声明式 API
到底什么才是“声明式 API”呢?
-
kubectl apply 命令。
- kubectl replace 的执行过程,是使用新的 YAML 文件中的 API 对象,替换原有的 API 对象;而 kubectl apply,则是执行了一个对原有 API 对象的 PATCH 操作。
- kube-apiserver 在响应命令式请求(比如,kubectl replace)的时候,一次只能处理一个写请求,否则会有产生冲突的可能。而对于声明式请求(比如,kubectl apply),一次能处理多个写操作,并且具备 Merge 能力。
- Kubernetes“声明式 API”的独特之处:
- 首先,所谓“声明式”,指的就是我只需要提交一个定义好的 API 对象来“声明”,我所期望的状态是什么样子。
- 其次,“声明式 API”允许有多个 API 写端,以 PATCH 的方式对 API 对象进行修改,而无需关心本地原始 YAML 文件的内容。
- 最后,也是最重要的,有了上述两个能力,Kubernetes 项目才可以基于对 API 对象的增、删、改、查,在完全无需外界干预的情况下,完成对“实际状态”和“期望状态”的调谐(Reconcile)过程。
- 声明式 API,才是 Kubernetes 项目编排能力“赖以生存”的核心所在。
在 Kubernetes 项目中,一个 API 对象在 Etcd 里的完整资源路径,是由:Group(API 组)、Version(API 版本)和 Resource(API 资源类型)三个部分组成的。
-
通过这样的结构,整个 Kubernetes 里的所有 API 对象,实际上就可以用如下的树形结构表示出来:
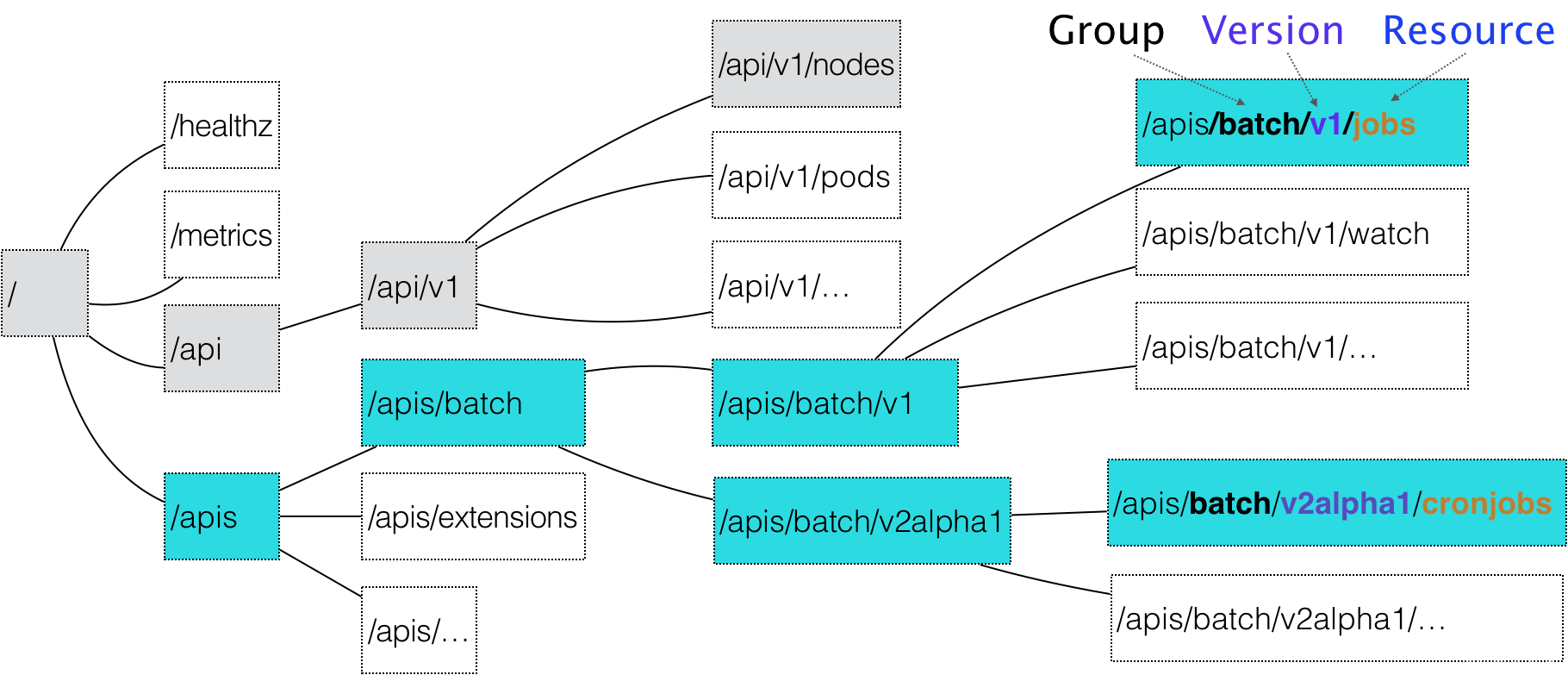
-
可以很清楚地看到Kubernetes 里 API 对象的组织方式,其实是层层递进的。
- 比如,现在我要声明要创建一个 CronJob 对象,那么我的 YAML 文件的开始部分会这么写:
apiVersion: batch/v2alpha1
kind: CronJob
...
