目录
hdfs dfs -mkdir /ied
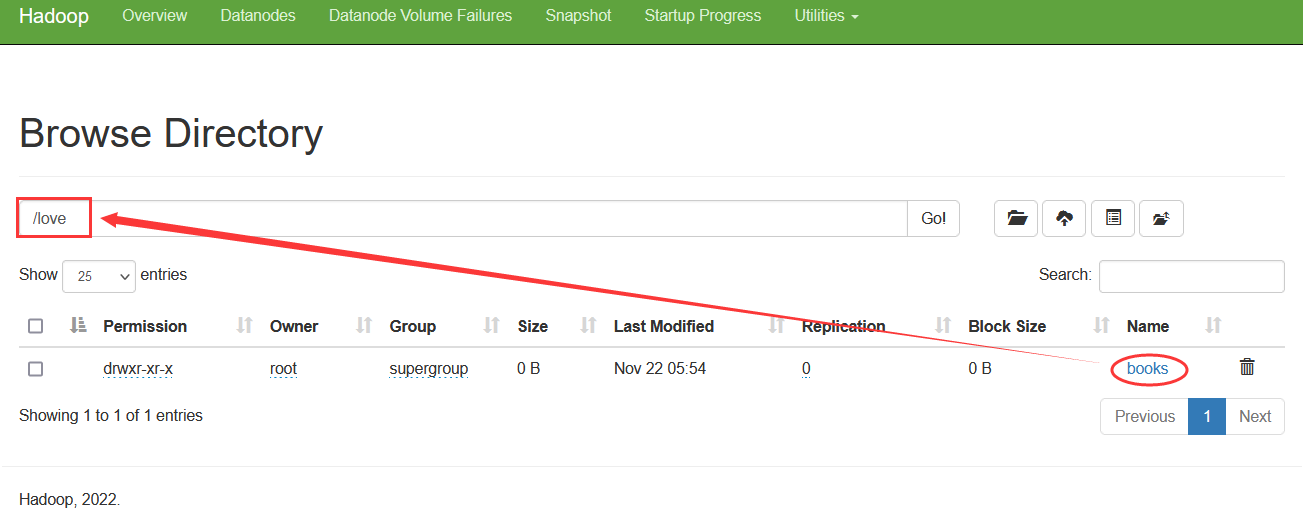
输入命令:hdfs dfs -mkdir /love/books,会报错,因为/love目录不存在 这里可以先创建 /luzhou 目录,然后在里面再创建 lzy 子目录,但是想要一步到位,就只需要一个 -p 参数即可。
hdfs dfs -mkdir /love/books
/love
/luzhou
lzy
-p
输入命令:hdfs dfs -mkdir -p /luzhou/lzy 在Hadoop WebUI查看创建的多层目录
hdfs dfs -mkdir -p /luzhou/lzy
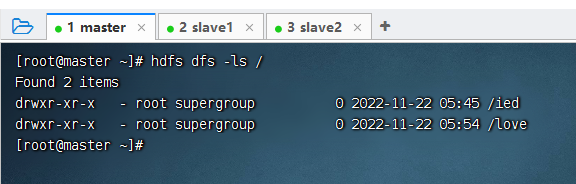
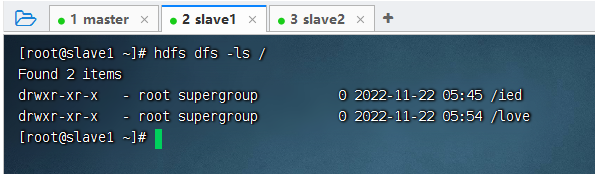
输入命令:hdfs dfs -ls /,查看根目录(可以在任何节点上查看,结果均一样)。
hdfs dfs -ls /
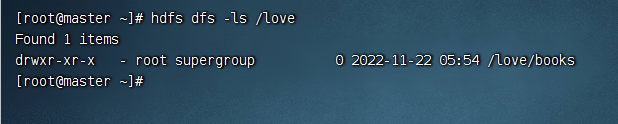
输入命令:hdfs dfs -ls /love
hdfs dfs -ls /love
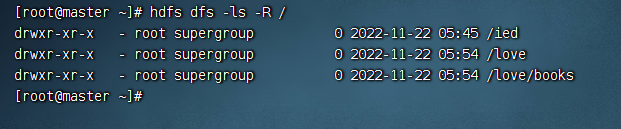
注:如果我们要查看根目录里全部的资源,那么要用到递归参数-R(必须大写)。
-R
执行命令:hdfs dfs -ls -R /,递归查看/目录(采用递归算法遍历树结构)
hdfs dfs -ls -R /
创建一个本地目录:/document/txt,输入命令:mkdir -p /document/txt 在/txt目录下创建一个test.txt文件,输入命令(>:重定向命令):echo "hello hadoop world" > /document/txt/test.txt 查看test.txt文件内容,输入命令:cat /document/txt/test.txt 上传test.txt文件到HDFS的/ied目录,输入命令:hdfs dfs -put /document/txt/test.txt /ied 在Hadoop WebUI界面查看是否上传成功
