一、Kettle
Kettle 中文名称叫水壶,该项目的概念是把各种数据放到一个壶里,然后以一种指定的格式流出。Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,无需安装,数据抽取]高效稳定。
Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么。Kettle中有两种格式文件,Transformation和Job,Transformation完成针对数据的基础转换,Job则完成整个工作流的控制。
1.1 产品结构
- Spoon 一个基于swt开发的[流式处理客户端,用户开发转换、任务、创建数据库、集群、分区等
- Pan 独立的命令行程序,支持通过命令行实现界面的功能,如果转换启停,任务启停,状态查看等
- Kitchen 一个独立的命令行程序,用于执行由Spoon编辑的作业.
- Carte 一个轻量级的Web容器,用于建立专用、远程的ETL Server。
Kettle的体系架构
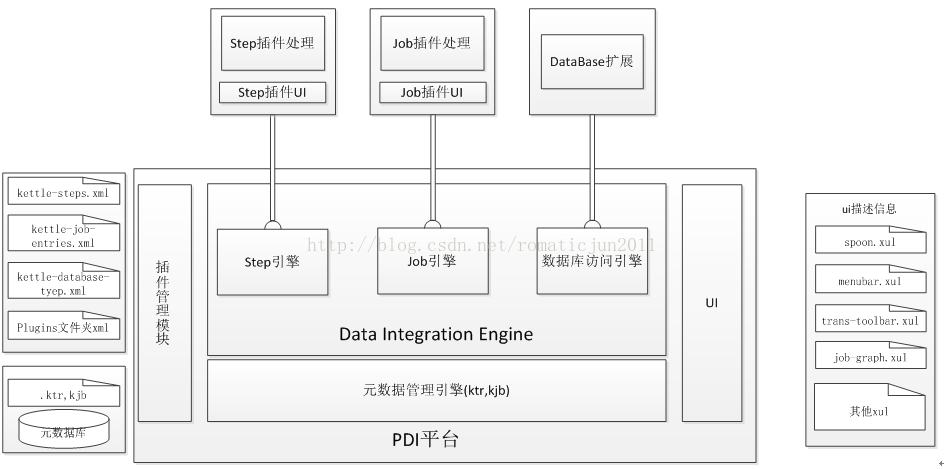
1.2 优点
- 插件架构扩展性好
Kettle作为开源工具,无论是扩展还是系统集成的功能,本质上来讲都是插件,管理方式和运行机制是一致的,系统集成的功能点也均实现