说明:我是在keras的官方demo上进行修改https://github.com/fchollet/keras/blob/master/examples/imdb_cnn.py
1、几点说明,从文件中读入数据,会降低GPU的使用率,如果能够直接将数据载入内存,GPU的使用率会比较高。下面进行对比:
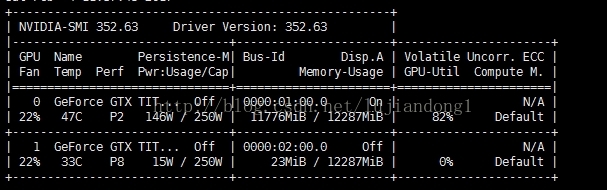
全部数据载入内存,GPU的使用率:
使用队列,边读数据边进行训练:
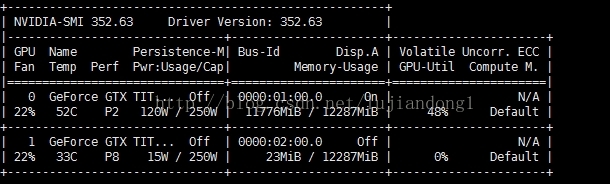
结论:全部载入内存,GPU的使用率可以达到82%,如果边载入数据边训练,只能达到48%
2、keras 使用迭代器来实现大数据的训练,其简单的思想就是,使用迭代器从文件中去顺序读取数据。所以,自己的训练数据一定要先随机打散。因为,我们的迭代器也是每次顺序读取一个batch_size的数据进行训练。
举例如下:数据如下,前400维是特征,后一维是label

keras 官方的demo 如下:
def generate_arrays_from_file(path):
while 1:
f = open(path)
for line in f:
# create Numpy arrays of input data
# and labels, from each line in the file
x, y = process_line(line)
yield (x, y)
f.close()
model.fit_generator(generate_arrays_from_file('/my_file.txt'),
samples_per_epoch=10000, nb_epoch=10)
说明:官方的demo还是有瑕疵的,没有实现batch_size,该demo每次只能提取一个样本。我针对上述的数据集,实现的batch_size数据提取的迭代器,代码如下:
def process_line(line):
tmp = [int(val) for val in line.strip().split(',')]
x = np.array(tmp[:-1])
y = np.array(tmp[-1:])
return x,y
def generate_arrays_from_file(path,batch_size):
while 1:
f = open(path)
cnt = 0
X =[]
Y =[]
for line in f:
# create Numpy arrays of input data
# and labels, from each line in the file
x, y = process_line(line)
X.append(x)
Y.append(y)
cnt += 1
if cnt==batch_size:
cnt = 0
yield (np.array(X), np.array(Y))
X = []
Y = []
f.close()
训练时候的代码如下:
model.fit_generator(generate_arrays_from_file('./train',batch_size=batch_size),
samples_per_epoch=25024,nb_epoch=nb_epoch,validation_data=(X_test, y_test),max_q_size=1000,verbose=1,nb_worker=1)
3、关于samples_per_epoch的说明:
我的训练数据,train只有25000行,batch_size=32。照理说samples_per_epoch=32,但是会有警告.UserWarning: Epoch comprised more than `samples_per_epoch` samples, which might affect learning results

说明:这个出错的原因是train的数目/batch_size不是整数。可以将samples_per_epoch = ceil(train_num/batch_size) *batch_size.设置完的结果为88.72%:

keras的demo使用的方法是将全部数据载入进来训练:

demo的结果为88.86%,所以,该数据读取的方式基本没问题。但是,一定要将数据先进行打乱。如果能全部载入内存,就全部载入内存,速度会快不少