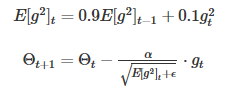h
θ
(
x
)
=
θ
0
+
θ
1
x
1
+
θ
2
x
2
h_\theta(x)=\theta_0+\theta_1x_1+\theta_2x_2
hθ(x)=θ0+θ1x1+θ2x2
J
(
θ
)
=
1
2
m
∑
i
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
J(\theta)=\frac{1}{2m} \sum_i^m(h_\theta(x^{(i)})-y^{(i)})^2
J(θ)=2m1∑im(hθ(x(i))−y(i))2
每个样本
X
X
X是一个
1
×
n
1\times n
1×n的向量,即$X=[x1,x2,x3,…,xn],每个向量代表一个特征,每个参数对应一个特征的权重,所以每个样本对应的参数也是n维的。
对参数
θ
1
\theta_1
θ1的更新:
∂
J
(
θ
)
∂
θ
1
=
1
m
∑
i
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
⋅
x
(
1
)
\frac{\partial J(\theta)}{\partial _{\theta_1}}=\frac{1}{m}\sum_i^m(h_\theta(x^{(i)})-y^{(i)})\cdot x^{(1)}
∂θ1∂J(θ)=m1∑im(hθ(x(i))−y(i))⋅x(1)
θ
1
=
θ
1
−
η
⋅
1
m
∑
i
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
⋅
x
(
1
)
\theta_1=\theta_1-\eta\cdot \frac{1}{m}\sum_i^m(h_\theta(x^{(i)})-y^{(i)})\cdot x^{(1)}
θ1=θ1−η⋅m1∑im(hθ(x(i))−y(i))⋅x(1)
对参数
θ
2
\theta_2
θ2的更新:
∂
J
(
θ
)
∂
θ
2
=
1
m
∑
i
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
⋅
x
(
2
)
\frac{\partial J(\theta)}{\partial _{\theta_2}}=\frac{1}{m}\sum_i^m(h_\theta(x^{(i)})-y^{(i)})\cdot x^{(2)}
∂θ2∂J(θ)=m1∑im(hθ(x(i))−y(i))⋅x(2)
θ
2
=
θ
2
−
η
⋅
1
m
∑
i
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
⋅
x
(
2
)
\theta_2=\theta_2-\eta\cdot \frac{1}{m}\sum_i^m(h_\theta(x^{(i)})-y^{(i)})\cdot x^{(2)}
θ2=θ2−η⋅m1∑im(hθ(x(i))−y(i))⋅x(2)
在预测参数下一次的位置之前,我们已有当前的参数和动量项,先用
(
θ
−
γ
v
t
−
1
)
(\theta-\gamma v_{t-1} )
(θ−γvt−1)作为参数下一次出现位置的预测值,虽然不准确,但是大体方向是对的,之后用我们预测到的下一时刻的值来求偏导,让优化器高效的前进并收敛。
v
t
=
γ
v
t
−
1
+
η
∂
J
(
θ
−
γ
v
t
−
1
)
∂
θ
v_t=\gamma v_{t-1}+\eta\frac{\partial J(\theta-\gamma v_{t-1} \,\,\,\,)}{\partial \theta}
vt=γvt−1+η∂θ∂J(θ−γvt−1)
θ
=
θ
−
v
t
\theta=\theta-v_t
θ=θ−vt
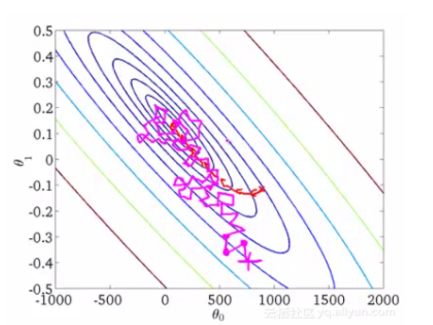
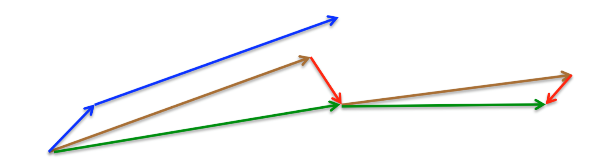
Momentum更新方式:
计算当前的梯度值(小蓝色方向向量)
⟹
\implies
⟹在更新后的累积方向上前进一大步
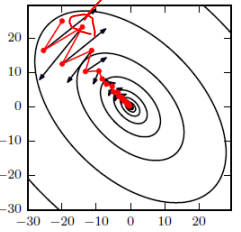
Nesterov Momentum更新方式:
按照原来的更新方向更新一步(棕色线)
⟹
\implies
⟹然后在该位置计算梯度值(红色线)
⟹
\implies
⟹利用该梯度值修正最终的更新方向(绿色线)
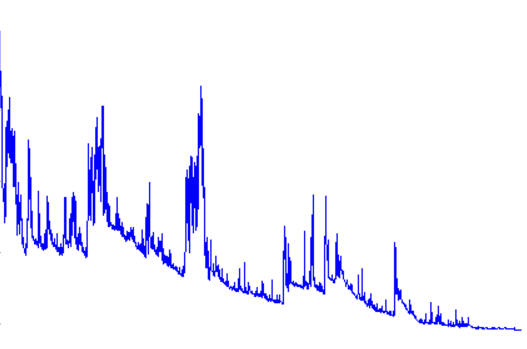
七、Adagrad法
该方法是基于梯度的优化方法,其主要功能是:对于不同的参数使用不同的学习率,适合于处理稀疏数据。
对低频出现的参数进行大的更新
对高频出现的参数进行小的更新
对迭代次数为
t
t
t时,对参数
θ
i
\theta_i
θi求目标函数的梯度:
g
t
,
i
=
∂
J
(
θ
t
,
i
)
∂
θ
t
,
i
g_{t,i}=\frac{\partial J(\theta_{t,i}\,\,)}{\partial \theta_{t,i}}
gt,i=∂θt,i∂J(θt,i)
Adagrad将学习率
η
\eta
η进行了修正,对迭代次数t,基于每个参数之前计算的梯度值,将每个参数的学习率
η
\eta
η按如下方式修正:
θ
t
+
1
,
i
=
θ
t
,
i
−
η
G
t
,
i
i
+
ξ
⋅
g
i
,
t
\theta_{t+1,i}=\theta_{t,i}-\frac{\eta}{\sqrt {G_{t,ii}+\xi}} \cdot g_{i,t}
θt+1,i=θt,i−Gt,ii+ξη⋅gi,t