mkdir -p /document/txt
/txt
test.txt
echo "hello hadoop world" > /document/txt/test.txt
cat /document/txt/test.txt
hdfs dfs -put /document/txt/test.txt /ied
输入命令:hdfs dfs -cat /ied/test.txt
hdfs dfs -cat /ied/test.txt
1.删除本地的 /document/txt/ 目录下的 test.txt 文件,输入命令:rm -rf /document/txt/test.txt 2.下载HDFS文件系统的 /ied/test.txt 到本地当前目录不改名,输入命令:hdfs dfs -get /ied/test.txt /document/txt/ 3.检查是否下载成功,输入命令:ll /document/txt/test.txt 可以将HDFS上的文件下载到本地指定位置,并且可以更改文件名,输入命令:hdfs dfs -get /ied/test.txt /document/txt/exam.txt 检查是否下载成功,输入命令:ll /document/txt/exam.txt
/document/txt/
rm -rf /document/txt/test.txt
/ied/test.txt
hdfs dfs -get /ied/test.txt /document/txt/
ll /document/txt/test.txt
hdfs dfs -get /ied/test.txt /document/txt/exam.txt
ll /document/txt/exam.txt
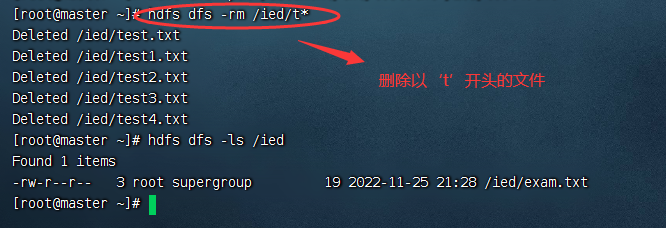
