正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑
示例:
import re
r"""
re.match函数 match()函数是有返回值的,如果匹配成功了,返回一个match对象,否则返回None。
原型:def match(pattern, string, flags=0)
参数:
pattern:匹配的正则表达式模板
string:要匹配的字符串数据
flags:标志位,用于控制正则表达式的匹配方式:是否区分大小写、是否换行匹配...
re.I 忽略大小写
re.L 本地化识别
re.M 多行匹配,影响^和$
re.S 是.匹配包括换行符在内的所有字符
re.U 根据Unicode字符集解析字符,影响\w \W \b \B
re.X 使我们以更灵活的格式理解正则表达式
功能:尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,返回None
"""
s = 'yangyu and jerry'
pattern = 'python'
result = re.match(pattern,s)
# 如果不是空性的词一定是True 空性的0、None、''、' '、{}、[]
if result:
print(result) # <re.Match object; span=(0, 6), match='yangyu'>
print(result.group()) # yangyu
else:
print('没有匹配到')
# www.baidu.com
print(re.match("www", "www.baidu.com")) # <re.Match object; span=(0, 3), match='www'>
print(re.match("www", "www.baidu.com").span()) # (0, 3)
print(re.match("www", "ww.baidu.com")) # None
print(re.match("www", "baidu.wwwcom")) # None
print(re.match("www", "wwW.baidu.com")) # None
print(re.match("www", "wwW.baidu.com", flags=re.I)) # <re.Match object; span=(0, 3), match='wwW'>
# 扫描整个字符串,返回从起始位置成功的匹配
print("-------------------------------------------------")
"""
re.search函数
原型:search(pattern, string, flags=0)
参数:
patter:匹配的正则表达式
string:要匹配的字符串
flags:标志位,用于控制正则表达式的匹配方式
功能:扫描整个字符串,并返回第一个成功匹配
"""
# <re.Match object; span=(12, 18), match='yangyu'>
print(re.search("yangyu", "Good man is yangyu,yangyu is a nice man !"))
print("-------------------------------------------------")
"""
re.findall函数
原型:findall(pattern, string, flags=0)
参数:
patter:匹配的正则表达式
string:要匹配的字符串
flags:标志位,用于控制正则表达式的匹配方式
功能:扫描整个字符串,并返回结果列表
"""
print(re.findall("yangyu", "Good man is yangyu,yangyu is a nice man !")) # ['yangyu', 'yangyu']
print(re.findall("yangyu", "Good man is yangyu,yAngyu is a nice man !", flags=re.I)) # ['yangyu', 'yAngyu']
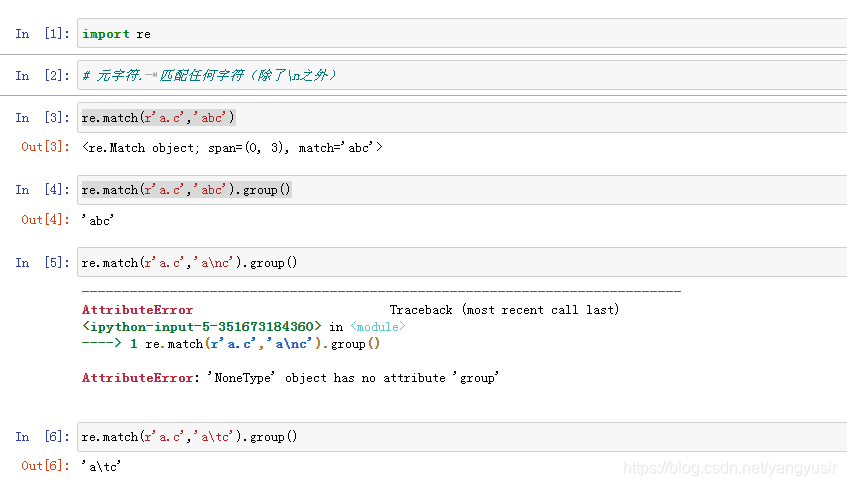
正则表达式中使用了很多元字符,用来表示某些特殊的含义或功能
| 表达式 | 匹配 |
|---|---|
| . | 小数点可以匹配除了换行符\n以外的任意一个字符 |
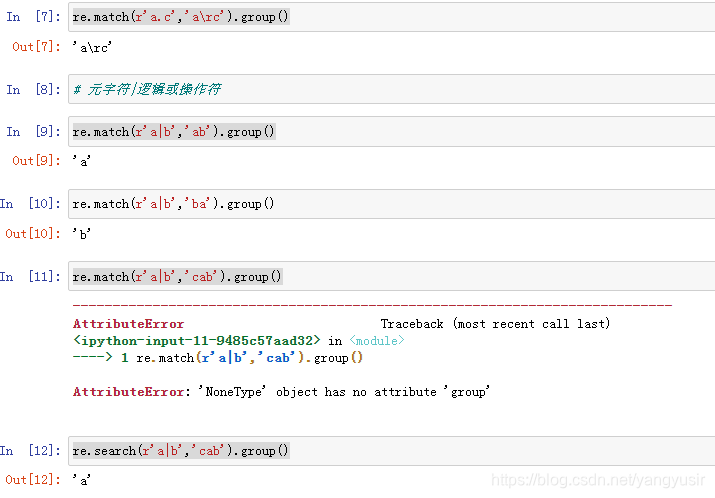
| | | 逻辑或操作符 |
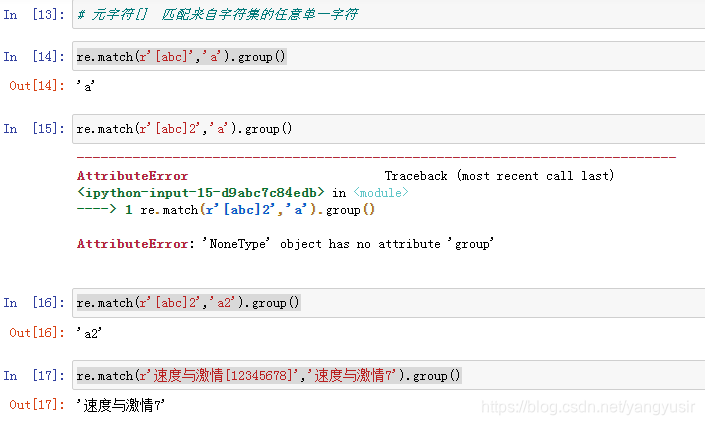
| [ ] | 匹配字符集中的一个字符 |
| [^] | 对字符集求反,也就是上面的反操作。尖顶号必须在方括号里的最前面 |
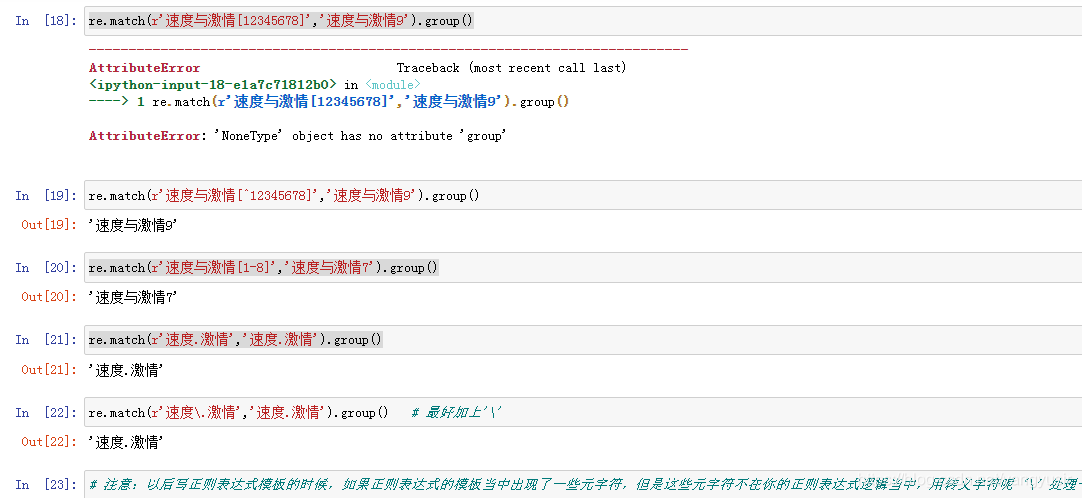
| - | 定义在[ ]里的一个字符区间,例如[a-z] |
| \ | 对紧跟其后的一个字符进行转义 |
| () | 对表达式进行分组,将圆括号内的内容当作一个整体,并获得匹配的值 |
一些无法书写或者具有特殊功能的字符,采用在前面加斜杠"\"进行转义的方法。
例如下表所示
| 表达式 | 匹配 |
|---|---|
| \r,\n | 匹配回车和换行符 |
| \t | 匹配制表符 |
| \\ | 匹配斜杠\ |
| \^ | 匹配^符号 |
| \$ | 匹配$符号 |
| \ . | 匹配. 小数点 |
问号?、星号*和括号等具有特殊含义的字符在匹配自身的时候,都要使用斜杠进行转义。
示例
正则表达式中的一些表示方法,可以同时匹配某个预定义字符集中的任意一个字符。
比如,表达式\d可以匹配任意一个数字。虽然可以匹配其中任意字符,但是只能是一个,不是多个。
| 表达式 | 匹配 |
|---|---|
| \d | 任意一个数字,0-9中的任意一个 |
| \w | 任意一个字母或数字或下划线,也就是A-Z,a-z,0-9,_中的任意一个 |
| \s | 空格、制表符、换页符等空白字符的其中任意一个 |
| \D | \d的反集,也就是非数字的任意一个字符,等同于[^\d] |
| \W | \w的反集,也就是非字母或非数字或非下划线的任意一个字符,等同于[^\w] |
