深度学习预处理实战(中英文互译)
前言
基于深度学习的机器翻译学习分为三步:
(1)解决自动将一种自然语言文本(源语言)翻译为另一种自然语言文本(目标语言)的问题。
(2)准备人工翻译的数据集,将其分成训练集和测试集。使用训练集的数据来训练深度神经网络。
(3)使用测试集的数据来评估模型表现。
深度学习机器翻译其实是用神经网络去学习人工翻译的数据集,使数学世界的神经网络成为取代真实世界中人工翻译的可计算模型。
一、获取中英互译的数据集
要进行深度学习的预训练和后续的训练,需要寻找一个合适的数据集。本数据集来自Manythings.org一家公益英语学习网站。这里我们可以看一下数据集的结构:

资源一直传不上去,给大家分享一个百度网盘链接提取链接:https://pan.baidu.com/s/1crPPSXtzaY1efyBLWprm-g?pwd=17eh
提取码:17eh
二、具体步骤
这里分步为讲解来大家容易理解,文章结尾附上完整代码,大家可以直接运行
1.首先引入相关库
代码如下(示例):库的下载直接pip即可,这里我不多赘述,由于是预处理,大家可以直接在cpu上运行不需要GPU
import tensorflow as tf
from sklearn.model_selection import train_test_split
import re
import io
import jieba
jieba.initialize() # 手动初始化jieba资源,提高分词效率。
jieba.enable_paddle() # 启动paddle模式。 0.40版之后开始支持,早期版本不支持
2.中英文预处理
代码如下(示例):
这里判断是否为中文或者英文,再对中英文预处理为我们需要的格式,将中文按照字处理。
判断是否包含中文
#判断是否包含中文
def is_chinese(string):
"""
检查整个字符串是否包含中文
:param string: 需要检查的字符串
:return: bool
"""
for ch in string:
if u'\u4e00' <= ch <= u'\u9fa5':
return True
return False
#中英文预处理
def preprocess_sentence(w):
if is_chinese(w):
w = re.sub(r"[^\u4e00-\u9fa5,。?!]+", "", w)
w = w.strip()
#seg_list = jieba.cut(w,use_paddle=True) # 使用paddle模式分词
#w= ' '.join(list(seg_list))
w=分字(w)
# 给句子加上开始和结束标记
# 以便模型知道每个句子开始和结束的位置
w = '<start> ' + w + ' <end>'
else:
w = w.lower()
# 除了 (a-z, A-Z, ".", "?", "!", ","),将所有字符替换为空格
w = re.sub(r"[^a-zA-Z?.!,]+", " ", w)
w = w.rstrip().strip()
# 给句子加上开始和结束标记
# 以便模型知道每个句子开始和结束的位置
w = '<start> ' + w + ' <end>'
对中文进行分字处理
def 分字(str):
line = str.strip()
pattern = re.compile('[^\u4e00-\u9fa5,。?!]')
zh = ''.join(pattern.split(line)).strip()
result=''
for character in zh:
result+=character+' '
return result.strip()
#调用预处理方法,并返回这样格式的句子对:[chinese, english]
def create_dataset(path, num_examples):
lines = io.open(path, encoding='UTF-8').read().strip().split('\n')
word_pairs = [[preprocess_sentence(w) for w in l.split('\t')[0:2]] for l in lines[:num_examples]]
return zip(*word_pairs)
def max_length(tensor):
return max(len(t) for t in tensor)
#词符化
def tokenize(lang):
lang_tokenizer = tf.keras.preprocessing.text.Tokenizer(filters='')
lang_tokenizer.fit_on_texts(lang)
tensor = lang_tokenizer.texts_to_sequences(lang)
tensor = tf.keras.preprocessing.sequence.pad_sequences(tensor,padding='post')
return tensor, lang_tokenizer
加载数据集,返回输入张量(中文、英文)目标张量(中文、英文)4个张量
# 创建清理过的输入输出对
def load_dataset(path, num_examples=None):
targ_lang, inp_lang = create_dataset(path, num_examples)
input_tensor, inp_lang_tokenizer = tokenize(inp_lang)
target_tensor, targ_lang_tokenizer = tokenize(targ_lang)
return input_tensor, target_tensor, inp_lang_tokenizer, targ_lang_tokenizer
3.主函数运行
if __name__=="__main__":
num_examples = 100
#读取中英互译文件
path_to_file = 'cmn.txt'
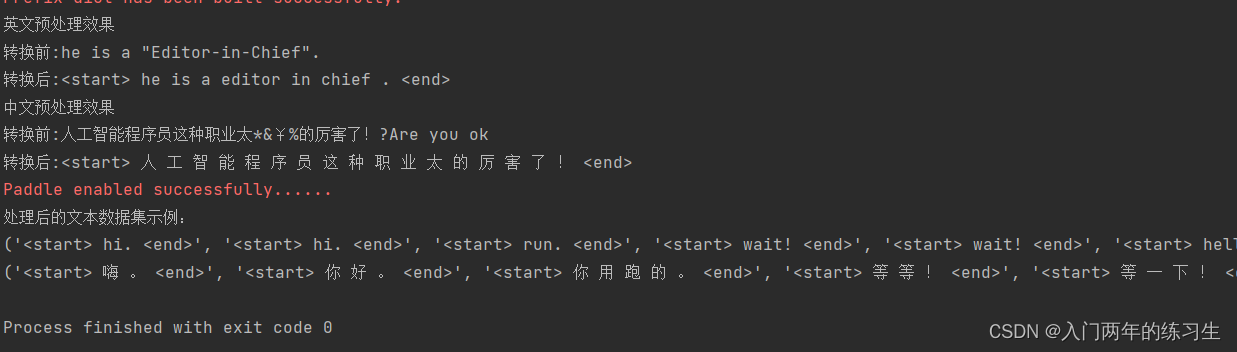
print('英文预处理效果')
print('转换前:'+'he is a "Editor-in-Chief".')
