EAGLE是一种基于最大团聚类的层次聚类算法,用来揭示网络的层次化和层次化社区结构。该算法采用一种聚类框架,来处理最大派系。
1.算法的实现:
首先用Bron-Kerbosch算法找到网络中的最大派系,要设置一个阈值k来丢弃所有小于K的最大派系,通常k取3-6之间的值。算法分为两个阶段:第一阶段生成树状图;第二阶段选着合适的切割点,将树状图分成群落。
第一阶段:
(1)找出网络中的最大派系,忽略最大的子派系,其余作为初始社区
(2)选择相似度最大的一对群落,将其合并到新的群落中,计算新群落与其他群落的相似度
(3)重复步骤(2)直到只剩一个社区
社区c1与c2相似度M:(Avw是网络邻接矩阵的元素(点v,w间有边为1,无边为0),kv是点v的度。)

第二阶段:计算EQ,选取EQ最大值为切割点,对树状图进行切割,EQ公式:(其中Ov是顶点v所属的社区数)
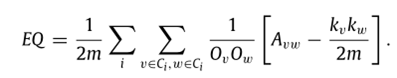
2.论文中的数据集保存为eagle.txt(数据集在下方4中给出),注意:下标从1开始的数据集用此段代码
import networkx as nx
import matplotlib.pyplot as plt
import numpy as np
#存储社区合并时产生的二叉树
class Dendrogram:
def __init__(self,root):
self.data = root
self.left = None
self.right = None
def insertL(self,data): #由于树是从下向上生成所以插入左右孩节点的函数没有用到
if self.left == None:
self.left = Dendrogram(data)
elif self.right == None:
self.right = Dendrogram(data)
else:
self.insert(self.left,data)
def insertR(self,data): #没有用到
if self.left == None:
self.left = Dendrogram(data)
elif self.right == None:
self.right = Dendrogram(data)
else:
self.insert(self.right,data)
def printT(self): #递归线序遍历整棵社区树
print("输出根")
print(self.data)
if self.left != None:
print("输出左")
self.left.printT()
if self.right != None:
print("输出右")
self.right.printT()
# def getR(self):
# return self.right
# def getL(self):
# return self.left
# def getR(self):
# return root
# def setR(self,data):
# self.data = data
#eagle算法的实现
class ELAGE():
def __init__(self,G):
self.G = G #用于存放图
self.admatrix = np.array(nx.adjacency_matrix(G).todense())#存放图的邻接矩阵
# print(self.admatrix)
m=0 #计算图的总边数(因为是无向图,多计算了一遍)
for i in self.admatrix:
for j in i:
if j == 1:m=m+1
m = m/2
self.m = m #存放图的边数
# print(self.m)
# self.dendrogram = None #存放树形图(当作指针的话会把两个没有连接的树丢失,只能使用列表先保存)
self.dendrogram = [] #存放合并过程中产生的树形图,合并时与存放派系的列表p相结合
self.maxEq = {-1:[0]} #字典的键放EQ的最大值,字典的值存放产生EQ最大值时社区的状态
self.surface = []
def get_vd(self,v): #获取节点v的度
d = 0
for i in self.admatrix[v]:
d = d+i
return d
def finess(self,c1,c2): #相似度M函数
M = 0
for i in c1:
for j in c2:
# print(self.get_vd(i-1),self.get_vd(j-1),self.get_vd(i-1)*self.get_vd(j-1)/(2*self.m))
if i != j:
M += self.admatrix[i-1][j-1]-(self.get_vd(i-1)*self.get_vd(j-1))/(2*self.m) #注意2*self.m要加括号,否则会变成(self.get_vd(i-1)*self.get_vd(j-1)/2)*self.m
M = M/(2*self.m) #注意上边的i-1,j-1是因为这组数据从1开始,而数组下标从0开始,为了方便直接减1,其他数据集得改
return M
"""
createDendrogram(self,k)用于生成社区树,并在生成树的同时计算所EQ的最大值
列表p用于存放大于k的最大派系,与self.dendrogram(存放计算过程中产生的树结构,计算过程中两个树结构开始并不相连,所以这里用列表)一起使用
从p中两两计算相似度,将产生最大相似度的两个社区合并为树(两个社区分别是左右子树,两社区的并集作为根结点),产生的树结构存放在self.dendrogram中
将两个合并的派系从p中删除,将合并后的根节点的数据再加入p中,供之后计算相似度再次合并
最终:
列表p中只有一个所有节点组成的社区