输入命令:hdfs dfs -rm /ied/test.txt 检查是否删除成功,输入命令:hdfs dfs -ls /ied/test.txt 使用通配符,可以删除满足一定特征的文件
hdfs dfs -rm /ied/test.txt
hdfs dfs -ls /ied/test.txt
输入命令:hdfs dfs -rmdir /yibin 输入命令:hdfs dfs -rmdir /love
hdfs dfs -rmdir /yibin
hdfs dfs -rmdir /love
提示: -rmdir 命令删除不了非空目录。 要递归删除才能删除非空目录:hdfs dfs -rm -r /love(-r:recursive)
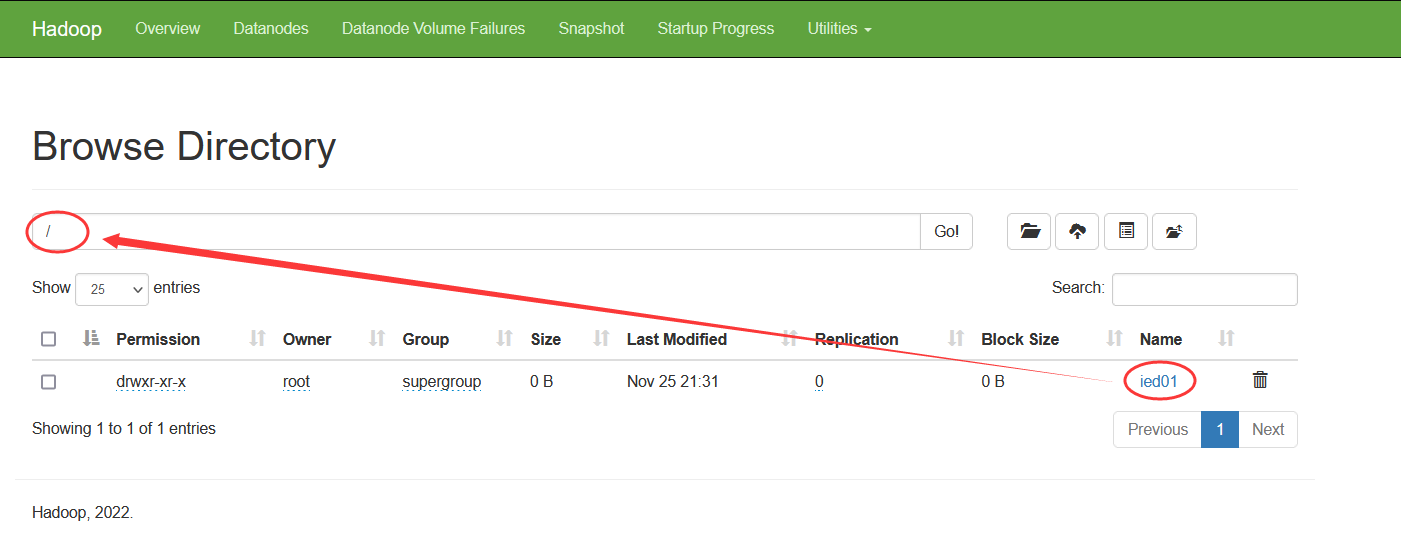
-mv 命令兼有移动与改名的双重功能 将 /ied 目录更名为 /ied01,输入命令:hdfs dfs -mv /ied /ied01
-mv
/ied
/ied01
hdfs dfs -mv /ied /ied01
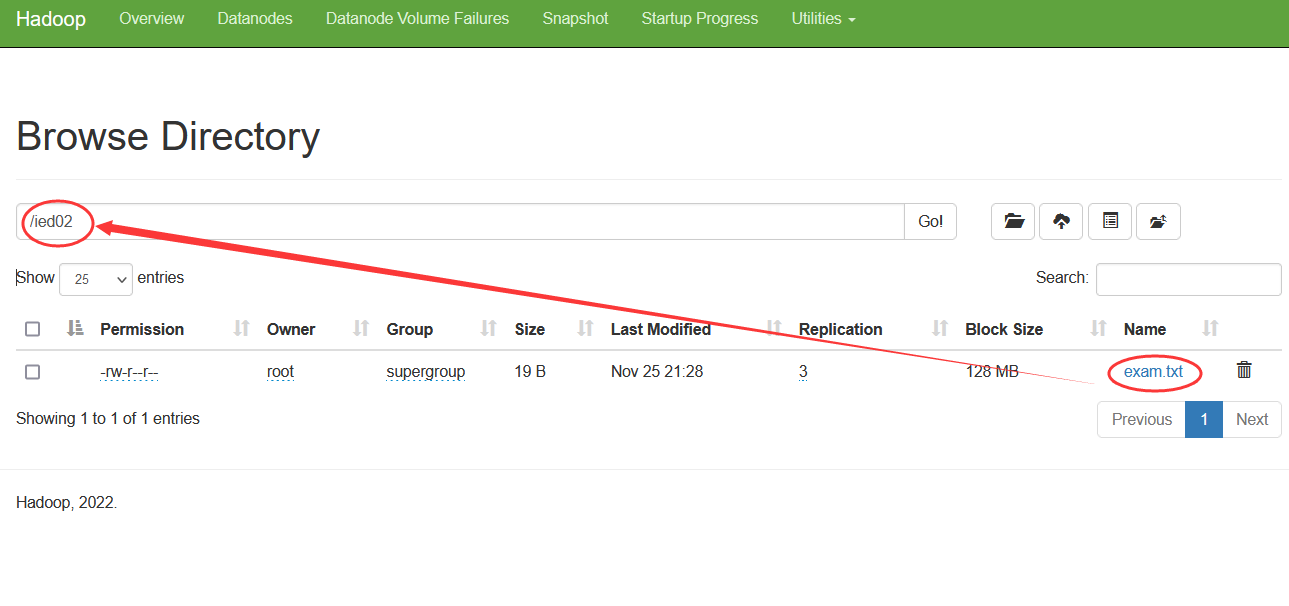
在Hadoop WebUI查看是否更名成功 将/ied01/exam.txt更名为/ied01/test.txt,输入命令:hdfs dfs -mv /ied01/exam.txt /ied01/test.txt 查看改名后的test.txt文件内容,输入命令:hdfs dfs -cat /ied01/test.txt 创建/ied02目录,将ied01/test.txt移动到/ied02目录,并且改名为exam.txt 创建ied02目录,输入命令:hdfs dfs -mkdir /ied02
/ied01/exam.txt
/ied01/test.txt
hdfs dfs -mv /ied01/exam.txt /ied01/test.txt
hdfs dfs -cat /ied01/test.txt
/ied02
ied01/test.txt
exam.txt
