视频链接https://www.bilibili.com/video/BV1Us41177P1?p=2
requests.get详解见:https://blog.csdn.net/qq_41845823/article/details/119516178
requests.get和urlopen的比较:https://blog.csdn.net/qq_41845823/article/details/119517519
以下为urllib.request.urlopen部分
Urllib是python内置的HTTP请求库:
- urllib.request 请求模块
- urllib.error 异常处理模块
- urllib.parse url解析模块
- urllib.robotparser robots.txt解析模块

python2中urllib2库中的很多方法在python3中被移至urllib.request库中。
urllib.request.urlopen
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
# get 类型请求
# 不加decode 返回json格式
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
print(response.read().decode('utf-8'))
# post 类型请求 需要添加属性data post请求用来上传或者修改服务器数据的
# post和个体区别见 https://segmentfault.com/a/1190000018129846
# 'http://httpbin.org/post' 网站可以用来测试http请求响应
import urllib.request
import urllib.parse
data = bytes(urllib.parse.urlencode({'word':'hollow'}), encoding='utf8')
response = urllib.request.urlopen('http://httpbin.org/post', data=data)
print(response.read().decode('utf-8'))
# timeout 属性 设置响应时长
import urllib.request
import urllib.error
import socket
try:
response = urllib.request.urlopen('http://httpbin.org/get', timeout=0.1)
print(response.read().decode('utf-8'))
except urllib.error.URLError as e:
if isinstance(e.reason, socket.timeout):
print('TIME OUT')
响应
# 响应类型
import urllib.request
response = urllib.request.urlopen('http://httpbin.org')
print(type(response))
# 输出:<class 'http.client.HTTPResponse'>
# 根据响应的属性 status和getheaders获得响应状态码和响应头部
import urllib.request
response = urllib.request.urlopen('http://httpbin.org')
print(response.status)
print(response.getheaders())
print(response.getheader('Date'))
Request
通过urlopen参数直接是url地址可以构造简单的请求,但是有时候需要进行很精准的请求,比如加上header的User-Agent、host等信息,这个时候就需要构造request请求
# 利用 urllib.request.Request 制作request请求,再把该请求作为 urllib.request.urlopen 的参数请求响应
import urllib.request
request = urllib.request.Request('http://httpbin.org')
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
# 利用 urllib.request.Request 制作request请求的 post请求
import urllib.request
import urllib.parse
url = 'http://httpbin.org/post'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36',
'Host': 'httpbin.org'
}
dict = {
'name': 'Germey'
}
data = bytes(urllib.parse.urlencode(dict), encoding='utf8')
request = urllib.request.Request(url=url, data=data, headers=headers, method='POST')
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
