任务描述
本关任务:编写代码实现快速排序。
相关知识
为了完成本关任务,你需要掌握: 1.如何实现快速排序; 2.快速排序的算法分析。
快速排序
快速排序使用了和归并排序一样的分而治之策略,它的思路是依据一个“基准值”数据项来把列表分为两部分:小于基准值的一部分和大于基准值的一部分,然后每部分再分别进行快速排序,这是一个递归的过程。基准值的作用在于协助拆分列表,一般选择列表的第 1 项作为基准值。基准值在最后排序好的列表里的实际位置,我们通常称之为分割点,是用来对拆分成的两部分分别进行快速排序的关键位置点。
快速排序算法通过多次比较和交换来实现排序,其排序流程如下:
-
找到基准值的位置,设置左标记 leftmark 和右标记 rightmark。
-
不断地移动左右标记,进行多次比较和交换: ① 左标一直向右移动,遇到比基准值大的就停止; ② 右标一直向左移动,遇到比基准值小的就停止; ③ 把左右标记所指的数据项交换。
-
继续移动,直到左标记移到右标记的右侧,停止移动。这时右标记所指的位置就是基准值应处的位置,将基准值和这个位置的数据项交换。此时,基准值左边部分的数据项都小于或等于基准值,右边部分的数据项都大于或等于基准值。
-
然后递归地对左边和右边的部分进行快速排序,当待排序部分只有一个数据项时,递归过程结束。
以下为快速排序的一个简单示例。首先将图 1 中列表的第 1 个数据项 54 作为基准值,然后设置两个位置标记 leftmark 和 rightmark,左标记 leftmark 指向列表的第一项 26,右标记 rightmark 指向列表的最后一项 20。

图1 快速排序初始状态
接下来需要不断地把左标记向右移动,直到它指向了一个比基准值更大的数据项。同时不断地把右标记向左移动,直到它指向了一个比基准值更小的数据项。最后交换左、右标记位置的数据项。
首先看左标记,左标记当前所指的 26 小于基准值 54,则继续右移。右移一个位置后指向的 93 大于基准值 54,则停止移动。当前列表状态如图 2 所示。

图2 左标记指向的 93 大于基准值 54
接下来看右标记,右标记当前所指的 20 小于基准值 54,则停止移动。当前列表状态如图 3 所示。

图3 右标记指向的 20 小于基准值 54
相对于最终的分割点,当前左、右标记所指的两个数据项正位于错误的位置,因此需要对其进行交换。在此示例中,需要将 93 和 20 进行交换,交换后的列表状态如图 4 所示。
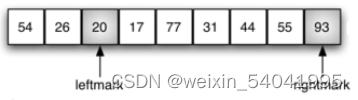
图4 将 93 和 20 进行交换
重复执行以上步骤:
-
左标记当前所指的 20 小于基准值 54,则继续右移;右移一个位置后指向的 17 小于基准值 54,则继续右移;右移一个位置后指向的 77 大于基准值 54,则停止移动。
-
右标记当前所指的 93 大于基准值 54,则继续左移;左移一个位置后指向的 55 大于基准值 54,则继续左移;左移一个位置后指向的 44 小于基准值 54,则停止移动。
-
当前左、右标记的位置如图 5 所示,将所指向的 77 和 44 进行交换。

图5 左、右标记分别指向 77 和 44
接下来继续移动左右标记:
如图 6 所示,此时右标记移动到了左标记的前方,则右标记所在的位置就是分割点的位置。

图6 右标记小于左标记
将基准值 54 与分割点位置的数据项 31 交换后,第 1 趟排序结束,当前列表状态如图 7 所示。可以看到,列表被分成两部分,左部分的所有数据项都比基准值 54 小,右部分的所有数据项都比基准值 54 大。接下来递归地对这两部分再执行快速排序过程,直到列表中只剩一个数据项。

