一、in和exsits
1.1 原则
小表驱动大表,即小的数据集驱动大的数据集
1.2 in
适用场景:当B表的数据集小于A表的数据集时,in优于exists
select * from A where id in (select id from B)
可以先思考下,是括号里面的SQL先执行还是外面先执行???
绝大数情况下是括号里面的SQL先执行,也有些特殊情况,和数据量相关,可能是外面的先执行。
在这里我们讨论括号里面先执行的情况。
实际上就是先执行括号里面的SQL,然后把外面的SQL放在里面SQL执行的结果集中逐行关联比对。
#等价于
for(select id from B){
select * from A where A.id = B.id
}
B 表的数据量越小,for循环的次数就越少
1.3 exsits
适用场景:当A表的数据集小于B表的数据集时,exists优于in
select * from A where exists (select 1 from B where B.id = A.id)
基于上面in的SQL,上述SQL是外面的语句先执行。
实际上就是先把外面的SQL语句结果集查出来,然后逐行放到子查询B中做条件验证,看能否查到数据(返回true或false),返回true的数据会被放入最终的结果集中。
#等价于:
for(select * from A){
select * from B where B.id = A.id
}
#A表与B表的ID字段应建立索引
1、EXISTS (subquery)只返回TRUE或FALSE,因此子查询中的SELECT * 也可以用SELECT 1替换,官方说法是实际执行时会 忽略SELECT清单,因此没有区别
2、EXISTS子查询的实际执行过程可能经过了优化而不是我们理解上的逐条对比
3、EXISTS子查询往往也可以用JOIN来代替,何种最优需要具体问题具体分析
二、count(*)
表结构如下:
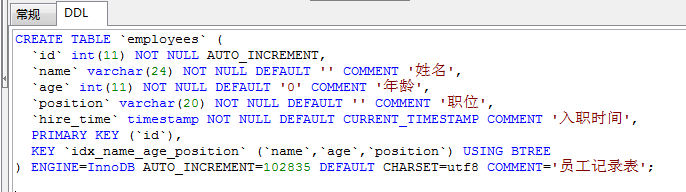
临时关闭mysql查询缓存,为了查看sql多次执行的真实时间
set global query_cache_size=0;
set global query_cache_type=0;
现在有如下四条SQL
select count(1) from employees;
select count(id) from employees;
select count(name) from employees;
select count(*) from employees;
哪一条SQL查询的效率会高一点呢??是count(常量)、count(主键)、count(非主键字段)、还是count(*)呢?
2.1 分析下count(非主键字段)
select count(name) from employees;
name是非主键字段,位于联合索引中,所以底层实际上是会扫描联合索引非主键树,一个个扫描,每扫描一个就把值+1,当扫描到null值的时候不会加1
2.2 分析下count(主键字段)
select count(id) from employees;
id是主键字段,位于主键索引中,所以底层实际上是会扫描主键索引树,一个个扫描,每扫描一个就把值+1,(由于主键是不允许为空的,所以这里不考虑空值)。
2.3 count不同字段对比
到这里,大家可以思考下:
①、count(name) 效率高一点还是count(id)效率高一点?
答count(name)效率比较高。 在之前MySQL的索引介绍中有提到过,因为二级索引相对主键索引存储数据更少(二级索引只会存储对应数据的主键数据,而主键索引会存储所该条数据的所有 字段),查询的性能应该更高
②、count(name)效率高还是count(1)效率高?
答:count(1)效率比较高。count(1)和count(name)最终使用的都是二级索引,大体上性能是差不多的,但是count(1)只会遍历索引树,不会把name字段取出来,而count(name)在遍历索引树时,会把对应的字段取出来,底层可能会对字段进行一些编解码之类的操作,二者就是差了这个时间。
③、count(id)效率高还是count(*)效率高?
这个可能难理解,可以先用explain来看下结果,也是扫描的二级索引树,所以相对来比count(id)效率高。
所以,总的来说就是:count(1) > count(name) > count(*) > count(id)
(ps:在MySQL5.7的版本中,count(id)已被优化,实际上走的是二级索引,而不是主键索引)
总结:
四个sql的执行效率几乎差不多,区别在于根据某个字段count不会统计字段为null值的数据行
2.4 常见的优化方式
2.4.1 查询mysql自己维护的总行数
对于myisam存储引擎的表做不带where条件的count查询性能是很高的,因为myisam存储引擎的表的总行数会被 mysql存储在磁盘上,查询不需要计算

对于innodb存储引擎的表,mysql不会存储表的总记录行数,查询count需要实时计算
2.4.2 show table status
如果只需要知道表总行数的估计值可以用如下sql查询,性能很高

2.4.3 将总数维护到Redis里
插入或删除表数据行的时候同时维护redis里的表总行数key的计数值(用incr或decr命令),但是这种方式可能不准,很难保证表操作和redis操作的事务一致性
2.4.4 增加数据库计数表
插入或删除表数据行的时候同时维护计数表,让他们在同一个事务里操作
更多优化,可前往分页查询、JOIN关联查询优化进行查看。