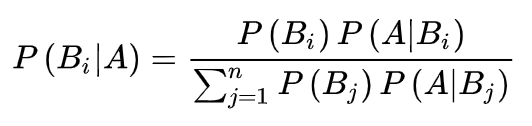朴素贝叶斯是基于贝叶斯决策理论和特征属性独立假设的生成方法。朴素贝叶斯中的朴素是指特征条件独立假设,贝叶斯定理是用来描述两个条件概率之间的关系。上一篇有做一些介绍(朴素贝叶斯算法介绍),这次做一些补充。
1.贝叶斯原理
先验概率 :通过经验来判断事情发生的概率,如全概率公式,它往往作为"由因求果"问题中的"因"出现的概率,比如南方的梅雨季是 6-7 月,就是通过往年的气候总结出来的经验,这个时候下雨的概率就比其他时间高出很多。
后验概率 :后验概率就是发生结果之后,推测原因的概率,是“执果寻因”问题中的"果"。先验概率与后验概率有不可分割的联系,后验概率的计算要以先验概率为基础,比如一本书现在已经被别人借走了(事件已经发生),已知只有可能是张三,李四,王五这3个人借走(事件发生的所有原因)。那么这本书被张三借走的概率会是多大呢?
条件概率 :事件 A 在另外一个事件 B 已经发生条件下的发生概率,表示为 P(A|B),读作“在 B 发生的条件下 A 发生的概率”。比如原因 A 的条件下,发生B的概率,就是条件概率。
image.png
其中P(A)叫做先验概率,P(B|A)叫做条件概率,而我们所求的P(A|B)就叫做后验概率。
2.sklearn中的朴素贝叶斯
三种算法适合应用在不同的场景下,我们应该根据特征变量的不同选择不同的算法:
2.1 高斯朴素贝叶斯(naive_bayes.GaussianNB)
特征变量是连续变量,符合高斯分布,比如说人的身高,物体的长度。
# 导入模块
2.2 多项式朴素贝叶斯(naive_bayes.MultinomialNB)
特征变量是离散变量,符合多项分布,在文档分类中特征变量体现在一个单词出现的次数,或者是单词的 TF-IDF 值等。
# 导入模块
2.3 伯努利朴素贝叶斯(naive_bayes.BernoulliNB)
特征变量是布尔变量,符合 0/1 分布,在文档分类中特征是单词是否出现。
from sklearn.naive_bayes import BernoulliNB
3.TF-IDF
TF-IDF 是一个统计方法,用来评估某个词语对于一个文件集或文档库中的其中一份文件的重要程度。是由TF和IDF的乘积构成,分别代表了词频和逆向文档频率。这样我们倾向于找到 TF 和 IDF 取值都高的单词作为区分,即这个单词在一个文档中出现的次数多,同时又很少出现在其他文档中。这样的单词适合用于分类。
词频 TF :计算了一个单词在文档中出现的次数,它认为一个单词的重要性和它在文档中出现的次数呈正比。
逆向文档频率 IDF :是指一个单词在文档中的区分度。它认为一个单词出现在的文档数越少,就越能通过这个单词把该文档和其他文档区分开。IDF 越大就代表该单词的区分度越大。
# 通过feature_extraction.text模块中的TfidfVectorizer类查看每个词的权重,将原本出现比较多的词的词压缩,来压缩该词的权重,将原本出现比较次数少的词的词进行拓展,增加我们的权重