图7 第 1 趟排序结果
快速排序的递归算法的“递归三要素”可总结如下:
-
基本结束条件:列表中仅有 1 个数据项时,自然是排好序的;
-
缩小规模:根据基准值将列表分为两部分,最好的情况是分为相等规模的两半;
-
调用自身:将拆分成的两部分分别调用自身进行排序。
快速排序的算法分析
我们可以将快速排序分为两个过程来分析:
综合考虑,时间复杂度为O(nlogn)。但是,如果基准值所在的分割点过于偏离中部,造成左右两部分数量不平衡,则会使算法效率降低。最坏的情况是,拆分成的某一部分始终没有数据,这时时间复杂度就退化到O(n2)。
编程要求
在右侧编辑器中的 Begin-End 区间补充代码,根据快速排序的算法思想完成quickSortHelper和partition方法,从而实现对无序表的排序。其中quickSortHelper方法用于对从 first 到 last 位置的数据项所在的列表进行快速排序;partition方法用于对列表进行拆分,同时返回分割点位置。
测试说明
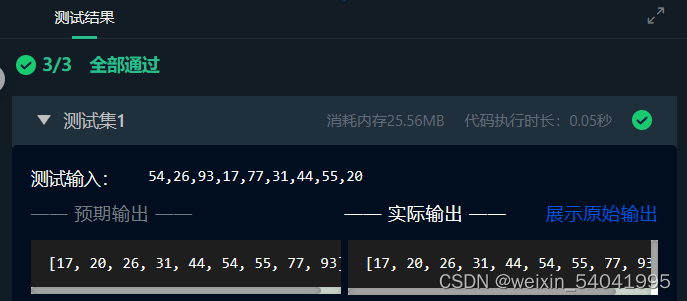
平台会对你编写的代码进行测试,比对你输出的数值与实际正确的数值,只有所有数据全部计算正确才能通过测试:
测试输入:
54,26,93,17,77,31,44,55,20
输入说明:输入为需要对其进行排序的无序表。
预期输出:
[17, 20, 26, 31, 44, 54, 55, 77, 93]
输出说明:输出的是对无序表进行快速排序后的结果,以列表的形式展现
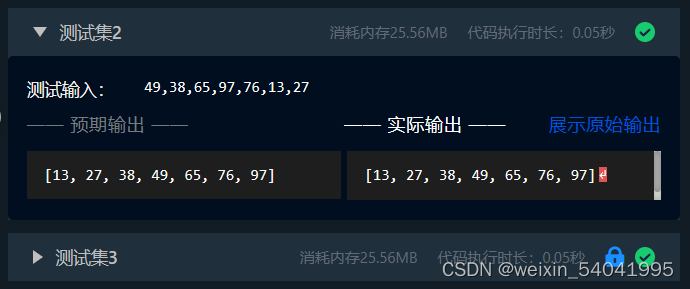
测试输入:
49,38,65,97,76,13,27
预期输出:
[13, 27, 38, 49, 65, 76, 97]
开始你的任务吧,祝你成功!
'''请在Begin-End之间补充代码, 完成quickSortHelper和partition函数'''
# 快速排序
def quickSort(alist):
quickSortHelper(alist,0,len(alist)-1)
# 指定当前排序列表开始(first)和结束(last)位置的快速排序
def quickSortHelper(alist,first,last):
if first<last: # 当列表至少包含两个数据项时,做以下操作
# 调用partition函数对当前排序列表进行拆分,返回分割点splitpoint
splitpoint = partition(alist,first,last)
# 递归调用quickSortHelper函数对拆分得到的左部分和右部分进行快速排序
# ********** Begin ********** #
quickSortHelper(alist,first,splitpoint-1)
quickSortHelper(alist,splitpoint+1,last)
# ********** End ********** #
# 拆分列表
def partition(alist,first,last):
pivotvalue = alist[first] # 选定基准值为列表的第一个数据项
leftmark = first+1 # 左标
rightmark = last # 右标
done = False
while not done:
# 将左标向右移动,直至遇到一个大于基准值的数据项
while leftmark <= rightmark and alist[leftmark] <= pivotvalue:
leftmark = leftmark + 1
# 将右标向左移动,直至遇到一个小于基准值的数据项
# ********** Begin ********** #
while alist[rightmark]>=pivotvalue and rightmark>=leftmark:
rightmark=rightmark-1
# ********** End ********** #
# 右标小于左标时,结束移动
if rightmark < leftmark:
done = True
# 否则将左、右标所指位置的数据项交换
else:
# ********** Begin ********** #
temp=alist[leftmark]
alist[leftmark]=alist[rightmark]
alist[rightmark]=temp
# ********** End ********** #
# 将基准值就位
temp = alist[first]
alist[first] = alist[rightmark]
alist[rightmark] = temp
return rightmark # 返回基准值位置,即分割点