print('转换后:'+ preprocess_sentence('he is a "Editor-in-Chief".'))
print('中文预处理效果')
print('转换前:'+'人工智能程序员这种职业太*&¥%的厉害了!?Are you ok')
print('转换后:'+ preprocess_sentence('人工智能程序员这种职业太*&¥%的厉害了!?Are you ok'))
en,chs = create_dataset(path_to_file, num_examples)
print('处理后的文本数据集示例:')
print(en)
print(chs)
# # 为了快速演示,先处理num_examples条数据集
# input_tensor, target_tensor, inp_lang, targ_lang = load_dataset(path_to_file, num_examples)
# # 计算目标张量的最大长度 (max_length)
# max_length_targ, max_length_inp = max_length(target_tensor), max_length(input_tensor)
# # 采用 80 - 20 的比例切分训练集和验证集
# input_tensor_train, input_tensor_val, target_tensor_train, target_tensor_val = train_test_split(input_tensor, target_tensor, test_size=0.2)
# # 显示长度
# print(len(input_tensor_train), len(target_tensor_train), len(input_tensor_val), len(target_tensor_val))
# print('经过编码后的源语言(中文)张量数据集示例:')
# print(input_tensor)
# print('源语言(中文)字典内的单词编码:')
# print(inp_lang.word_index)
# print('格式化显示一条源语言(中文)字典内的单词编码:')
# convert(inp_lang, input_tensor_train[20])
# print('经过编码后的目标语言(英文)张量数据集示例:')
# print(target_tensor)
# print('目标语言(英文)字典内的单词编码:')
# print(targ_lang.word_index)
# print('格式化显示一条目标语言(英文)字典内的单词编码:')
# convert(targ_lang, target_tensor_train[20])
# #创建一个tf.data数据集
# BUFFER_SIZE = len(input_tensor_train)
# BATCH_SIZE = 64
# dataset = tf.data.Dataset.from_tensor_slices((input_tensor_train, target_tensor_train)).shuffle(BUFFER_SIZE)
# dataset = dataset.batch(BATCH_SIZE, drop_remainder=True)
# example_input_batch, example_target_batch = next(iter(dataset))
# print('数据集尺寸:')
# print(example_input_batch.shape, example_target_batch.shape)
这里注释了部分代码的输出,主要展示翻译部分,如果自行需要可以在文章尾部复制全文自行测试
部分运行结果:我们可以观察到对应的中英文翻译
在这里附上实战整体代码,可直接下载相关库后运行。
# 创建清理过的输入输出对
import tensorflow as tf
from sklearn.model_selection import train_test_split
import re
import io
import jieba
jieba.initialize() # 手动初始化jieba资源,提高分词效率。
jieba.enable_paddle() # 启动paddle模式。 0.40版之后开始支持,早期版本不支持
#判断是否包含中文
def is_chinese(string):
"""
检查整个字符串是否包含中文
:param string: 需要检查的字符串
:return: bool
"""
for ch in string:
if u'\u4e00' <= ch <= u'\u9fa5':
return True
return False
#中英文预处理
def preprocess_sentence(w):
if is_chinese(w):
w = re.sub(r"[^\u4e00-\u9fa5,。?!]+", "", w)
w = w.strip()
#seg_list = jieba.cut(w,use_paddle=True) # 使用paddle模式分词
#w= ' '.join(list(seg_list))
w=分字(w)
# 给句子加上开始和结束标记
# 以便模型知道每个句子开始和结束的位置
w = '<start> ' + w + ' <end>'
else:
w = w.lower()
# 除了 (a-z, A-Z, ".", "?", "!", ","),将所有字符替换为空格
w = re.sub(r"[^a-zA-Z?.!,]+", " ", w)
w = w.rstrip().strip()
# 给句子加上开始和结束标记
# 以便模型知道每个句子开始和结束的位置
w = '<start> ' + w + ' <end>'
return w
def 分字(str):
line = str.strip()
pattern = re.compile('[^\u4e00-\u9fa5,。?!]')