hdfs dfs -mkdir /ied02
移动改名,输入命令:hdfs dfs -mv /ied01/test.txt /ied02/exam.txt 在Hadoop WebUI界面查看
hdfs dfs -mv /ied01/test.txt /ied02/exam.txt
在/document/txt/目录下创建sport.txt、music.txt和book.txt并上传 在Hadoop WebUI界面查看上传的三个文件,注意文件名是按字典排序了的 合并/ied01目录的文件下载到/document/txt目录的merger.txt,输入命令:hdfs dfs -getmerge /ied01/* /document/txt/merger.txt
/document/txt
merger.txt
hdfs dfs -getmerge /ied01/* /document/txt/merger.txt
查看本地的merger.txt,看是不是三个文件合并后的内容,输入命令:cat /document/txt/merger.txt 由上图可知,merger.txt是book.txt、music.txt与sport.txt合并后的结果
cat /document/txt/merger.txt
book.txt
music.txt
sport.txt
fsck: file system check —— 文件系统检查
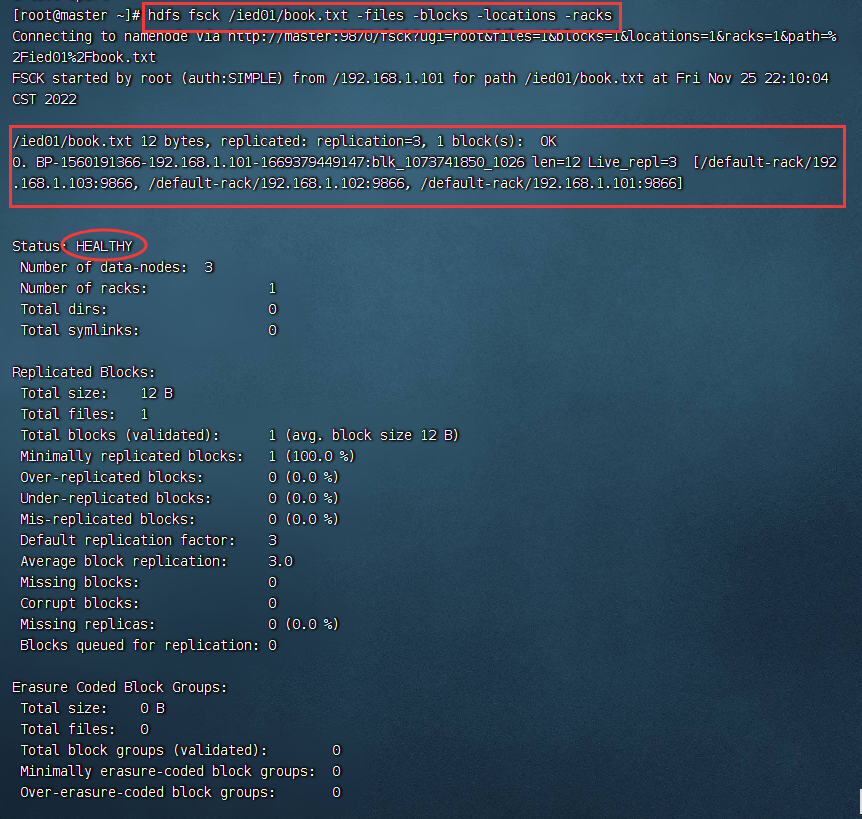
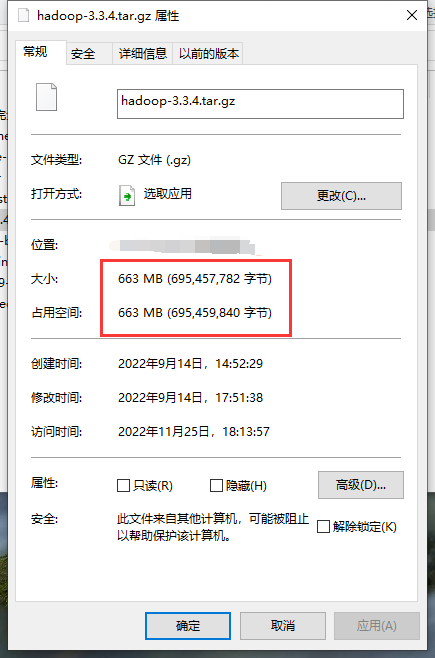
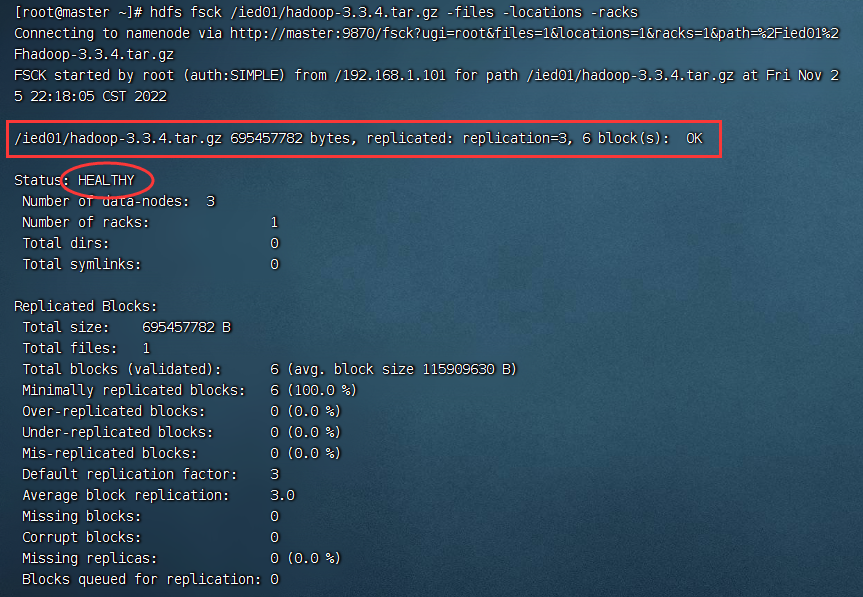
检查/ied01/book.txt文件,输入命令:hdfs fsck /ied01/book.txt -files -blocks -locations -racks 已知HDFS里一个文件块是128MB,上传一个大于128MB的文件,hadoop-3.3.4.tar.gz大约663.24MB
/ied01/book.txt