| \S | \s的反集,也就是非空格、非制表符、非换页符等非空白字符的任意一个字符,等同于[^\s] |
示例:

前面的表达式,无论是只能匹配一种字符的表达式,还是可以匹配多种字符其中任意一个的表达式,
都只能匹配一次。但是有时候我们需要对某个字段进行重复匹配,例如手机号码13666666666,
一般的新手可能会写成\d\d\d\d\d\d\d\d\d\d\d(注意,这不是一个恰当的表达式),不但写着费劲,
看着也累,还不确定准确恰当。
这种情况可以使用表达式再加上修饰匹配次数的特殊符号{},不但重复书写表达式就可以重复匹配。
例如[abcd][abcd]可以写成[abcd]{2}
| 表达式 | 匹配 |
|---|---|
| {n} | 表达式重复n次,比如\d{2}相当于\d\d,a{3}相当于aaa |
| {m,n} | 表达式至少重复m次,最多重复n次。比如ab{1,3}可以匹配ab或abb或abbb |
| {m,} | 表达式至少重复m次,比如\w\d{2,}可以匹配a12,_1111,M123等 |
| ? | 匹配表达式0次或1次,相当于{0,1},比如a[cd]?可以匹配a,ac,ad |
| + | 表达式至少出现1次,相当于{1,} ,比如a+b可以匹配ab,aab,aaab等 |
示例:
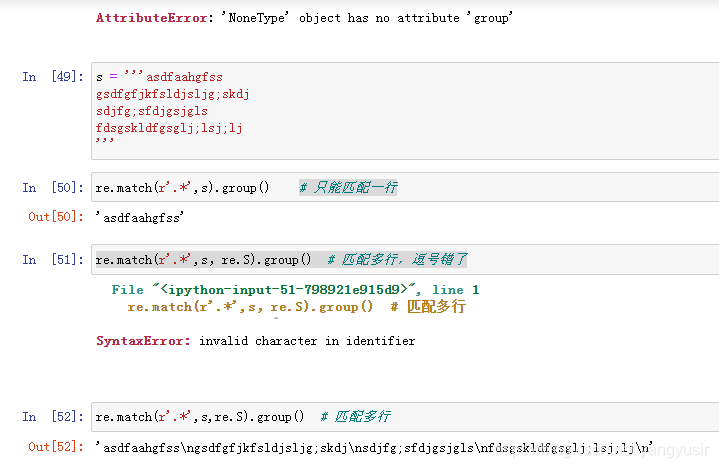
有时候,我们对匹配出现的位置有要求,比如开头、结尾、单词之间等等
| 表达式 | 匹配 |
|---|---|
| ^ | 在字符串开始的地方匹配,符号本身不匹配任何字符 |
| $ | 在字符串结束的地方匹配,符号本身不匹配任何字符 |
| \b | 匹配一个单词边界,也就是单词和空格之间的位置,符号本身不匹配任何字符 |
| \B | 匹配非单词边界,即左右两边都是\w范围或者左右两边都不是\w范围时的字符缝隙 |
示例:
在重复匹配时,正则表达式默认总是尽可能多的匹配,这被称为贪婪模式。
例如,针对文本dxxxdxxxd,表达式(d)(\w+)(d)中的\w+将匹配第一个d和最后一个d之间的
所有字符xxxdxxx。
可见,\w+在匹配的时候,总是尽可能多的匹配符合它规则的字符。
同理,带有?、*和{m,n}的重复匹配表达式都是尽可能地多匹配
校验数字的相关表达式:
| 功能 | 表达式 |
|---|---|
| 数字 | ^[0-9]*$ |
| n位的数字 | ^\d{n}$ |
| 至少n位的数字 | ^\d{n,}$ |
| 零和非零开头的数字 | ^(0|[1-9][0-9]*)$ |
| 有两位小数的正实数 | ^[0-9]+(.[0-9]{2})?$ |
| 非零的负整数 | ^-[1-9]\d*$ |
| 非负浮点数 | ^\d+(\.\d+)?$ |
| 浮点数 | ^(-?\d+)(\.\d+)?$ |
示例:
# 需求:匹配<div>abc</div>
import re
s = '<div>abc</div><div>def</div>'
ptn = '<div>.*</div>' # 贪婪匹配 python当中默认是贪婪匹配,总是尝试尽可能多的字符
r = re.match(ptn, s)
print(r.group()) # <div>abc</div><div>def</div>
# 非贪婪匹配和它相反,总是尝试匹配尽可能少的字符
# 实际的爬虫案例为例,前面内容+.*?+后面的内容
import re
s1 = '<div>abc</div><div>def</div>'
ptn1 = '<div>.*?</div>' # 非贪婪匹配
r1 = re.match(ptn1, s1)
print(r1.group()) # <div>abc</div>
特殊场景的表达式:
| 功能 | 表达式 |
|---|---|
| Email地址 | ^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$ |
| 域名 | [a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.? |
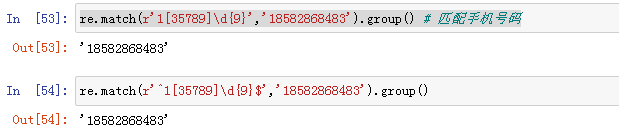
| 手机号码 | ^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$ |
| 身份证号(15或18位) | ^\d{15}|\d{18}$ |
| 短身份证号码(数字、字母x结尾) | ^([0-9]){7,18}(x|X)?$ 或 ^\d{8,18}|[0-9x]{8,18}|[0-9X]{8,18}?$ |
| 日期格式 | ^\d{4}-\d{1,2}-\d{1,2} |
| 空白行的正则表达式 | \n\s*\r (可以用来删除空白行) |
| ip地址提取 | \d+\.\d+\.\d+\.d+ |
| 中文字符的正则表达式 | [\u4e00-\u9fa5] |
示例:
import re
# 正则表达式比较灵活,只要能够正确匹配数据就行
# 定义一个函数
def fn(ptn, lst):
for x in lst:
result = re.match(ptn, x)
if result:
print(x, "匹配成功!", "匹配的结果是:", result.group())
else:
print(x, "匹配失败!")
# . 匹配除了换行的任意一个字符
lst = ['abc1', 'ab', 'aba', 'abbcd', 'oter']
ptn = 'ab.'
fn(ptn, lst)
'''
abc1 匹配成功! 匹配的结果是: abc
ab 匹配失败!
aba 匹配成功! 匹配的结果是: aba
abbcd 匹配成功! 匹配的结果是: abb
oter 匹配失败!'''
# []匹配[]中的一个字符
lst1 = ['man', 'mbn', 'mdn', 'mon', 'nba']
ptn1 = 'm[abcd]n'
fn(ptn1, lst1)
'''
man 匹配成功! 匹配的结果是: man
mbn 匹配成功! 匹配的结果是: mbn
mdn 匹配成功! 匹配的结果是: mdn
mon 匹配失败!
nba 匹配失败!'''