列表self.dendrogram中只有一个所有节点组成的树
注意:
self.dendrogram中每一个树结构的根(合并后的派系)都再p中有一份
因此下边可以将p中的社区换成树结构
"""
def createDendrogram(self,k):
p = [i for i in nx.find_cliques(G) if len(i) >= k] #节点数大于k的最大派系存在列表P中,从列表p中两两计算相似度
while len(p)>1: #p中只剩所有节点组成的一个社区时结束
max =float('-inf') #负无穷,max存放最大相似度
a = -1 #a,b存放两个相似度M最大时两个派系在p中的下标
b = -1
for i in range(len(p)-1): #i从p的第一个到倒数第二个取派系
for j in range(i+1,len(p)): #j从i的下一个到最后一个取派系
# print(self.finess(p[i],p[j]),max)
if self.finess(p[i],p[j]) > max: #如果此时的相似度大于最大相似度时,将最大相似度赋值给max
# print(i,j,self.finess(p[i],p[j]))
max = self.finess(p[i],p[j])
a = i #记录产生最大相似度的两个派系的下标
b = j
# print(max,p[a],p[b],a,b,i,j)
l = Dendrogram(p[a]) #将两个派系作为左右子树存如l,r中
r = Dendrogram(p[b])
flagl = False #flagl,flagr标记这两个派系是否为已存在树结构的根节点(在self.dendrogram中),False代表不是,True代表是
flagr = False
for i in range(len(self.dendrogram)):
if p[a] == self.dendrogram[i].data: #是树结构的话让l指向以存在的树结构,不再生成新的树(因为新的树没有显示层次的子树)
l = self.dendrogram[i]
flagl = True #将flag改为True
if p[b] == self.dendrogram[i].data:
r = self.dendrogram[i]
flagr = True
if flagl: #左子树在self.dendrogram中的话,从self.dendrogram列表中把他删掉(因为他要作为新生成树的一部分)
self.dendrogram.remove(l)
if flagr:
self.dendrogram.remove(r)
father = Dendrogram(list(set(p[a]).union(set(p[b])))) #计算两个派系的并集,作为新生成树的根节点
father.left = l #让树的左子树等于l,右子树等于r
father.right = r
self.dendrogram.append(father) #将新生成的树再加入到self.dendrogram列表中(为将来最为下一棵树的一部分)
# print(p[a],p[b],a,b,max)
# p.remove(p[a])
# p.remove(p[b]) #将列表p中的p[a]删除后,下表会改变,再用b时就会溢出,所以这因该b=b-1
p.remove(father.left.data) #将两个已经合并的派系从列表p中删除
p.remove(father.right.data)
p.append(father.data) #将两个派系合并后的社区加入到p中继续计算相似度M
eq = self.EQ(p) #合并了派系就计算模块度(从下向上计算,若合并好树后再计算会很困难)
if eq > list(self.maxEq.keys())[0]: #若EQ大于最大的EQ值
self.maxEq.clear() #亲空记录,最大EQ和社区状态的字典
# self.maxEq[eq] = p #注意列表复制时不能这样写,这样是同一个地址不是拷贝
self.maxEq[eq] = p[:] #将新的最大EQ作为字典的key,先将此时的p作为状态存为字典的值(此时的状态不是树结构,无法查看层次)
for i in self.dendrogram: #将此时所有的树结构(合并起来的社区)的根那一项从p中删除
self.maxEq[eq].remove(i.data)
self.maxEq[eq].append(i) #将树结构存社区划分入状态中,也就是把p中的表层社区换为树形社区,这样可以查看层次
self.surface = p[:] #self.surface记录表层(最大曾=社区)的划分
def printComHier(self): #按层次输出社区结构(往下多输出一层,当然要是想的话可以一直看到叶节点)
commresult = list(self.maxEq.values())[0]
for i in commresult:
if type(i) is list: #注意self.maxEq的value中有叶子节点(最小社区,直接是列表),也有合并后的树(大社区)
print(i) #如果是列表直接输出,如果是树,往下输出一层
else:
print(i.data,"由以下社区组成:",i.left.data,i.right.data)
def get_Ov(self,v,communitys): #communitys = [[1],[2],[3]] 计算V属于的社区数,EQ公式中的Ov
Ov = 0
for i in communitys:
if v in i:
Ov += 1
return Ov
def EQ(self,communitys): #计算EQ的公式
eq = 0
for i in communitys:
for j in range(len(i)-1):