hdfs fsck /ied01/book.txt -files -blocks -locations -racks
128MB×5=640MB<663.24MB<768MB=128MB×6 ,HDFS会将hadoop-3.3.4.tar.gz分割成6块
输入命令:hdfs dfs -put /opt/hadoop-3.3.4.tar.gz /ied01,将hadoop压缩包上传到HDFS的/ied01目录 查看HDFS上hadoop-3.3.4.tar.gz文件信息,输入命令:hdfs fsck /ied01/hadoop-3.3.4.tar.gz -files -locations -racks 在Hadoop WebUI来查看文件块信息更加方便,总共有6个文件块:Block0、Block1、Block2、Block3、Block4、Block5 第1个文件块信息 第6个文件块信息
hdfs dfs -put /opt/hadoop-3.3.4.tar.gz /ied01
hdfs fsck /ied01/hadoop-3.3.4.tar.gz -files -locations -racks
在/ied01目录里创建一个文件sunshine.txt,执行命令:hdfs dfs -touchz /ied01/sunshine.txt 在Hadoop WebUI来查看到创建的是一个空文件,大小为0字节 这种空文件,一般用作标识文件,也可叫做时间戳文件,再次在/ied01目录下创建sunshine.txt同名文件
hdfs dfs -touchz /ied01/sunshine.txt
sunshine.txt
说明:如果touchz命令的路径指定的文件不存在,那就创建一个空文件;如果指定的文件存在,那就改变该文件的时间戳。
cp: copy - 拷贝或复制
将/ied01/music.txt复制到/ied02里,输入命令:hdfs dfs -cp /ied01/music.txt /ied02 查看拷贝生成的文件
/ied01/music.txt