# \d 0-9
lst2 = ['py2', 'py4', 'pyxsal', 'mon', 'nba']
ptn2 = 'py\d'
fn(ptn2, lst2)
'''
py2 匹配成功! 匹配的结果是: py2
py4 匹配成功! 匹配的结果是: py4
pyxsal 匹配失败!
mon 匹配失败!
nba 匹配失败!'''
# \D 匹配非数字
lst3 = ['py2', 'py4', 'pyxsal', 'mon', 'nba']
ptn3 = 'py\D'
fn(ptn3, lst3)
'''
py2 匹配失败!
py4 匹配失败!
pyxsal 匹配成功! 匹配的结果是: pyx
mon 匹配失败!
nba 匹配失败!'''
# \s 匹配空白
lst4 = ['yang yu', 'yangyu', 'yang,yu', 'mon', 'nba']
ptn4 = 'yang\syu'
fn(ptn4, lst4)
'''
yang yu 匹配成功! 匹配的结果是: yang yu
yangyu 匹配失败!
yang,yu 匹配失败!
mon 匹配失败!
nba 匹配失败!'''
# \S 匹配非空白
lst5 = ['yang yu', 'yangyu', 'yang,yu', 'mon', 'nba']
ptn5 = 'yang\Syu'
fn(ptn5, lst5)
'''
yang yu 匹配失败!
yangyu 匹配失败!
yang,yu 匹配成功! 匹配的结果是: yang,yu
mon 匹配失败!
nba 匹配失败!
'''
# * 数量 0次到无限次
lst6 = ['hello', 'yangyu', 'yang,yu', 'y', 'nba']
ptn6 = 'y[a-z]*'
fn(ptn6, lst6)
'''
hello 匹配失败!
yangyu 匹配成功! 匹配的结果是: yangyu
yang,yu 匹配成功! 匹配的结果是: yang
y 匹配成功! 匹配的结果是: y
nba 匹配失败!'''
# + 数量 1次到无限次
lst7 = ['hello', 'yangyu', 'yang,yu', 'y', 'nba']
ptn7 = 'y[a-z]+'
fn(ptn7, lst7)
'''
hello 匹配失败!
yangyu 匹配成功! 匹配的结果是: yangyu
yang,yu 匹配成功! 匹配的结果是: yang
y 匹配失败!
nba 匹配失败!'''
# {m} 至少重复m次
lst8 = ['hello', 'yangyu', 'yang,yu', 'y', 'nba']
ptn8 = '[\w]{4}'
fn(ptn8, lst8)
'''
hello 匹配成功! 匹配的结果是: hell
yangyu 匹配成功! 匹配的结果是: yang
yang,yu 匹配成功! 匹配的结果是: yang
y 匹配失败!
nba 匹配失败!'''
# 匹配一个数字或者字母开头的qq邮箱 \w+ 和[\w]+ 一样
ptn9 = '\w+@qq.com'
lst9 = ['123@qq.com', 'yangyu@qq.com', 'helloyang@q.com', 'bcd@yy.com','1gask3@qq.com.cn']
fn(ptn9, lst9)
'''
123@qq.com 匹配成功! 匹配的结果是: 123@qq.com
yangyu@qq.com 匹配成功! 匹配的结果是: yangyu@qq.com
helloyang@q.com 匹配失败!
bcd@yy.com 匹配失败!
1gask3@qq.com.cn 匹配成功! 匹配的结果是: 1gask3@qq.com'''
ptn10 = '\w+@qq.com$'
lst10 = ['123@qq.com', 'yangyu@qq.com', 'helloyang@q.com', 'bcd@yy.com','1gask3@qq.com.cn']
fn(ptn10, lst10)
'''
123@qq.com 匹配成功! 匹配的结果是: 123@qq.com
yangyu@qq.com 匹配成功! 匹配的结果是: yangyu@qq.com
helloyang@q.com 匹配失败!
bcd@yy.com 匹配失败!
1gask3@qq.com.cn 匹配失败!'''
| 方法 | 描述 | 返回值 |
|---|---|---|
| compile(pattern[,flags]) | 根据包含正则表达式的字符串创建模式对象 | re对象 |
| search(pattern,string[,flags]) | 在字符串中查找 | 第一个匹配到的对象或者None |
| match(pattern,string[,flags]) | 在字符串的开始处匹配模式 | 在字符串开头匹配到的对象或者None |
| split(pattern,string[,maxsplit=0,flags]) | 根据模式的匹配项来分割字符串 | 分割后的字符串列表 |
| findall(pattern,string,flags) | 列出字符串中的模式的所有匹配项 | 所有匹配到的字符串列表 |
| sub(pat,repl,string[,count=0,flags]) | 将字符串中的所有的pat的匹配项用repl替换 | 完成替换后的新字符串 |
compile(pattern, flags=0)
这个用法是re模块的工厂法,用于将字符串形式的正则表达式编译为Pattern模式对象,
可以实现更加效率的匹配。第二个参数flag是匹配模式 使用compile()完成一次转换后,
再次使用该匹配模式的时候就不能进行转换了。
经过compile()转换的正则表达式对象也能使用普通的re用法。
flag匹配模式
| 匹配模式 | 描述 |
|---|---|
| re.A | ASCII字符模式 |
| re.I | 使匹配对大小写不敏感,也就是不区分大小写的模式 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响^和$ |
| re.S | 使.这个通配符能够匹配包括换行在内的所有字符,针对多行匹配 |
| re.U | 根据Unicode字符集解析字符。这个标志影响\w,\W,\b,\B |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解 |
search(pattern, string, flags=0)
在文本内查找,返回第一个匹配到的字符串。它的返回值类型和使用方法与match()是一样的,唯一的区别就是查找的位置不用固定在文本的开头。
findall(pattern, string, flags=0)
作为re模块的三大搜索函数之一,findall()和match()、search()的不同之处在于,前两者都是单值匹配,找到一个就忽略后面,直接返回不再查找了。而findall是全文查找,它的返回值是一个匹配到的字符串的列表。这个列表没有group()方法,没有start、end、span,更不是一个匹配对象,仅仅是个列表!如果一项都没有匹配到那么返回一个空列表。
split(pattern, string, maxsplit=0, flags=0)
re模块的split()方法和字符串的split()方法很相似,都是利用特定的字符去分割字符串。但是re模块的split()可以使用正则表达式,因此更灵活,更强大
split有个参数maxsplit,用于指定分割的次数
sub(pattern, repl, string, count=0, flags=0)
sub()方法类似字符串的replace()方法,用指定的内容替换匹配到的字符,可以指定替换次数
示例:
# 正则表达式常用方法
import re
pat = re.compile(r'abc')
print(pat.match('abc123')) # <re.Match object; span=(0, 3), match='abc'>
print(pat.match('abc123').group()) # abc
pat1 = re.compile(r'abc', re.I)
print(pat1.match('ABC123').group()) # ABC
print(pat1.match('abc123').group()) # abc
# search() 和match()方法基本上使用是一样的,区别就是它查找的位置不用固定在开头
# print(re.match(r'abc', '123abc456abc789').group()) # 报错:AttributeError: 'NoneType' object has no attribute 'group'
print(re.search(r'abc', '123abc456abc789').group()) # abc
# findall() 的不同之处:search() 和match()方法都是单值匹配,findall()全文匹配,返回值是一个列表
print(re.findall(r'abc', '123abc456abc789')) # ['abc', 'abc']
print(re.findall(r'abc', '123abc456abc789')[0]) # abc
# split(pattern,string,maxsplit=0,flags=0)
# 分割出数字
s = '8+7*5+6/3'
print(re.findall(r'\d', s)) # ['8', '7', '5', '6', '3']
print(re.findall(r'\d{1,}', s)) # ['8', '7', '5', '6', '3']
print(re.split(r'[\+\*\+\/]', s)) # ['8', '7', '5', '6', '3']
print(re.split(r'\D', s)) # ['8', '7', '5', '6', '3']
print(re.split(r'[\+\*\+\/]', s, maxsplit=2)) # ['8', '7', '5+6/3'] 最大分割2次
# sub() 指定内容进行替换
s = 'yangyu is a good man'
print(re.sub(r'y', 'Y', s)) # YangYu is a good man
Python的re模块有一个分组功能。所谓的分组就是去已经匹配到的内容再筛选出需要的内容,相当于二次过滤。实现分组靠圆括号(),而获取分组的内容靠的是group()、groups(),其实前面我们已经展示过。re模块里的积个重要方法在分组上,有不同的表现形式,需要区别对待。
示例:
# re模块分组功能
# 所谓分组就是去已经匹配到的内容里面再去筛选我需要的内容,相当于二次匹配
# 实现分组功能用的是(),获取分组的内容group()、groups()
# 分组,说白了就是我不仅要匹配还要获取
# 需求是匹配$66 $55
import re
s = 'apple price is $66,banana price is $55'
print(re.search(r'.+\$\d+.+\$\d+', s)) # <re.Match object; span=(0, 38), match='apple price is $66,banana price is $55'>
print(re.search(r'.+\$\d+.+\$\d+', s).group()) # apple price is $66,banana price is $55
print(re.search(r'.+(\$\d+).+(\$\d+)', s).group()) # apple price is $66,banana price is $55
print(re.search(r'.+(\$\d+).+(\$\d+)', s).group(0)) # apple price is $66,banana price is $55
print(re.search(r'.+(\$\d+).+(\$\d+)', s).group(1)) # $66
print(re.search(r'.+(\$\d+).+(\$\d+)', s).group(2)) # $55
print(re.search(r'.+(\$\d+).+(\$\d+)', s).groups()) # ('$66', '$55')
'''
group()/group(0) 匹配整个分组
group(1) 获取第一个分组
group(2) 获取第二个分组
groups() 获取所有的分组(把分组的结果放到一个元组里面)
'''
案例: 爬取天气网数据
# 爬取天气网数据
# 需求:爬取成都7天的天气情况(日期,天气状况,温度,风力),保存到csv
# 'http://www.weather.com.cn/weather/101270101.shtml' 目标url 7天
# 'http://www.weather.com.cn/weather15d/101270101.shtml' 8-15天
# 'http://www.weather.com.cn/weather40d/101270101.shtml' 40天
# 第一步:分析页面
'''
<ul class="t clearfix">
<li class="sky skyid lv2 on">
<h1>30日(今天)</h1>
<big class="png40 d01"></big>
<big class="png40 n00"></big>
<p title="多云转晴" class="wea">多云转晴</p>
<p class="tem">
<span>29</span>/<i>18℃</i>