for k in range(j+1,len(i)):
#get_Ov()中不用管,其他的-1得考虑是否去掉
eq += (self.admatrix[i[j]-1][i[k]-1] - self.get_vd(i[j]-1)*self.get_vd(i[k]-1)/(2*self.m))/(self.get_Ov(i[j],communitys)*self.get_Ov(i[k],communitys))
eq = eq/(2*self.m)
return eq
G = nx.Graph() #生成空图,将论文中的的数据导入
with open("eagle.txt") as f:
for line in f:
a,b = line.split()
G.add_edge(int(a),int(b))
# print(a,b)
f.close()
e = ELAGE(G)
e.createDendrogram(3)
print("MaxEq:",e.maxEq) #最大EQ和社区划分结果
#输出分层结构(往下输出一层)
e.printComHier()
#输出表层社区划分
print("表层结构:",e.surface)
nx.draw(G,with_labels=True)
plt.show()
运行结果如图所示:

3.对海豚数据集的划分代码(论文中的数据集是从1开始,而海豚是从0开始),这部分只是处理了下标(下标从0开始用此数据集)
import networkx as nx
import matplotlib.pyplot as plt
import numpy as np
class Dendrogram:
def __init__(self,root):
self.data = root
self.left = None
self.right = None
def insertL(self,data):
if self.left == None:
self.left = Dendrogram(data)
elif self.right == None:
self.right = Dendrogram(data)
else:
self.insert(self.left,data)
def insertR(self,data):
if self.left == None:
self.left = Dendrogram(data)
elif self.right == None:
self.right = Dendrogram(data)
else:
self.insert(self.right,data)
def printT(self):
print("输出根")
print(self.data)
if self.left != None:
print("输出左")
self.left.printT()
if self.right != None:
print("输出右")
self.right.printT()
# def getR(self):
# return self.right
# def getL(self):
# return self.left
# def getR(self):
# return root
# def setR(self,data):
# self.data = data
class ELAGE():
def __init__(self,G):
self.G = G
self.admatrix = np.array(nx.adjacency_matrix(G).todense())#邻接矩阵
m=0
for i in self.admatrix:
for j in i:
if j == 1:m=m+1
m = m/2
self.m = m #图的边数
# self.dendrogram = None #存放树形图(当作指针的话会把两个没有连接的树丢失,只能使用列表先保存)
self.dendrogram = [] #存放树形图
self.maxEq = {-1:[0]}
self.surface = []
def get_vd(self,v): #获取节点v的度
d = 0
for i in self.admatrix[v]:
d = d+i
return d
def finess(self,c1,c2):
M = 0
for i in c1:
for j in c2:
# print(self.get_vd(i-1),self.get_vd(j-1),self.get_vd(i-1)*self.get_vd(j-1)/(2*self.m))
M += self.admatrix[i][j]-self.get_vd(i)*self.get_vd(j)/(2*self.m) #注意2*self.m要加括号,否则会变成(self.get_vd(i-1)*self.get_vd(j-1)/2)*self.m
M = M/(2*self.m) #注意上边的i-1,j-1是因为这组数据从1开始,而数组下标从0开始,为了方便直接减1,其他数据集得改
return M
def createDendrogram(self,k):
p = [i for i in nx.find_cliques(G) if len(i) >= k]
while len(p)>1:
max =float('-inf') #负无穷
a = -1
b = -1
for i in range(len(p)-1):
for j in range(i+1,len(p)):
# print(self.finess(p[i],p[j]),max)
if self.finess(p[i],p[j]) > max:
# print(i,j,self.finess(p[i],p[j]))
max = self.finess(p[i],p[j])
a = i
b = j