hdfs dfs -cp /ied01/music.txt /ied02
将/ied01/book.txt复制到/ied02目录,改名为read.txt,输入命令:hdfs dfs -cp /ied01/book.txt /ied02/read.txt 查看拷贝后的文件内容,输入命令:hdfs dfs -cat /ied02/read.txt
read.txt
hdfs dfs -cp /ied01/book.txt /ied02/read.txt
hdfs dfs -cat /ied02/read.txt
源文件book.txt依然存在
将/ied01目录复制到/ied03目录,输入命令:hdfs dfs -cp /ied01 /ied03 查看拷贝后的/ied03目录,输入命令:hdsf dfs -ls /ied03, 其内容跟/ied01完全相同
/ied03
hdfs dfs -cp /ied01 /ied03
hdsf dfs -ls /ied03
du: disk usage 输入命令:hdfs dfs -du /ied01/book.txt 可以看到文件/ied01/book.txt大小是12个字符,包含9个字母、2个空格和一个看不见的结束符
hdfs dfs -du /ied01/book.txt
-copyFromLocal类似于-put,输入命令:hdfs dfs -copyFromLocal merger.txt /ied02 查看是否上传成功,输入命令:hdfs dfs -ls /ied02
-copyFromLocal
-put
hdfs dfs -copyFromLocal merger.txt /ied02
hdfs dfs -ls /ied02
-copyToLocal类似于-get,执行命令:hdfs dfs -copyToLocal /ied01/sunshine.txt /document/txt/sunlight.txt 查看是否下载成功,输入命令:ll /document/txt/
-copyToLocal