</p>
<p class="win">
<em>
<span title="无持续风向" class="NNW"></span>
<span title="无持续风向" class="NNW"></span>
</em>
<i><3级</i>
</p>
<div class="slid"></div>
</li>
<li class="sky skyid lv2">
<h1>1日(明天)</h1>
<big class="png40 d01"></big>
<big class="png40 n07"></big>
<p title="多云转小雨" class="wea">多云转小雨</p>
<p class="tem">
<span>30</span>/<i>19℃</i>
</p>
<p class="win">
<em>
<span title="无持续风向" class="NNW"></span>
<span title="无持续风向" class="NNW"></span>
</em>
<i><3级</i>
</p>
<div class="slid"></div>
</li>
<li class="sky skyid lv3">
<h1>2日(后天)</h1>
<big class="png40 d08"></big>
<big class="png40 n07"></big>
<p title="中雨转小雨" class="wea">中雨转小雨</p>
<p class="tem">
<span>27</span>/<i>18℃</i>
</p>
<p class="win">
<em>
<span title="无持续风向" class="NNW"></span>
<span title="无持续风向" class="NNW"></span>
</em>
<i><3级</i>
</p>
<div class="slid"></div>
</li>
<li class="sky skyid lv1">
<h1>3日(周一)</h1>
<big class="png40 d01"></big>
<big class="png40 n02"></big>
<p title="多云转阴" class="wea">多云转阴</p>
<p class="tem">
<span>27</span>/<i>16℃</i>
</p>
<p class="win">
<em>
<span title="无持续风向" class="NNW"></span>
<span title="无持续风向" class="NNW"></span>
</em>
<i><3级</i>
</p>
<div class="slid"></div>
</li>
<li class="sky skyid lv3">
<h1>4日(周二)</h1>
<big class="png40 d01"></big>
<big class="png40 n03"></big>
<p title="多云转阵雨" class="wea">多云转阵雨</p>
<p class="tem">
<span>24</span>/<i>13℃</i>
</p>
<p class="win">
<em>
<span title="无持续风向" class="NNW"></span>
<span title="无持续风向" class="NNW"></span>
</em>
<i><3级</i>
</p>
<div class="slid"></div>
</li>
<li class="sky skyid lv3">
<h1>5日(周三)</h1>
<big class="png40 d01"></big>
<big class="png40 n07"></big>
<p title="多云转小雨" class="wea">多云转小雨</p>
<p class="tem">
<span>23</span>/<i>15℃</i>
</p>
<p class="win">
<em>
<span title="无持续风向" class="NNW"></span>
<span title="无持续风向" class="NNW"></span>
</em>
<i><3级</i>
</p>
<div class="slid"></div>
</li>
<li class="sky skyid lv3">
<h1>6日(周四)</h1>
<big class="png40 d02"></big>
<big class="png40 n02"></big>
<p title="阴" class="wea">阴</p>
<p class="tem">
<span>20</span>/<i>12℃</i>
</p>
<p class="win">
<em>
<span title="无持续风向" class="NNW"></span>
<span title="无持续风向" class="NNW"></span>
</em>
<i><3级</i>
</p>
<div class="slid"></div>
</li>
</ul>
'''
# 第二步:思路总结
# 1.先获取网页源代码 整个html文件
# 2.从网页网代码中去匹配ul标签的数据
# 3.从ul标签里面去匹配li标签的数据
# 4.解析li标签里的数据
# 5.保存数据
import csv
import re
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0"
}
class WeatherSpider:
# 获取网页源代码
def getSource(self):
# 目标url
url = 'http://www.weather.com.cn/weather/101270101.shtml'
response = requests.get(url, headers=headers).content.decode('utf-8')
# print(response)
return response
# 解析数据
def parseSource(self):
response = self.getSource()
# 匹配ul 正则表达式比较灵活
result = re.match(r'.*?(<ul class="t clearfix">.*?</ul>).*?', response, re.S)
# print(result.group(1))
ul = result.group(1)
lis = re.findall('<li.*?>.*?</li>', ul, re.S)
lis_all = []
pattern = re.compile(r'<li.*?>.*?<h1>(.*?)</h1>.*?<p.*?>(.*?)</p>.*?<span>(.*?)</span>(.)<i>(.*?)</i>.*?<i>(.*?)</i>.*?</li>', re.S)
for li in lis:
# print('-'*50)
# print(i)
r = pattern.match(li)
# print(r.group(1),end='\t')
# print(r.group(2),end='\t')
# print(r.group(3),end='')
# print(r.group(4),end='')
# print(r.group(5),end='\t')
# print(r.group(6),end='')
# print()
'''
30日(今天) 多云转晴 29/18℃ <3级
1日(明天) 多云转小雨 30/19℃ <3级
2日(后天) 中雨转小雨 27/18℃ <3级
3日(周一) 多云转阴 27/16℃ <3级
4日(周二) 多云转阵雨 24/13℃ <3级
5日(周三) 多云转小雨 23/15℃ <3级
6日(周四) 阴 20/12℃ <3级'''
lis_one = [r.group(1), r.group(2), r.group(3)+r.group(4)+r.group(5), r.group(6)]
lis_all.append(lis_one)
return lis_all
# 保存数据
def saveData(self):
lis_all = self.parseSource()
with open('weather7days.csv', 'w', encoding='utf-8', newline='')as file_obj:
writer = csv.writer(file_obj)
writer.writerow(['日期', '天气', '温度', '风力'])
writer.writerows(lis_all)
def main():
WeatherSpider().getSource()
WeatherSpider().parseSource()
WeatherSpider().saveData()
if __name__ == '__main__':
main()
xml_content = '''
<bookstore>
<book>
<title lang='eng'>Harry Potter</title>
<author>JK.Rowing</author>
<year>2005</year>
<price>29<price>
</book>
</bookstore>
'''

工具安装

安装参考网站:
https://blog.csdn.net/qq_31082427/article/details/84987723
| 符号 | 含义 |
|---|---|
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
查找某个特定的节点或者包含某个指定的值的节点
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于bookstore子元素的第一个book元素 |
| /bookstore/book[last()] | 选取属于bookstore子元素的最后一个book元素 |
| /bookstore/book[last() - 1] | 选取属于bookstore子元素的倒数第二个book元素 |
| /bookstore/book[position() < 3] | 选取最前面的两个属于bookstore子元素的book元素 |
| //title[@lang] | 选取所有拥有名为lang的属性的title元素 |
| //title[@lang=‘eng’] | 选取所有的title元素,且这些元素拥有值为eng的lang属性 |
| /bookstore/book[price>35.00] | 选取bookstore元素的所有book元素,且其中的price元素的值须大于35.00 |
在Python中,我们安装lxml库来使用XPath 技术
lxml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取HTML/XML数据利用etree.HTML,将字符串转化为Element对象
lxml python 官方文档:http://lxml.de/index.html
可使用 pip 安装:pip install lxml
lxml 可以自动修正 html 代码
wb_data = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
"""
import csv
from lxml import etree
wb_data = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
"""
html_element = etree.HTML(wb_data)
# 获取li标签下面的href属性
links = html_element.xpath('//li/a/@href')
print(links) # ['link1.html', 'link2.html', 'link3.html', 'link4.html', 'link5.html']
# 获取li标签下面a标签的文本内容
result = html_element.xpath('//li/a/text()')
print(result) # ['first item', 'second item', 'third item', 'fourth item', 'fifth item']
# 需求:把二者的结果保存到一个字典当中,然后存储进csv文件
# 例如:{'href':'link1.html','title':'first item'},{'href':'link2.html','title':'second item'},{'href':'link3.html','title':'third item'}
titles = ('href','title') # titles = ('href','title')或titles = {'href','title'} 也可以
lst = []
for link in links:
d = {}
d['href']=link
# print(d)
# print(links.index(link)
d['title'] = result[links.index(link)]
# print(d)
lst.append(d)
with open('xpath语法练习.csv','w',encoding='utf-8',newline='')as file_obj:
writer = csv.DictWriter(file_obj,titles)
writer.writeheader()
writer.writerows(lst)