request对象提供了一个add_header方法,直接添加请求头部信息:
# 若有多个键值对需要用for循环添加
import urllib.request
import urllib.parse
url = 'http://httpbin.org/post'
dict = {
'name': 'Germey'
}
data = bytes(urllib.parse.urlencode(dict), encoding='utf8')
request = urllib.request.Request(url=url, data=data, method='POST')
request.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36')
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
以上是基本的爬虫的构造,可以完成大部分爬取工作,以下是高级设置
Handler
urllib.request官方文档 https://docs.python.org/3/library/urllib.request.html 给出很多Handler的方法
代理
当我们爬取一个网站的时候,有时候需要重复访问多次,此时该网站可能会捕获你的访问次数,当检测到访问次数异常时会禁止你的ip访问,这个时候我们需要设置代理进行访问该网站,在爬虫运行过程中不断切换代理
import urllib.request
proxy_handler = urllib.request.ProxyHandler({
'http': 'http://127.0.0.1:9743',
'https': 'https://127.0.0.1:9743'
})
# 使用urllib.request.build_opener把proxy_handler里的地址、端口转换成代理
opener = urllib.request.build_opener(proxy_handler)
# 产生的opener之久就可以访问网站
reponse = opener.open('http://httpbin.org/post')
print(reponse.read())

cookie
cookie是用来维持登陆状态的信息,存储在本地文件中,网站根据cookie值来决定是否是登陆状态,若把cookie都清除掉,则网站就退出登陆了
以下是百度的 cookie信息
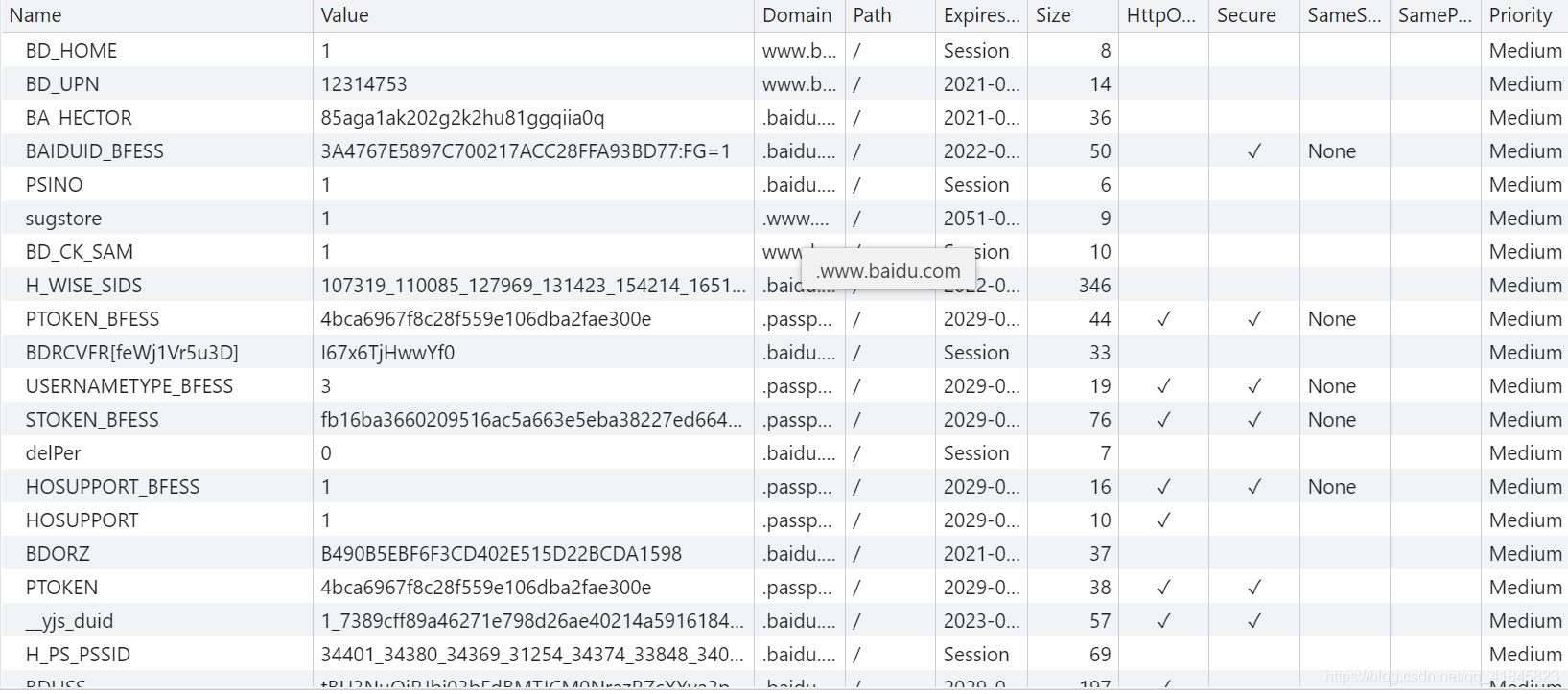
# 和代理类似,这里把cookie制作成opener
import http.cookiejar, urllib.request
# 产生一个<class 'http.cookiejar.CookieJar'>对象
cookie = http.cookiejar.CookieJar()
# 将cookie制作成<class 'urllib.request.HTTPCookieProcessor'>对象
handler = urllib.request.HTTPCookieProcessor(cookie)
# 产生<class 'urllib.request.OpenerDirector'>对象
opener = urllib.request.build_opener(handler)
reponse = opener.open('http://www.baidu.com')
for item in cookie:
print(item.name + '=' + item.value)
可以把cookie保存成文件,在下次访问的时候如果该cookies还没失效,则可以维持登陆状态
import http.cookiejar, urllib.request
filename = "cookie.txt"
# 这里是生成 mozilla 格式的cookie文本
cookie = http.cookiejar.MozillaCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
reponse = opener.open('http://www.baidu.com')
cookie.save(ignore_discard='True', ignore_expires='True')
import http.cookiejar, urllib.request
filename = 'cookie.txt'
# 这里是生成 LWP 格式的cookie文本
cookie = http.cookiejar.LWPCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True, ignore_expires=True)
接下来读取该文件,并加载cookie进行请求,文本是什么格式,就以哪种方法加载
import http.cookiejar, urllib.request
cookie = http.cookiejar.LWPCookieJar()
cookie.load('cookie.txt', ignore_discard=True, ignore_expires=True)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
print(response.read().decode('utf-8'))