zh = ''.join(pattern.split(line)).strip()
result=''
for character in zh:
result+=character+' '
return result.strip()
# 调用预处理方法,并返回这样格式的句子对:[chinese, english]
def create_dataset(path, num_examples):
lines = io.open(path, encoding='UTF-8').read().strip().split('\n')
word_pairs = [[preprocess_sentence(w) for w in l.split('\t')[0:2]] for l in lines[:num_examples]]
return zip(*word_pairs)
#判断词序列长度
def max_length(tensor):
return max(len(t) for t in tensor)
#词符化
def tokenize(lang):
lang_tokenizer = tf.keras.preprocessing.text.Tokenizer(filters='')
lang_tokenizer.fit_on_texts(lang)
tensor = lang_tokenizer.texts_to_sequences(lang)
tensor = tf.keras.preprocessing.sequence.pad_sequences(tensor,padding='post')
return tensor, lang_tokenizer
# 创建清理过的输入输出对
def load_dataset(path, num_examples=None):
targ_lang, inp_lang = create_dataset(path, num_examples)
input_tensor, inp_lang_tokenizer = tokenize(inp_lang)
target_tensor, targ_lang_tokenizer = tokenize(targ_lang)
return input_tensor, target_tensor, inp_lang_tokenizer, targ_lang_tokenizer
#格式化显示字典内容
def convert(lang, tensor):
for t in tensor:
if t!=0:
print("%d ----> %s" % (t, lang.index_word[t]))
if __name__=="__main__":
num_examples = 100
#读取中英互译文件
path_to_file = 'cmn.txt'
print('英文预处理效果')
print('转换前:'+'he is a "Editor-in-Chief".')
print('转换后:'+ preprocess_sentence('he is a "Editor-in-Chief".'))
print('中文预处理效果')
print('转换前:'+'人工智能程序员这种职业太*&¥%的厉害了!?Are you ok')
print('转换后:'+ preprocess_sentence('人工智能程序员这种职业太*&¥%的厉害了!?Are you ok'))
en,chs = create_dataset(path_to_file, num_examples)
print('处理后的文本数据集示例:')
print(en)
print(chs)
# # 为了快速演示,先处理num_examples条数据集
# input_tensor, target_tensor, inp_lang, targ_lang = load_dataset(path_to_file, num_examples)
# # 计算目标张量的最大长度 (max_length)
# max_length_targ, max_length_inp = max_length(target_tensor), max_length(input_tensor)
# # 采用 80 - 20 的比例切分训练集和验证集
# input_tensor_train, input_tensor_val, target_tensor_train, target_tensor_val = train_test_split(input_tensor, target_tensor, test_size=0.2)
# # 显示长度
# print(len(input_tensor_train), len(target_tensor_train), len(input_tensor_val), len(target_tensor_val))
# print('经过编码后的源语言(中文)张量数据集示例:')
# print(input_tensor)
# print('源语言(中文)字典内的单词编码:')
# print(inp_lang.word_index)
# print('格式化显示一条源语言(中文)字典内的单词编码:')
# convert(inp_lang, input_tensor_train[20])
# print('经过编码后的目标语言(英文)张量数据集示例:')
# print(target_tensor)
# print('目标语言(英文)字典内的单词编码:')
# print(targ_lang.word_index)
# print('格式化显示一条目标语言(英文)字典内的单词编码:')
# convert(targ_lang, target_tensor_train[20])
# #创建一个tf.data数据集
# BUFFER_SIZE = len(input_tensor_train)
# BATCH_SIZE = 64
# dataset = tf.data.Dataset.from_tensor_slices((input_tensor_train, target_tensor_train)).shuffle(BUFFER_SIZE)
# dataset = dataset.batch(BATCH_SIZE, drop_remainder=True)
# example_input_batch, example_target_batch = next(iter(dataset))
# print('数据集尺寸:')
# print(example_input_batch.shape, example_target_batch.shape)
本部分实战为深度学习的预处理部分,下一文我们将进行深度学习实现机器翻译中英互译
机器翻译:引入注意力机制的Encoder-Decoder深度神经网络训练实战中英文互译(完结篇)