案例:爬取豆瓣top250数据
# 豆瓣top250电影
# 需求:爬取电影的名字、评分、引言、详情页的url 1-10 保存到csv文件当中
# 如何实现?
# 解决方式:requests、csv、lxml(xpath)
# 思路分析
# 一.页面结构分析
# 目标url https://movie.douban.com/top250
# 第二页 https://movie.douban.com/top250?start=25&filter=
# 第三页 https://movie.douban.com/top250?start=50&filter=
# 第十页 https://movie.douban.com/top250?start=225&filter=
# 第一页 https://movie.douban.com/top250?start=0&filter=
# 规律 (page-1)*25
# 实现步骤:1.先向目标url发起请求 获取网页源码 2.通过etree.HTML(网页源码)生成一个element对象
# 3.element对象.xpath('xxxx') 电影的名字 评分 引言 详情页的url
# 先把数据保存到一个字典里{'title':'肖申克的救赎','score':'9.7','director&actor':' 导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...','year':'1994','country':'美国','type':'犯罪 剧情','quote':'希望让人自由。'}
# 4.把列表中的数据存到csv文件中
# 二.代码逻辑实现
import csv
import requests
from lxml import etree
from requests.packages.urllib3.exceptions import InsecureRequestWarning
# 目标url
doubanUrl = 'https://movie.douban.com/top250?start={}&filter='
# 定义一个函数,获取网页源码
def getSource(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36"
}
res = requests.get(url, headers=headers, verify=False)
res.encoding = 'utf-8'
return res.text
# 解析数据
def parseSource(source):
html_element = etree.HTML(source)
movieItemList = html_element.xpath('//div[@class="info"]')
movieList = []
for eachMovie in movieItemList:
title = eachMovie.xpath('./div/a/span[1]/text()')[0]
other_title = eachMovie.xpath('normalize-space(./div/a/span[position()>1]/text())')
other_title = other_title.strip().replace(' ', '')
link = eachMovie.xpath('./div/a/@href')[0]
director_actor = eachMovie.xpath('normalize-space(./div/p/text()[1])')
if ' ' in director_actor:
director = director_actor.split(' ')[0]
actor = director_actor.split(' ')[1]
else:
director = director_actor.split(' ')[0]
actor = 'None'
year_country_type = eachMovie.xpath('normalize-space(./div/p/text()[2])')
year = year_country_type.split(' / ')[0]
country = year_country_type.split(' / ')[1]
type = year_country_type.split(' / ')[2]
score = eachMovie.xpath('./div[2]/div/span[2]/text()')[0]
quote = eachMovie.xpath('./div[2]/p[2]/span/text()')
if quote == []:
quote = 'None'
else:
quote = eachMovie.xpath('./div[2]/p[2]/span/text()')[0]
print(title, other_title, link, director, actor, year, country, type, score, quote)
movieDict = {}
movieDict['title'] = title.strip() + other_title
movieDict['link'] = link
movieDict['director'] = director
movieDict['actor'] = actor
movieDict['year'] = year
movieDict['country'] = country
movieDict['type'] = type
movieDict['score'] = score
movieDict['quote'] = quote
movieList.append(movieDict)
return movieList
def save_movieList(movieList):
with open('douban_movieList.csv', 'w', encoding='utf-8', newline='')as file_obj:
writer = csv.DictWriter(file_obj,
fieldnames=['title', 'link', 'director', 'actor', 'year', 'country', 'type', 'score',
'quote'])
writer.writeheader()
for each in movieList:
writer.writerow(each)
if __name__ == '__main__':
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
movieLists = []
for i in range(10):
papelink = doubanUrl.format(i * 25)
response = getSource(papelink)
movieLists += parseSource(response)
save_movieList(movieLists)

Beautiful Soup 是一个可以从HTML或XML文件中提取数据的网页信息提取库
作用:解析和提取网页中的数据
意义:pc端 网站中去爬取数据 百度网站 腾讯网站,随着网站的种类增多,寻找最合适的解决该网站的技术。正则表达式有时候不太好写,容易出错。xpath需要记住一些语法。bs4特点:只需要记住一些方法怎么使用就行。
导入:from bs4 import BeautifulSoup
创建soup对象:soup = BeautifulSoup(html_doc, features=“lxml”);soup = BeautifulSoup(html_doc, “lxml”);soup = BeautifulSoup(html_doc, “html5lib”)
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, “html.parser”) | Python的内置标准库,执行速度适中,文档容错能力强 | Python 2.7.3 or 3.2.2)前 的版本中文档容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup, “lxml”) | 速度快,文档容错能力强, | 需要安装C语言库 |
| lxml XML解析器 | BeautifulSoup(markup, [“lxml-xml”]);BeautifulSoup(markup, “xml”) | 速度快,唯一支持XML的解析器, | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup, “html5lib”) | 最好的容错性,以浏览器的方式解析文档,生成HTML5格式的文档 | 速度慢,不依赖外部扩展 |
使用soup对象的方法:soup.prettify();soup.title;soup.title.string;soup.title.name;
示例:
# bs4简介
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, "lxml")
# print(soup)
'''
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html>
'''
print(soup.prettify())
'''
<html>
<head>
<title>
The Dormouse's story
</title>
</head>
<body>
<p class="title">
<b>
The Dormouse's story
</b>
</p>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">
Elsie
</a>
,
<a class="sister" href="http://example.com/lacie" id="link2">
Lacie
</a>
and
<a class="sister" href="http://example.com/tillie" id="link3">
Tillie
</a>
;
and they lived at the bottom of a well.
</p>
<p class="story">
...