-get
hdfs dfs -copyToLocal /ied01/sunshine.txt /document/txt/sunlight.txt
ll /document/txt/
输入命令:hdfs dfs -count /ied01
hdfs dfs -count /ied01
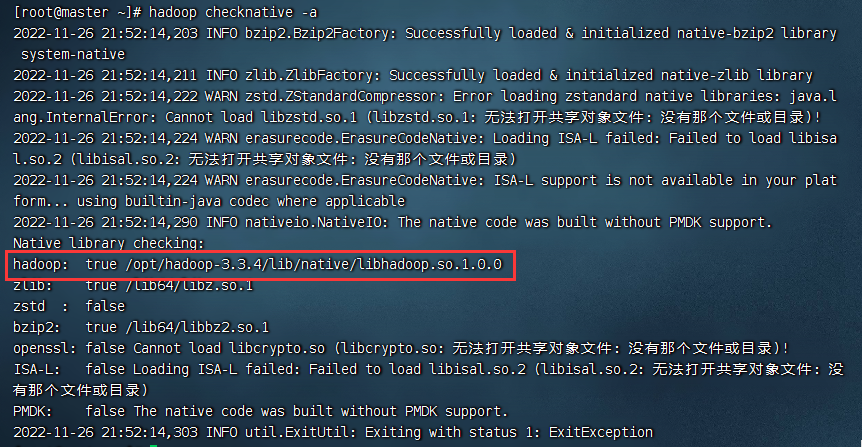
输入命令:hadoop checknative -a 查看hadoop本地库文件
hadoop checknative -a
输入命令:hdfs dfsadmin -safemode enter,
hdfs dfsadmin -safemode enter
注意:进入安全模式之后,只能读不能写
此时,如果要创建目录,就会报错
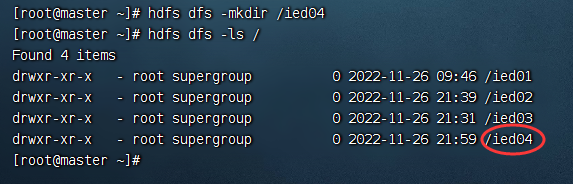
输入命令:hdfs dfsadmin -safemode leave 此时,创建目录/ied04就没有任何问题
hdfs dfsadmin -safemode leave
/ied04





 上传test.txt文件到HDFS的/ied目录,输入命令:
上传test.txt文件到HDFS的/ied目录,输入命令: 在Hadoop WebUI界面查看是否上传成功
在Hadoop WebUI界面查看是否上传成功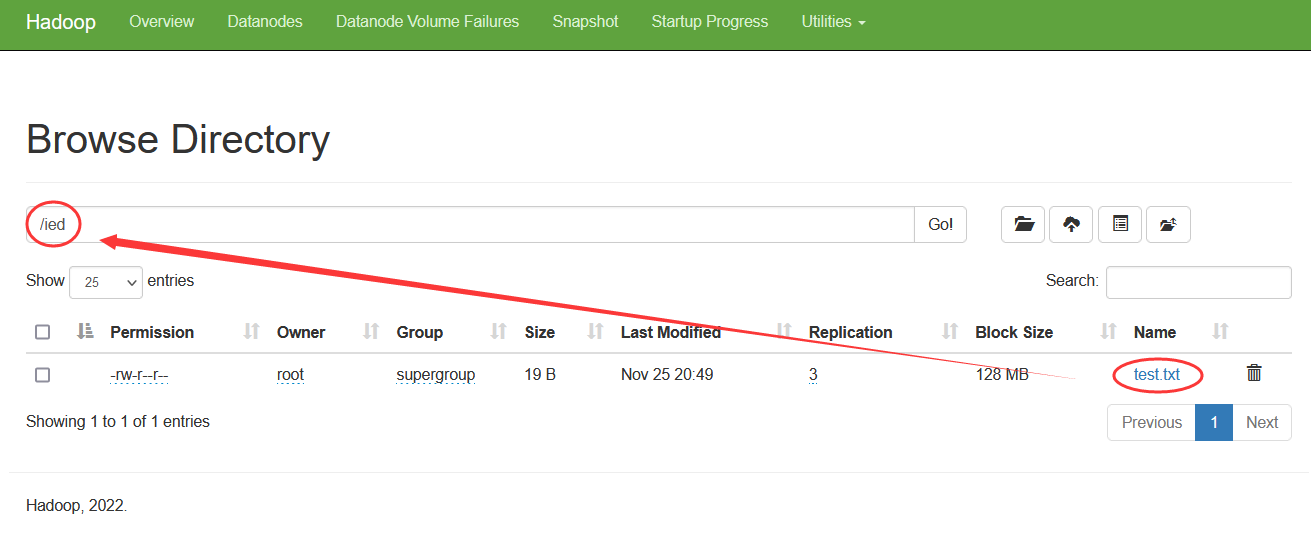

 2.下载HDFS文件系统的
2.下载HDFS文件系统的  3.检查是否下载成功,输入命令:
3.检查是否下载成功,输入命令: 可以将HDFS上的文件下载到本地指定位置,并且可以更改文件名,输入命令:
可以将HDFS上的文件下载到本地指定位置,并且可以更改文件名,输入命令:









 将
将 查看改名后的test.txt文件内容,输入命令:
查看改名后的test.txt文件内容,输入命令: 创建
创建
 在Hadoop WebUI界面查看
