记录第一次接触R语言
《深入浅出数据分析》第九章讲到R语言,在这记录一下,就当给自己做的笔记。
一、R语言下载安装
安装地址:https://www.r-project.org/
安装上没有什么问题,就根据自己电脑,按着顺序来就行了。
二、运行
第一次打开里面长这样:

书中第九章是要用R绘制直方图。
所以先加载数据 。
书中的数据地址已经变了,这里是新链接:https://resources.oreilly.com/examples/9780596153946
之后正式开始加载数据:
employees<-read.table("路径", sep=",", header=1) // 加载文件
employees$received // 查看该文件的received列
hist(employees$received, breaks=50) // 绘制直方图
// breaks告诉R如何分组,它的数值代表小矩形的数量
break<-sep(0, 100, 2) // 表示范围为0~100,每个小矩形宽度为2,此时break的值为50

最后图片长这样。
执行语句:
sd(employees$received) // 求指定数据范围的标准偏差
summary(employees$received) // 汇总
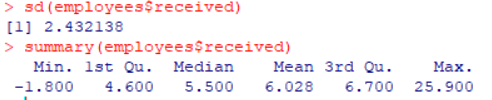
注意:图片里面的1st Qu.和3rd Qu.分别代表第一分位数(下四分位数)和第三分位数(上四分位数)。
执行语句:
employees$received[employees$year == 2007] // 在已提取出的employees$received中筛选year为2007的数据
employees$received[employees$gender == "F"] // 在已提取出的employees$received中筛选性别为F的数据
三、补充
1.加载csv文件
引用大佬博客,先放在这方便以后寻找。感谢互联网。
https://blog.csdn.net/zw0Pi8G5C1x/article/details/108191230
2.hist函数
上面有用到breaks参数。
这里补充几个:
-
freq
逻辑值,默认值为TRUE , y轴显示的是每个区间内的频数,FALSE, 代表显示的是频率(= 频数/ 总数)
-
main
main=“标题”,居中显示。
-
probably
probability : 逻辑值,和 freq 参数的作用正好相反,TRUE 代表频率, FALSE 代表频数
-
labels
显示在每个柱子上方的标签。
-
col
柱子的填充色
-
border
柱子的边框的颜色,默认为black, 当border = NA 时, 代表没有边框