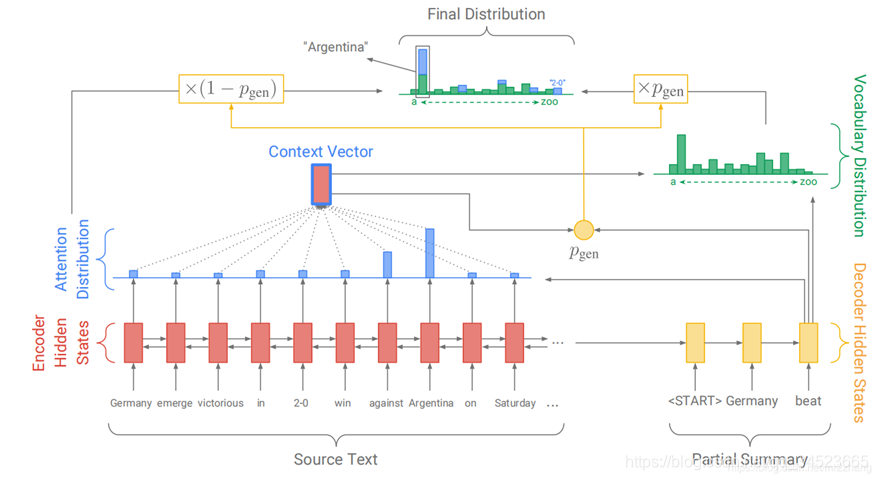
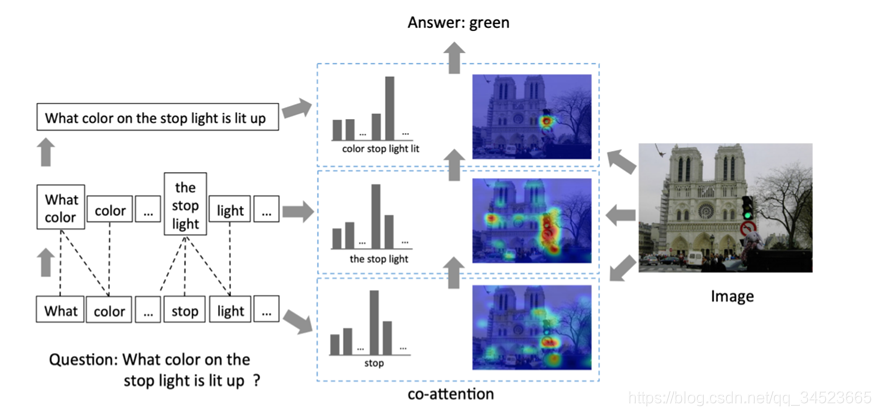
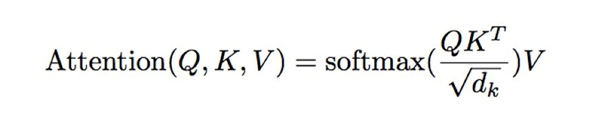self-attention因为Transformer模型而大放异彩,提出Transformer模型的那篇文章《Attention is all you need》的文章题目也是透露出self-attention的强大。不需要循环神经网络,也是能够解决循环神经网络处理的问题,而且性能更优。在后面的博文中,我会详解这篇文章。这里呢,我们先大概感受一下self-attention。下图是Transformer结构。左边部分是编码器(BERT结构),右边部分是解码器(GPT, PGT-2结构)。当然这个是最小单元,真实结构中是多种这样的单元的组合。
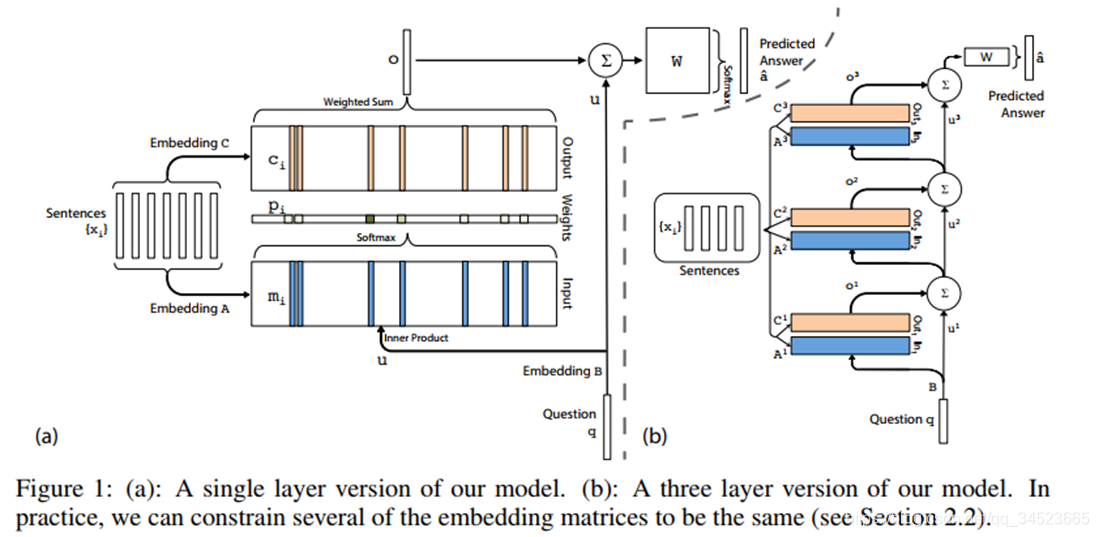
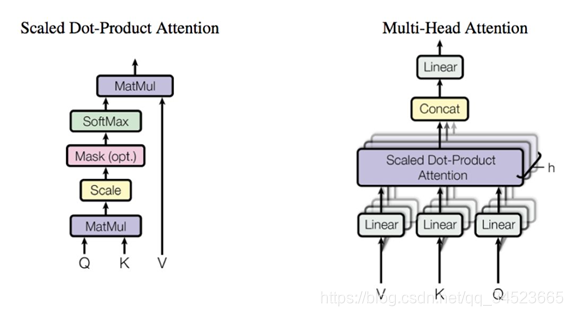
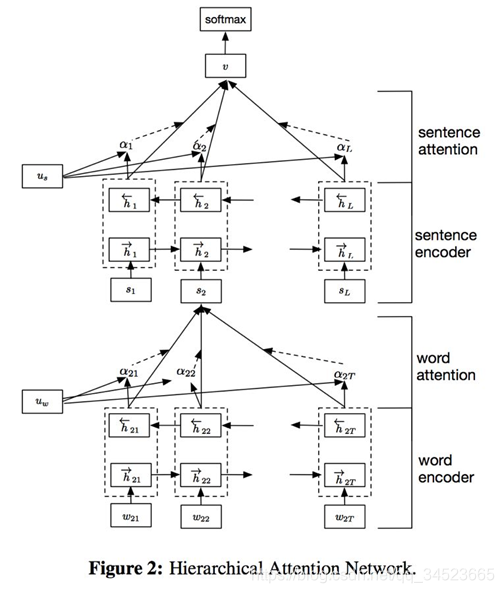