- 在这个 YAML 文件中,“CronJob”就是这个 API 对象的资源类型(Resource),“batch”就是它的组(Group),v2alpha1 就是它的版本(Version)。
- 提交了这个 YAML 文件之后,Kubernetes 就会把这个 YAML 文件里描述的内容,转换成 Kubernetes 里的一个 CronJob 对象。
Kubernetes 是如何对 Resource、Group 和 Version 进行解析,从而在 Kubernetes 项目里找到 CronJob 对象的定义呢?
- 首先,Kubernetes 会匹配 API 对象的组。
- 对于 Kubernetes 里的核心 API 对象,比如:Pod、Node 等,是不需要 Group 的(即:它们 Group 是“”)。所以,对于这些 API 对象来说,Kubernetes 会直接在 /api 这个层级进行下一步的匹配过程。
- 而对于 CronJob 等非核心 API 对象来说,Kubernetes 就必须在 /apis 这个层级里查找它对应的 Group,进而根据“batch”这个 Group 的名字,找到 /apis/batch。
- 不难发现,这些 API Group 的分类是以对象功能为依据的,比如 Job 和 CronJob 就都属于“batch” (离线业务)这个 Group。
- 然后,Kubernetes 会进一步匹配到 API 对象的版本号。
- 对于 CronJob 这个 API 对象来说,Kubernetes 在 batch 这个 Group 下,匹配到的版本号就是 v2alpha1。
- 在 Kubernetes 中,同一种 API 对象可以有多个版本,这正是 Kubernetes 进行 API 版本化管理的重要手段。这样,比如在 CronJob 的开发过程中,对于会影响到用户的变更就可以通过升级新版本来处理,从而保证了向后兼容。
- 最后,Kubernetes 会匹配 API 对象的资源类型。
- 在前面匹配到正确的版本之后,Kubernetes 就知道,要创建的原来是一个 /apis/batch/v2alpha1 下的 CronJob 对象。
- 这时候,APIServer 就可以继续创建这个 CronJob 对象了。为了方便理解,总结了一个如下所示流程图来阐述这个创建过程:
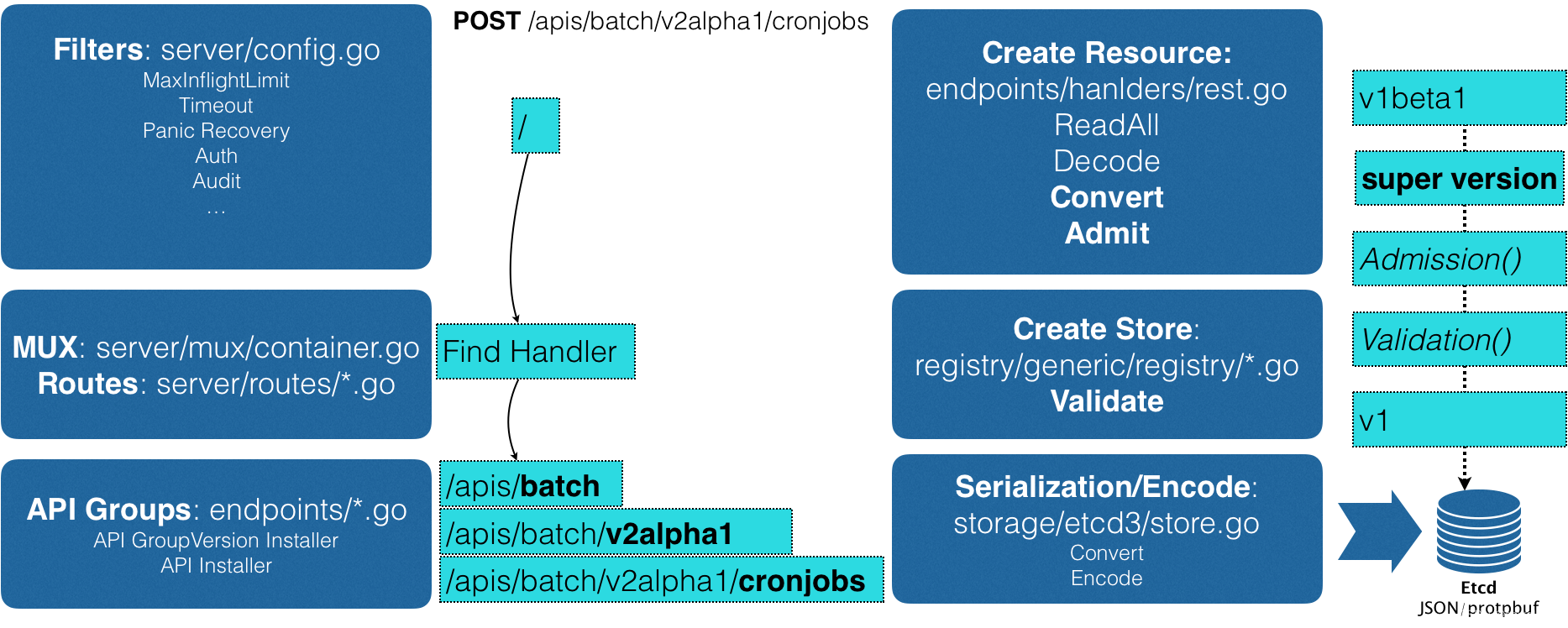
- 首先,当发起了创建 CronJob 的 POST 请求之后,将编写的 YAML 的信息就被提交给了 APIServer。而 APIServer 的第一个功能,就是过滤这个请求,并完成一些前置性的工作,比如授权、超时处理、审计等。
- 然后,请求会进入 MUX 和 Routes 流程。如果你编写过 Web Server 的话就会知道,MUX 和 Routes 是 APIServer 完成 URL 和 Handler 绑定的场所。而 APIServer 的 Handler 要做的事情,就是按照刚刚介绍的匹配过程,找到对应的 CronJob 类型定义。
- 接着,APIServer 最重要的职责就来了:根据这个 CronJob 类型定义,使用用户提交的 YAML 文件里的字段,创建一个 CronJob 对象。而在这个过程中,APIServer 会进行一个 Convert 工作,即:把用户提交的 YAML 文件,转换成一个叫作 Super Version 的对象,它正是该 API 资源类型所有版本的字段全集。这样用户提交的不同版本的 YAML 文件,就都可以用这个 Super Version 对象来进行处理了。
- 接下来,APIServer 会先后进行 Admission() 和 Validation() 操作。比如,Admission Controller 和 Initializer,就都属于 Admission 的内容。而 Validation,则负责验证这个对象里的各个字段是否合法。这个被验证过的 API 对象,都保存在了 APIServer 里一个叫作 Registry 的数据结构中。也就是说,只要一个 API 对象的定义能在 Registry 里查到,它就是一个有效的 Kubernetes API 对象。
- 最后,APIServer 会把验证过的 API 对象转换成用户最初提交的版本,进行序列化操作,并调用 Etcd 的 API 把它保存起来。
由此可见,声明式 API 对于 Kubernetes 来说非常重要。所以,APIServer 这样一个在其他项目里“平淡无奇”的组件,却成了 Kubernetes 项目的重中之重。
编写自定义控制器
你知道的越多,你不知道的越多。