</p>
</body>
</html>'''
# 通过标签来定位数据,然后再解析数据
print(soup.title) # <title>The Dormouse's story</title>
print(soup.title.name) # title
print(soup.title.string) # The Dormouse's story
print(soup.p) # 通过标签导航找到的是第一个 <p class="title"><b>The Dormouse's story</b></p>
r = soup.find_all('p') # 查找所有的p标签
print(len(r)) # 3
print(r)
'''
[<p class="title"><b>The Dormouse's story</b></p>, <p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>, <p class="story">...</p>]'''
links = soup.find_all('a')
for link in links:
print(link.get('href'))
'''
http://example.com/elsie
http://example.com/lacie
http://example.com/tillie'''
bs4的对象种类
示例
# bs4的对象种类
# BeautifulSoup : bs对象
# tag : 标签
# NavigableString : 可导航的字符串
# Comment : 注释
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, 'lxml')
print(type(soup)) # <class 'bs4.BeautifulSoup'>
print(type(soup.title)) # <class 'bs4.element.Tag'>
print(type(soup.a)) # <class 'bs4.element.Tag'>
print(type(soup.p)) # <class 'bs4.element.Tag'>
print(type(soup.title.string)) # <class 'bs4.element.NavigableString'>
print(soup.p) # <p class="title"><b>The Dormouse's story</b></p>
html_doc1 = "<p class='title'><b><!--注释--></b></p>"
sp = BeautifulSoup(html_doc1,'lxml')
print(sp.p.b.string) # 注释
print(sp.p.string) # 注释
print(sp.b.string) # 注释
print(type(sp.p.b.string)) # <class 'bs4.element.Comment'>
print(type(sp.p.string)) # <class 'bs4.element.Comment'>
print(type(sp.b.string)) # <class 'bs4.element.Comment'>
bs里面有三种情况,第一个是遍历,第二个是查找,第三个是修改
contents children descendants
string strings stripped_strings
示例
# bs4遍历子节点
# contents 返回的是一个所有子节点的列表
# children 返回的是一个子节点的迭代器,通过这个迭代器可以进行迭代
# descendants 返回的是一个生成器遍历子子孙孙
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, 'lxml')
all_p = soup.find_all('p') # 获取所以p标签
print(all_p)
'''
[<p class="title"><b>The Dormouse's story</b></p>, <p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>, <p class="story">...</p>]'''
for p in all_p:
print(p['class']) # 获取p标签的属性
'''
['title']
['story']
['story']'''
# 迭代 iterate 指的是按照某种顺序逐个访问列表的某一项。例如:python中的for循环
# 循环 loop 指满足某些条件下,重复执行某一段代码。例如:python中的while循环
# contents 返回的是一个所有子节点的列表
links = soup.contents
print(type(links)) # <class 'list'>
print(links)
'''
[<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html>]
'''
# 案例
# contents 返回的是一个所有子节点的列表
html = '''
<div>
<a herf="http://example.com">yangyu</a>
<a herf="http://example.com">杨yu</a>
<a herf="http://example.com">yangyu</a>
</div>
'''
sp = BeautifulSoup(html, 'lxml')
contens_list = sp.contents
print(type(contens_list)) # <class 'list'>
print(contens_list)
'''
[<html><body><div>
<a herf="http://example.com">yangyu</a>
<a herf="http://example.com">杨yu</a>
<a herf="http://example.com">yangyu</a>
</div>
</body></html>]'''
for conten in contens_list:
res = conten.find_all('a')
for conten in res:
print(conten.string)
'''
yangyu
杨yu
yangyu'''
# children 返回的是一个子节点的迭代器,通过这个迭代器可以进行迭代
childrens = sp.div.children
print(type(childrens)) # <class 'list_iterator'>
print(childrens) # <list_iterator object at 0x00000000031F1688>
for conten in childrens:
print(conten,',',conten.string,end='')
'''
,
<a herf="http://example.com">yangyu</a> , yangyu
,
<a herf="http://example.com">杨yu</a> , 杨yu
,
<a herf="http://example.com">yangyu</a> , yangyu
, '''
# descendants 返回的是一个生成器遍历子子孙孙
# print(len(sp.contents)) # 1
# print(len(sp.descendants)) # TypeError: object of type 'generator' has no len()
for x in sp.descendants:
print("="*30)
print(x)
'''
==============================
<html><body><div>
<a herf="http://example.com">yangyu</a>
<a herf="http://example.com">杨yu</a>
<a herf="http://example.com">yangyu</a>
</div>
</body></html>
==============================
<body><div>
<a herf="http://example.com">yangyu</a>
<a herf="http://example.com">杨yu</a>
<a herf="http://example.com">yangyu</a>
</div>
</body>
==============================
<div>
<a herf="http://example.com">yangyu</a>
<a herf="http://example.com">杨yu</a>
<a herf="http://example.com">yangyu</a>
</div>
==============================
==============================
<a herf="http://example.com">yangyu</a>
==============================
yangyu
==============================
==============================
<a herf="http://example.com">杨yu</a>
==============================
杨yu
==============================
==============================
<a herf="http://example.com">yangyu</a>
==============================
yangyu
==============================
==============================
'''
# string获取标签里面的内容
# strings 返回是一个生成器对象用过来获取多个标签内容
# stripped_strings 和strings基本一致 但是它可以把多余的空格去掉
title_tag = soup.title
print(title_tag) # <title>The Dormouse's story</title>
print(title_tag.string) # The Dormouse's story
title_head = soup.head
print(title_head) # <head><title>The Dormouse's story</title></head>
print(title_head.string) # The Dormouse's story
print(soup.html.string) # None
strings = soup.strings
print(strings) # <generator object Tag._all_strings at 0x00000000031E3748>
for s in strings:
print(s)
'''
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie
,
Lacie
and
Tillie
;
and they lived at the bottom of a well.
...
'''
strings_s = soup.stripped_strings
for s in strings_s:
print(s)
'''
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie
,
Lacie
and
Tillie
;
and they lived at the bottom of a well.
...
'''
parent 和 parents
示例
# 遍历父节点
# parent直接获得父节点
# parents获取所有的父节点
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, 'lxml')
# parent 直接获得父节点
title_tag = soup.title
print(title_tag) # <title>The Dormouse's story</title>
print(title_tag.parent) # <head><title>The Dormouse's story</title></head>
print(title_tag.parent.parent) # html文档
print(soup.html.parent) # html文档的父节点是它本身
print(soup.html.parent.parent) # None
# parents 获取所有的父节点
a_tag = soup.a
print(a_tag) # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
print(a_tag.parents) # <generator object PageElement.parents at 0x00000000031F1748>
for p in a_tag.parents:
print("=="*30)
print(p)
'''
============================================================
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
============================================================
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body>
============================================================
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html>
============================================================
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html>
'''
示例
# 遍历兄弟结点
# next_sibling 下一个兄弟结点
# previous_sibling 上一个兄弟结点
# next_siblings 下一个所有兄弟结点
# previous_siblings上一个所有兄弟结点
from bs4 import BeautifulSoup
html = '<a><b>bbb</b><c>ccc</c></a>'
soup2 = BeautifulSoup(html,'lxml')
b_tag = soup2.b
print(b_tag) # <b>bbb</b>
print(b_tag.next_sibling) # <c>ccc</c>
print(b_tag.next_sibling.next_sibling) # None
print(b_tag.next_sibling.previous_sibling) # <b>bbb</b>
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, 'lxml')
print(soup.prettify())
'''
<html>
<head>
<title>
The Dormouse's story
</title>
</head>
<body>
<p class="title">
<b>
The Dormouse's story
</b>
</p>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">
Elsie
</a>
,
<a class="sister" href="http://example.com/lacie" id="link2">
Lacie
</a>
and
<a class="sister" href="http://example.com/tillie" id="link3">
Tillie
</a>
;
and they lived at the bottom of a well.
</p>
<p class="story">
...
</p>
</body>
</html>'''
a_tag = soup.a
print(a_tag) # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
print(a_tag.next_sibling) # ,
print(a_tag.next_siblings) # <generator object PageElement.next_siblings at 0x00000000031C2748>
for x in a_tag.next_siblings:
print(x)
'''
,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
;
and they lived at the bottom of a well.