在Hadoop WebUI界面查看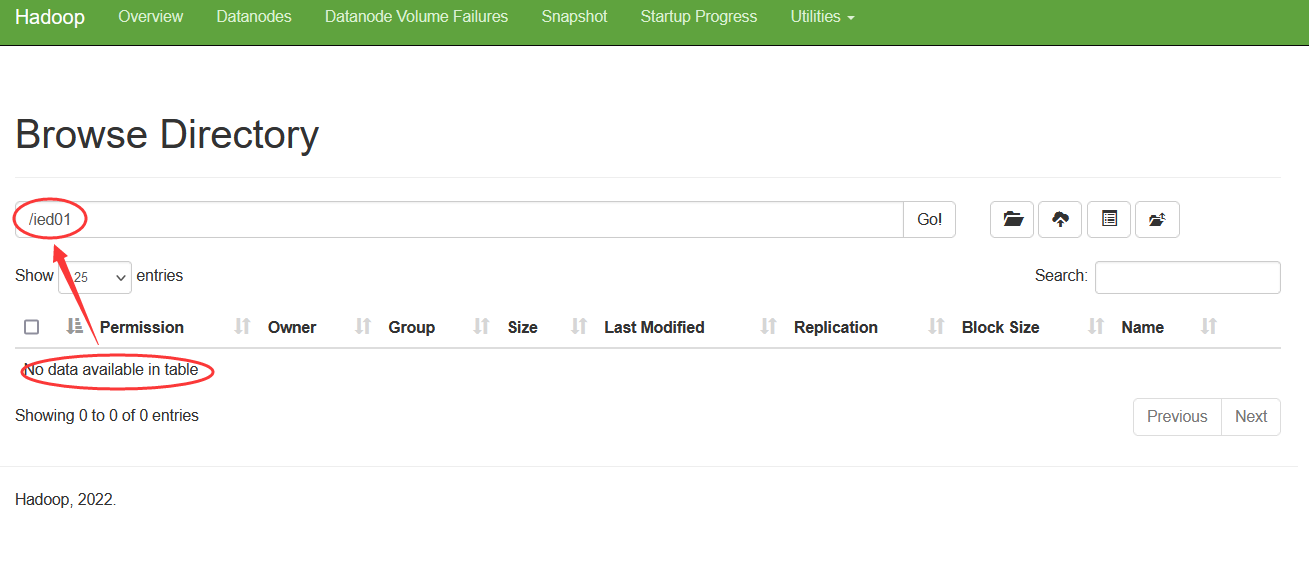


 在Hadoop WebUI界面查看上传的三个文件,注意文件名是按字典排序了的
在Hadoop WebUI界面查看上传的三个文件,注意文件名是按字典排序了的 合并
合并 查看本地的merger.txt,看是不是三个文件合并后的内容,输入命令:
查看本地的merger.txt,看是不是三个文件合并后的内容,输入命令: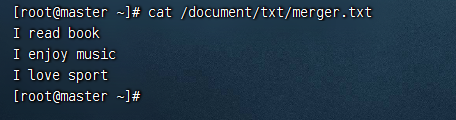

 在Hadoop WebUI来查看文件块信息更加方便,总共有6个文件块:Block0、Block1、Block2、Block3、Block4、Block5
在Hadoop WebUI来查看文件块信息更加方便,总共有6个文件块:Block0、Block1、Block2、Block3、Block4、Block5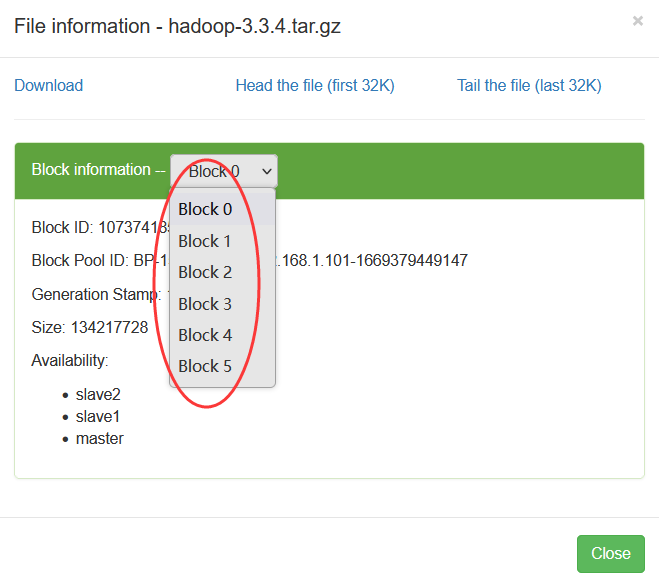 第1个文件块信息
第1个文件块信息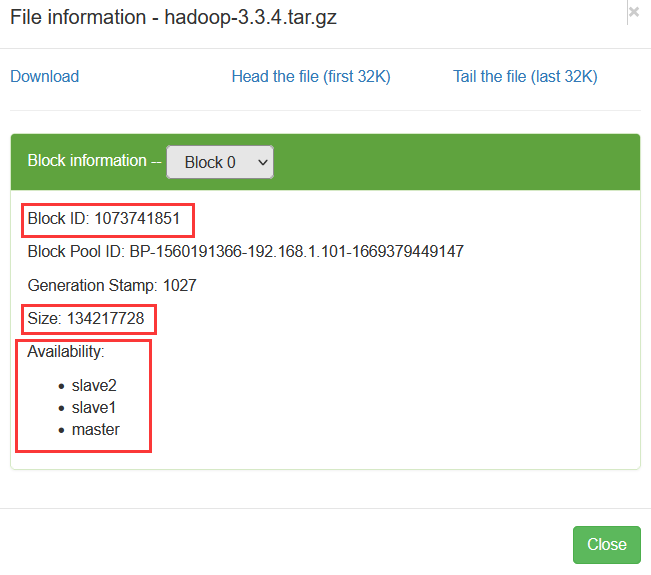 第6个文件块信息
第6个文件块信息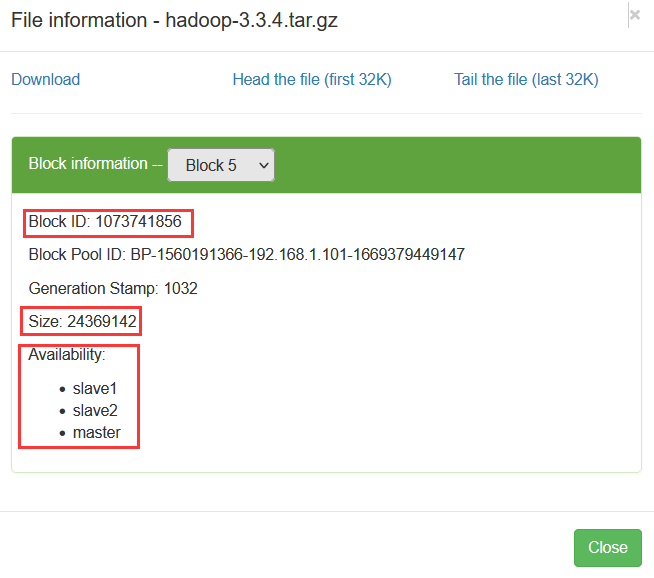
 在Hadoop WebUI来查看到创建的是一个空文件,大小为0字节
在Hadoop WebUI来查看到创建的是一个空文件,大小为0字节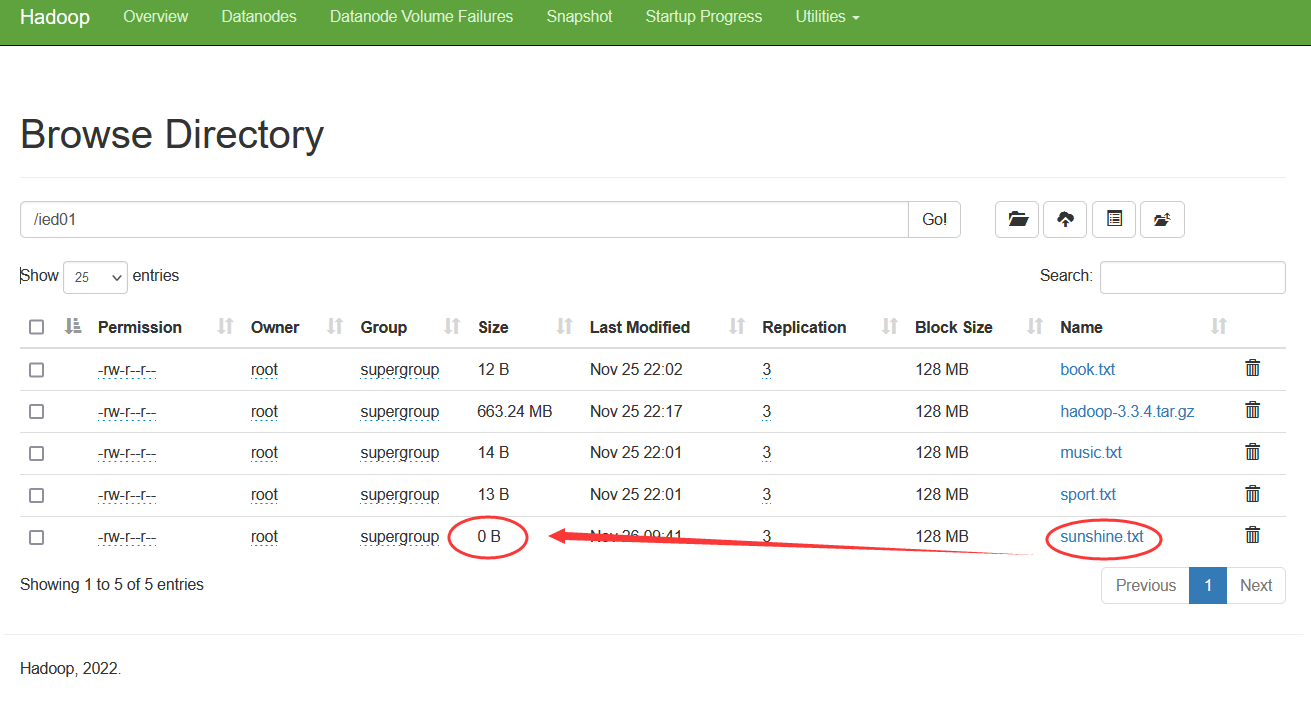

 查看拷贝生成的文件
查看拷贝生成的文件
 查看拷贝后的文件内容,输入命令:
查看拷贝后的文件内容,输入命令:






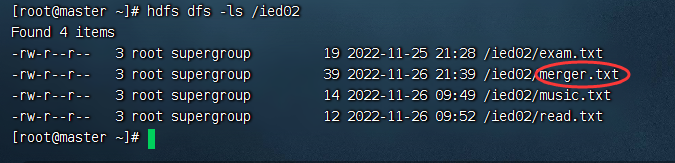
 查看是否下载成功,输入命令:
查看是否下载成功,输入命令: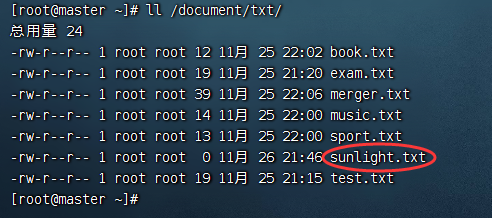
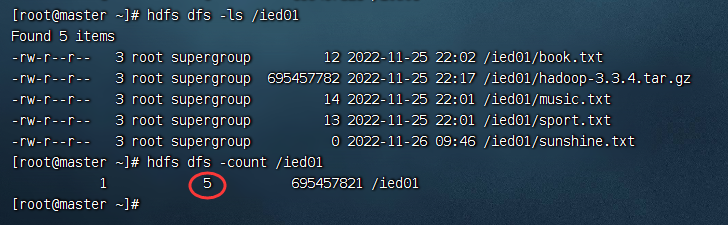



 此时,创建目录
此时,创建目录