在transformer结构中,self-attention结构尤其关键。将一句话输入后,进过embedding即进入多头注意力机构。嵌入后输入是个三维张量数据。将最后一维(词嵌入这个维度)拆成三份矩阵,并进行矩阵操作: 拆成Q, K ,V三个矩阵,对这三个矩阵进行操作。这就是注意力矩阵的基本思想。这里暂不展开,后续在其他博文中详细介绍。
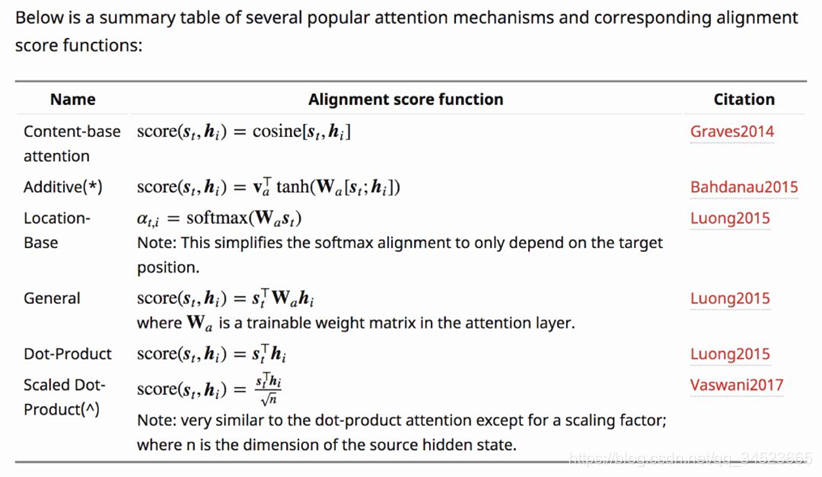
 这里我们用a来代替函数操作,这种函数可以自行确定,但是输入不变。如这样的操作,用两个矩阵参与变换:
这里我们用a来代替函数操作,这种函数可以自行确定,但是输入不变。如这样的操作,用两个矩阵参与变换: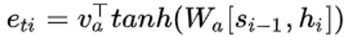
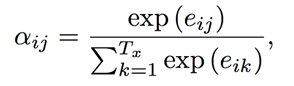
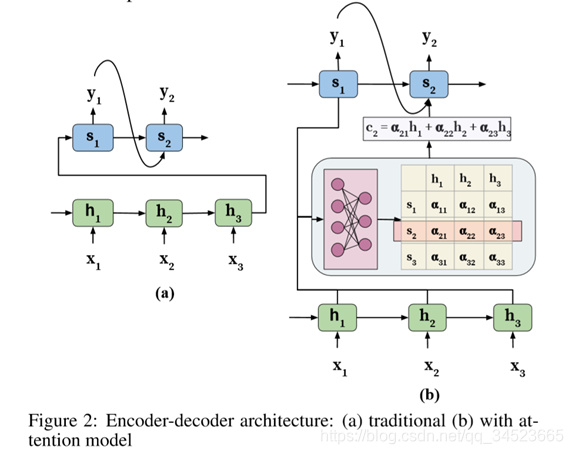
 最后,解码器的隐藏状态就可以加入上下文向量,考虑了整个输入序列及其对应位置关注部分的的信息。
最后,解码器的隐藏状态就可以加入上下文向量,考虑了整个输入序列及其对应位置关注部分的的信息。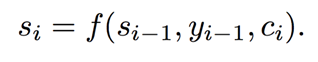 最终的输出:
最终的输出: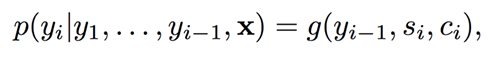
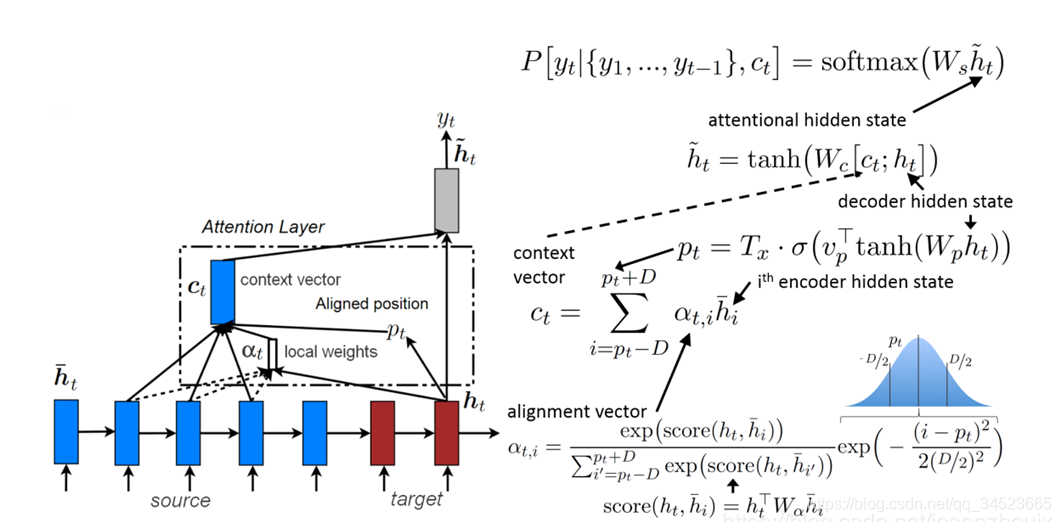
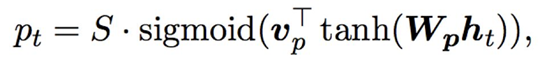 sigmoid是一个概率中,公式中的S是输入序列的长度(图中有点不一样,叫Tx,请读者注意一下)。这样这个滑动的位置也会随着输入序列长度的不同而变化。此外还要注意一下,注意力矩阵的权重相比之前的全局attention还增加了一个高斯分布乘在后面:
sigmoid是一个概率中,公式中的S是输入序列的长度(图中有点不一样,叫Tx,请读者注意一下)。这样这个滑动的位置也会随着输入序列长度的不同而变化。此外还要注意一下,注意力矩阵的权重相比之前的全局attention还增加了一个高斯分布乘在后面: 这也是加入了信息,使得离当前token较远的分配少一些权重,较近的分配近一些的权重。上面就是局部attention原理。
这也是加入了信息,使得离当前token较远的分配少一些权重,较近的分配近一些的权重。上面就是局部attention原理。