'''
a_tag = soup.find(id="link3")
print(a_tag) # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
print(a_tag.previous_siblings) # <generator object PageElement.previous_siblings at 0x00000000031C1748>
for x in a_tag.previous_siblings:
print(x)
'''
and
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
,
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
Once upon a time there were three little sisters; and their names were'''
字符串过滤器
正则表达式过滤器
我们用正则表达式里面compile方法编译一个正则表达式传给 find 或者 find_all这个方法可以实现一个正则表达式的一个过滤器的搜索
列表过滤器
True过滤器
方法过滤器
示例:
'''
搜索树
- 字符串过滤器
- 正则表达式过滤器
我们用正则表达式里面compile方法编译一个正则表达式传给 find 或者 find_all这个方法可以实现一个正则表达式的一个过滤器的搜索
- 列表过滤器
- True过滤器
- 方法过滤器
'''
import re
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, 'lxml')
# 字符串过滤器
a_tag = soup.find('a')
print(a_tag) # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
all_a_tag = soup.find_all('a')
print(all_a_tag)
'''
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]'''
# 正则表达式过滤器
print(soup.find(re.compile('title'))) # <title>The Dormouse's story</title>
# 列表过滤器
print(soup.find_all(['p','a']))
'''
[<p class="title"><b>The Dormouse's story</b></p>, <p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>, <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>, <p class="story">...</p>]
'''
print(soup.find_all(['title','b']))
'''
[<title>The Dormouse's story</title>, <b>The Dormouse's story</b>]'''
# True过滤器
print(soup.find_all(True))
'''
[<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html>, <head><title>The Dormouse's story</title></head>, <title>The Dormouse's story</title>, <body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body>, <p class="title"><b>The Dormouse's story</b></p>, <b>The Dormouse's story</b>, <p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>, <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>, <p class="story">...</p>]
'''
# 方法过滤器
def fn(tag):
return tag.has_attr('id')
print(soup.find_all('id')) # []
print(soup.find_all(fn))
'''
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]'''
def fn(tag):
return tag.has_attr('class')
print(soup.find_all('class')) # []
print(soup.find_all(fn))
'''
[<p class="title"><b>The Dormouse's story</b></p>, <p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>, <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>, <p class="story">...</p>]'''
find_all()
def find_all(self, name=None, attrs={}, recursive=True, text=None,
limit=None, **kwargs):
示例:
html = """
<table class="tablelist" cellpadding="0" cellspacing="0">
<tbody>
<tr class="h">
<td class="l" width="374">职位名称</td>
<td>职位类别</td>
<td>人数</td>
<td>地点</td>
<td>发布时间</td>
</tr>
<tr class="even">
<td class="l square"><a target="_blank" href="position_detail.php?id=33824&keywords=python&tid=87&lid=2218">22989-金融云区块链高级研发工程师(深圳)</a></td>
<td>技术类</td>
<td>1</td>
<td>深圳</td>
<td>2017-11-25</td>
</tr>
<tr class="odd">
<td class="l square"><a target="_blank" href="position_detail.php?id=29938&keywords=python&tid=87&lid=2218">22989-金融云高级后台开发</a></td>
<td>技术类</td>
<td>2</td>
<td>深圳</td>
<td>2017-11-25</td>
</tr>
<tr class="even">
<td class="l square"><a target="_blank" href="position_detail.php?id=31236&keywords=python&tid=87&lid=2218">SNG16-腾讯音乐运营开发工程师(深圳)</a></td>
<td>技术类</td>
<td>2</td>
<td>深圳</td>
<td>2017-11-25</td>
</tr>
<tr class="odd">
<td class="l square"><a target="_blank" href="position_detail.php?id=31235&keywords=python&tid=87&lid=2218">SNG16-腾讯音乐业务运维工程师(深圳)</a></td>
<td>技术类</td>
<td>1</td>
<td>深圳</td>
<td>2017-11-25</td>
</tr>
<tr class="even">
<td class="l square"><a target="_blank" href="position_detail.php?id=34531&keywords=python&tid=87&lid=2218">TEG03-高级研发工程师(深圳)</a></td>
<td>技术类</td>
<td>1</td>
<td>深圳</td>
<td>2017-11-24</td>
</tr>
<tr class="odd">
<td class="l square"><a target="_blank" href="position_detail.php?id=34532&keywords=python&tid=87&lid=2218">TEG03-高级图像算法研发工程师(深圳)</a></td>
<td>技术类</td>
<td>1</td>
<td>深圳</td>
<td>2017-11-24</td>
</tr>
<tr class="even">
<td class="l square"><a target="_blank" href="position_detail.php?id=31648&keywords=python&tid=87&lid=2218">TEG11-高级AI开发工程师(深圳)</a></td>
<td>技术类</td>
<td>4</td>
<td>深圳</td>
<td>2017-11-24</td>
</tr>
<tr class="odd">
<td class="l square"><a target="_blank" href="position_detail.php?id=32218&keywords=python&tid=87&lid=2218">15851-后台开发工程师</a></td>
<td>技术类</td>
<td>1</td>
<td>深圳</td>
<td>2017-11-24</td>
</tr>
<tr class="even">
<td class="l square"><a target="_blank" href="position_detail.php?id=32217&keywords=python&tid=87&lid=2218">15851-后台开发工程师</a></td>
<td>技术类</td>
<td>1</td>
<td>深圳</td>
<td>2017-11-24</td>
</tr>
<tr class="odd">
<td class="l square"><a id="test" class="test" target='_blank' href="position_detail.php?id=34511&keywords=python&tid=87&lid=2218">SNG11-高级业务运维工程师(深圳)</a></td>
<td>技术类</td>
<td>1</td>
<td>深圳</td>
<td>2017-11-24</td>
</tr>
</tbody>
</table>
"""
from bs4 import BeautifulSoup
# 1.获取所有的tr标签
soup = BeautifulSoup(html, 'lxml')
trs = soup.find_all('tr')
for tr in trs:
print(tr)
# 2.获取第二个tr标签的内容
second_tr = soup.find_all('tr')[1]
print(second_tr)
# 3.获取所有class='even'的tr标签
trs_even = soup.find_all('tr', class_='even') # class_='even'可以改为attrs={'class':'even'}
for tr in trs_even:
print(tr)
# 4.获取id="test",class="test"的a标签数据
lst = soup.find_all('a',id="test",class_="test")
for tr in lst:
print(tr)
# 获取所有a标签的href属性
示例
# find_all()
# find_all()方法以列表形式返回所有的搜索到的标签数据
# find()方法返回搜索到的第一条数据
# find_all()方法参数
# name : tag名称
# attr : 标签的属性
# recursive : 是否递归搜索
# text : 文本内容
# limit : 限制返回条数
# kwargs : 关键字参数
import re
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, 'lxml')
print(soup.find_all('a')) # 查找所有a标签
'''
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]'''
print(soup.find('a')) # 查找第一个a标签
'''<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>'''
print(soup.find_all('p','title')) # 查找所有包含'title'属性的p标签
'''[<p class="title"><b>The Dormouse's story</b></p>]'''
print(soup.find_all(id="link1")) # 关键字参数查找
'''[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]'''
print(soup.find_all(id=re.compile('link1')))
'''[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]'''
print(soup.find(id=re.compile('link1')))
'''<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>'''
print(soup.find_all(text=re.compile('story')))
'''["The Dormouse's story", "The Dormouse's story"]'''
print(soup.find_all('a',limit=1)) # 查找a标签,限制为1条(limit=负数,返回1条;limit=0,返回所有)
'''[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]'''
print(soup.find_all('a',limit=2)) # 查找a标签,限制为2条
'''[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]'''
print(soup.find_all('a',limit=5)) # 查找a标签,限制为5条,但是只有3条
'''[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]'''
print(soup.find_all('a',recursive=False)) # [] 是否递归搜索,默认recursive=True
# find_parents() 搜索所有的父节点
# find_parent() 搜索单个父节点
# find_next_siblings() 搜索所有兄弟
# find_next_sibling() 搜索单个兄弟
# find_previous_siblings() 往上搜索所有兄弟
# find_previous_sibling() 往上搜索单个兄弟
# find_all_next() 往下搜索所有元素
# find_next() 往下查找单个元素
title_tag = soup.title
print(title_tag.find_parent())
'''<head><title>The Dormouse's story</title></head>'''
print(title_tag.find_parents())
'''[<head><title>The Dormouse's story</title></head>, <html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html>, <html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html>]