# print(max,p[a],p[b],a,b,i,j)
l = Dendrogram(p[a])
r = Dendrogram(p[b])
flagl = False
flagr = False
for i in range(len(self.dendrogram)):
if p[a] == self.dendrogram[i].data:
l = self.dendrogram[i]
flagl = True
if p[b] == self.dendrogram[i].data:
r = self.dendrogram[i]
flagr = True
if flagl:
self.dendrogram.remove(l)
if flagr:
self.dendrogram.remove(r)
father = Dendrogram(list(set(p[a]).union(set(p[b]))))
# self.dendrogram = Dendrogram(list(set(p[a]).union(set(p[b]))))
# self.dendrogram.left = l
# self.dendrogram.right = r
father.left = l
father.right = r
self.dendrogram.append(father)
# print(self.dendrogram)
# print("合左右")
# print(self.dendrogram.data,self.dendrogram.left.data,self.dendrogram.right.data)
# print(p[a],p[b],a,b,max)
# p.remove(p[a])
# p.remove(p[b]) #将列表p中的p[a]删除后,下表会改变,再用b时就会溢出,所以这因该b=b-1
p.remove(father.left.data)
p.remove(father.right.data)
p.append(father.data)
# print(p)
# print("=====")
eq = self.EQ(p)
# print(eq)
# print(list(self.maxEq.keys())[0])
if eq > list(self.maxEq.keys())[0]:
self.maxEq.clear()
# self.maxEq[eq] = p #注意列表复制时不能这样写,这样是同一个地址不是拷贝
self.maxEq[eq] = p[:]
for i in self.dendrogram:
self.maxEq[eq].remove(i.data)
self.maxEq[eq].append(i)
self.surface = p[:]
def printComHier(self):
commresult = list(self.maxEq.values())[0]
for i in commresult:
if type(i) is list:
print(i)
else:
print(i.data,"由以下社区组成:",i.left.data,i.right.data)
def get_Ov(self,v,communitys): #communitys = [[1],[2],[3]]
Ov = 0
for i in communitys:
if v in i:
Ov += 1
return Ov
def EQ(self,communitys):
eq = 0
for i in communitys:
for j in range(len(i)-1):
for k in range(j+1,len(i)):
#get_Ov()中不用管,其他的-1得考虑是否去掉
eq += (self.admatrix[i[j]][i[k]] - self.get_vd(i[j])*self.get_vd(i[k])/(2*self.m))/(self.get_Ov(i[j],communitys)*self.get_Ov(i[k],communitys))
eq = eq/(2*self.m)
return eq
G = nx.read_gml("dolphins.gml",label="id")
e = ELAGE(G)
e.createDendrogram(3)
# e.dendrogram[0].printT()
# print(e.EQ([e.dendrogram[0].left.data,e.dendrogram[0].right.data]))
print(e.maxEq)
#输出分层结构(往下输出一层)
e.printComHier()
#输出表层社区划分
print("表层:",e.surface)
nx.draw(G,with_labels=True)
plt.show()
结果如下图所示:

4.论文中的数据集(复制存入eagle.txt可用以第一段代码中):
1 2
1 3
1 4
1 5
1 6
2 3
2 4
2 5
2 6
3 4
3 5
3 6
3 8
4 5
4 6
5 6
5 22
4 23
20 21
20 22
20 23
20 18
21 23
18 19
18 20
18 21
18 22
18 23
19 22
19 23
22 23
17 18
17 19
3 7
3 8
3 13
7 8
7 9
7 10
7 13
7 12
8 9
8 10
8 11
8 12
8 13
9 10
10 13
10 14
10 15
10 16
10 17
11 12
11 13
11 16
11 17
12 13
12 14
12 16
12 17
14 15
14 16
14 17
15 16
15 17
16 17
参考文献:
[1]Detect overlapping and hierarchical community structure in networks