参考视频
【2.21】元学习:学会如何去学习,就是带着这种对人类这种“学习能力”的期望诞生的。Meta Learning希望使得模型获取一种“学会学习”的能力,使其可以在获取已有“知识”的基础上快速学习新的任务,如:
让Alphago迅速学会下象棋
让一个猫咪图片分类器,迅速具有分类其他物体的能力
优点:
让学习更加有效率。我们通过多个task的学习,使得模型学习其他task时更加容易。
样本数量比较少的任务上,更加需要有效率的学习,从而提升准确率和收敛速度。meta learning是few shot learning的一个比较好的解决方案
一般的机器学习任务,我们是需要学习一个模型f,由输入x得到输出y。而meta learning,则是要学习一个F,用它来学习各种任务的f。如下图

分类:
单任务元学习: 往常深度学习流程,现在考虑能否学F?
往常深度学习流程,现在考虑能否学F?

W称为元知识;fw是指适合数据的算法;fθ代表分类模型
多任务的元学习算法


支撑集用于元训练学习w
用的验证集(查询集)数据计算损失用于学习θ
分类:

基于优化的
基于权重参数初始化的
基于模型的
基于优化的元学习:

在进行参数学习时,不是通过一定的规则(SGD Adam)而是通过学习的方式寻找参数
【2.22】模型参数初始化元学习:
模型无关元学习(MAML)

步骤:
①外层循环:随机抽取任务进入内层循环
②内层循环:选取K个样本,基于随机初始化的θ进行微调 得到θ’
③在查询集评估模型
④一直到收敛
MAML loss function如下:所有task的testing set上的loss之和,即为MAML的Loss,我们需要最小化这个loss。通过gradient descent的方法就可以实现。
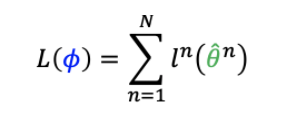
MAML更新参数的过程如下所示
初始化meta learning参数φ0
由φ0梯度下降一次,更新得到θm
在task m上更新一次参数(微调)
通过第二次θ的方向,确定φ的更新方向,得到φ1。
而对于model pretrain,其φ和θ的更新始终保持一致。

MAML的创新点在于,训练模型时,在单个任务task中,模型参数只更新一次。李宏毅老师认为主要原因是:
MAML希望模型具有单个task上,参数只更新一次,就可以得到不错初始化参数的能力
meta learning的数据集一般都是few shot的,否则很多task,训练耗时会很高。而few shot场景下,一般模型参数也更新不了几次
虽然在训练模型时只更新一次初始化参数,但在task test时,是可以更新多次参数,让模型充分训练的
meta learning一般会包括很多个task,单个task上只更新一次,可以保证学习效率。
Reptile
Reptile和MAML一样,也是focus在模型参数初始化上。故loss function也基本相同。不同之处是,它结合了pretrain model和MAML的特点,在模型参数更新上有所不同。Reptile也是先初始化参数φ0,然后采样出任务m,更新多次(而不是MAML的单次),得到一个不错的参数θm。利用θm的方向来更新φ0到φ1。同样的方法更新到φ2

小样本学习(few shot learning)
n-way-k-shot架构(n类 每类中取出k样本)
根据类来切分数据集
与预训练模型的区别
主要区别在于计算损失函数时区别不一样

MAML要求更新一步后θ做得好
pre-trained要求学习时θ本身做的好
权重元学习:
在学习样本时给每个样本赋一个权重,有的样本难以学习,有的样本比较好学习
数据集蒸馏:
把支撑集作为元知识,模型效果不好时,算法不动,改变数据集,使得效果较好。
参考文章
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)