'''
print(title_tag.find_parents('head'))
'''[<head><title>The Dormouse's story</title></head>]'''
s = soup.find(text='Elsie')
print(s.find_parents('p'))
'''[<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>]'''
tag_a = soup.a
print(tag_a) # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
print(tag_a.find_next_siblings('a'))
'''[<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]'''
print(tag_a.find_next_sibling('a'))
'''<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>'''
tag_last_a = soup.find(id="link3")
print(tag_last_a.find_previous_siblings('a'))
'''[<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]'''
print(tag_last_a.find_previous_sibling('a'))
'''<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>'''
print(tag_a.find_all_next())
'''[<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>, <p class="story">...</p>]'''
print(tag_a.find_next())
'''<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>'''
tag_p = soup.p
print(tag_p.find_all_next('a'))
'''[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]'''
print(tag_p.find_next('a'))
'''<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>'''
我们也可以通过css选择器的方式来提取数据。但是需要注意的是这里面需要我们掌握css语法
https://www.w3school.com.cn/cssref/css_selectors.asp
示例
# 修改文档树
# 修改tag的名称和属性
# 修改string 属性赋值,就相当于用当前的内容替代了原来的内容
# append() 像tag中添加内容,就好像Python的列表的 .append() 方法
# decompose() 修改删除段落,对于一些没有必要的文章段落我们可以给他删除掉
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, 'lxml')
tag_p = soup.p
print(tag_p) # <p class="title"><b>The Dormouse's story</b></p>
tag_p.name = 'w' # 修改标签名
tag_p['class'] = 'content' # 修改属性
print(tag_p) # <w class="content"><b>The Dormouse's story</b></w>
print(tag_p.string) # The Dormouse's story
tag_p.string = 'yangyu is a good man' # 修改内容
print(tag_p.string) # yangyu is a good man
tag_w = soup.w
print(tag_w) # <w class="content">yangyu is a good man</w>
tag_w.append('hello')
print(tag_w) # <w class="content">yangyu is a good manhello</w>
r = soup.find(class_='content')
print(r) # <w class="content">yangyu is a good manhello</w>
r.decompose()
print(soup)
'''
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html>
'''
# 爬取全国所有城市天气数据
# 1.分析页面结构
# 2.直辖市和省份问题,通过判断下标索引值来取第一个值
# 3.网页标签问题 soup = BeautifulSoup(response,'html5lib')
# 华北:http://www.weather.com.cn/textFC/hb.shtml
# 东北:http://www.weather.com.cn/textFC/db.shtml
# 华东:http://www.weather.com.cn/textFC/hd.shtml
# 华中:http://www.weather.com.cn/textFC/hz.shtml
# 华南:http://www.weather.com.cn/textFC/hn.shtml
# 西北:http://www.weather.com.cn/textFC/xb.shtml
# 西南:http://www.weather.com.cn/textFC/xn.shtml
# 港澳台:http://www.weather.com.cn/textFC/gat.shtml
import csv
from bs4 import BeautifulSoup
import requests
def get_source(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36",
}
response = requests.get(url, headers=headers).content.decode('utf-8')
# print(response)
return response
def parse_source(response):
soup = BeautifulSoup(response, 'html5lib') # 'html5lib'解决网页标签缺失问题
# 先获取conMidtab这个div标签
conMidtab = soup.find('div', class_="conMidtab") # soup.find当天数据,soup.find_all一周数据
# print(conMidtab)
# 找到所有的table标签
tables = conMidtab.find_all('table') # 安装模块 pip install html5lib
city_temp_list = []
for table in tables:
# print('--------------------------------------')
# print(table)
# 找到所有的tr标签,并且把前2个过滤掉
trs = table.find_all('tr')[2:]
# enumerate(trs) 返回2个值,第1个是下标索引,第2个是下标索引对应的值
for index, tr in list(enumerate(trs)):
# print(tr)
# 找到td标签里的城市和对应的温度
tds = tr.find_all('td')
city_td = tds[0]
# 解决直辖市和省份的问题,通过判断下标索引值来取第1个值
if index == 0:
city_td = tds[1] # 直辖市也可以,省会也可以
temp_td = tds[-2]
city = list(city_td.stripped_strings)[0] # 城市
temp = list(temp_td.stripped_strings)[0] # 温度
# print('城市:'+city,'温度:'+temp+'℃')
data = {}
data['城市'] = city
data['温度'] = temp + '℃'
city_temp_list.append(data)
# break # 找到北京的所有数据就结束
print(city_temp_list)
return city_temp_list
def saveData(city_temp_list):
with open('china_city_weather_today.csv', 'w', encoding='utf-8', newline='')as file_obj:
writer = csv.DictWriter(file_obj, fieldnames=['城市', '温度'])
writer.writeheader()
writer.writerows(city_temp_list)
def main():
urls = ['http://www.weather.com.cn/textFC/hb.shtml', 'http://www.weather.com.cn/textFC/db.shtml',
'http://www.weather.com.cn/textFC/hd.shtml', 'http://www.weather.com.cn/textFC/hz.shtml',
'http://www.weather.com.cn/textFC/hn.shtml', 'http://www.weather.com.cn/textFC/xb.shtml',
'http://www.weather.com.cn/textFC/xn.shtml', 'http://www.weather.com.cn/textFC/gat.shtml']
data_list = []
for url in urls:
response = get_source(url)
city_temp_list = parse_source(response)
data_list += city_temp_list
saveData(data_list)
if __name__ == '__main__':
main()
CSV (Comma Separated Values),即逗号分隔值(也称字符分隔值,因为分隔符可以不是逗号),是一种常用的文本格式,用以存储表格数据,包括数字或者字符。很多程序在处理数据时都会碰到csv这种格式的文件。python自带了csv模块,专门用于处理csv文件的读取。
1.通过创建writer对象,主要用到2个方法。一个是writerow,写入一行。另一个是writerows写入多行
2.使用DictWriter 可以使用字典的方式把数据写入进去
# ------------------------------------示例1----------------------------------------
import csv
# 1.通过writer对象 writerow或者writerrows
headers = ('name','age','height')
persons = [
('张三','18','180'),
('李四','45','160'),
('杨过','15','170')
]
with open('./person.csv', "w", encoding='utf-8', newline='') as file_obj:
writer = csv.writer(file_obj)
writer.writerow(headers)
for data in persons:
writer.writerow(data)
# ------------------------------------示例2----------------------------------------
headers = ('name','age','height')
persons = [
('张三','58','180'),
('李四','45','160'),
('杨过','15','170')
]
with open('./person1.csv', "w", encoding='utf-8', newline='') as file_obj:
writer = csv.writer(file_obj)
writer.writerow(headers)
writer.writerows(persons)
# 2.通过DictWriter对象
# ------------------------------------示例1----------------------------------------
headers = ('name','age','height')
persons = [
{'name':'张三','age':58,'height':180},
{'name':'李四','age':45,'height':160},
{'name':'杨过','age':15,'height':170},
]
with open('./person2.csv', "w", encoding='utf-8', newline='') as file_obj:
d_writer = csv.DictWriter(file_obj,headers)
d_writer.writeheader()
d_writer.writerows(persons)
# ------------------------------------示例2------------------------------------------
import csv
persons = [
{'name':'张三','age':58,'height':180},
{'name':'李四','age':45,'height':160},
{'name':'杨过','age':15,'height':170},
]
with open('persons.csv', 'w', encoding='utf-8', newline='')as file_obj:
d_writer = csv.DictWriter(file_obj,fieldnames=['name','age','height'])
d_writer.writeheader()
d_writer.writerows(persons)
1.通过reader()读取到的每一条数据是一个列表。可以通过下标的方式获取具体某一个值
2.通过DictReader()读取到的数据是一个字典。可以通过Key值(列名)的方式获取数据
import csv
with open('person.csv','r',encoding='utf-8',newline='')as file_obj:
reader = csv.reader(file_obj)
for x in reader:
print(x)
print(x[0])
'''
['name', 'age', 'height']
name
['张三', '18', '180']
张三
['李四', '45', '160']
李四
['杨过', '15', '170']
杨过'''
with open('person.csv','r',encoding='utf-8',newline='')as file_obj:
Dreader = csv.DictReader(file_obj)
for x in Dreader:
print(x)
print(x['name'])
'''
OrderedDict([('name', '张三'), ('age', '18'), ('height', '180')])
张三
OrderedDict([('name', '李四'), ('age', '45'), ('height', '160')])
李四
OrderedDict([('name', '杨过'), ('age', '15'), ('height', '170')])
杨过'''