迁移学习(Transfer Learning)的概念早在20世纪80年代就有相关的研究,这期间的研究有的称为归纳研究(inductive transfer)、知识迁移(knowledge transfer)、终身学习(life-long learning)以及累积学习(incremental learning)等。直到2009年,香港科技大学杨强教授对迁移学习的研究进行了总结和归纳,迁移学习才开始有了较为完善的框架和基本概念。迁移学习的研究范围和研究领域非常广泛。
推荐学习迁移学习一个非常好的资源:https://github.com/jindongwang/transferlearning
迁移学习是指将原来用于解决任务A的网络结构和权值迁移到任务B中,并且在任务B中也能得到较好的结果的一种训练方法。迁移学习之所以能够实现的原理是由于卷积神经网络在浅层学习的特征具有通用性。在样本不足的情况下,可以使用迁移学习,将这些通用特征学习从其他已经训练好的网络中迁移过来,从而节省训练时间,并且得到较好的识别结果。
在迁移学习中,有两个基本的概念:领域(Domain)和任务(Task)。
(1).领域:是进行学习的主体。领域主要由两部分构成:数据和生成这些数据的概率分布。特别地,因为涉及到迁移,所以对应于两个基本的领域:源领域(Source Domain)和目标领域(Target Domain)。这两个概念很好理解。源领域就是有知识、有大量数据标注的领域,是我们要迁移的对象;目标领域就是我们最终要赋予知识、赋予标注的对象。知识从源领域传递到目标领域,就完成了迁移。
(2).任务:是学习的目标。任务主要由两部分组成:标签和标签对应的函数。
迁移学习:给定一个有标记的源域和一个无标记的目标域。这两个领域的数据分布不同。迁移学习的目的就是要借助源域的知识,来学习目标域的知识(标签)。或是指基于源域数据和目标域数据、源任务和目标任务之间的相似性,利用在源领域中学习到的知识,去解决目标领域任务的一种机器学习方法。
迁移学习并没有一个统一的分类方法。下图给出了迁移学习的常用分类方法:
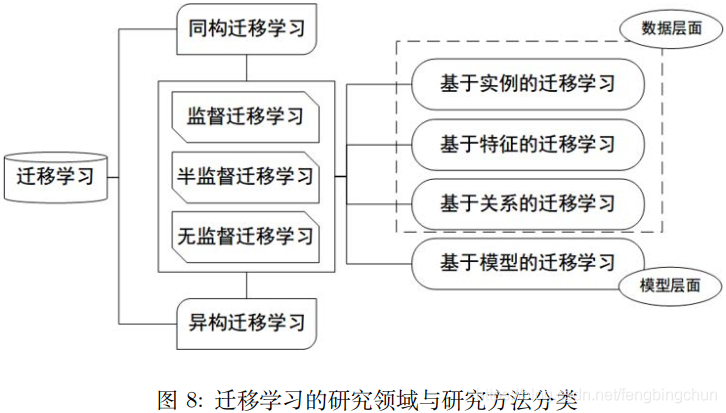
迁移学习按学习方法分类,可以分为四个大类:基于样本的迁移学习方法、基于特征的迁移学习方法、基于模型的迁移学习方法、基于关系的迁移学习方法。
(1). 基于样本的迁移:简单来说就是通过权重重用,对源域和目标域的样例进行迁移。是按照源域的样本与目标域样本的相似性,对于相似度高的源域样本赋予较高的权重,并迁移增广到目标域的训练样本集中用于目标模型的训练,样本的迁移方法主要应用于分类问题。
(2).基于特征的迁移:就是更进一步对特征进行变换。意思是说,假设源域和目标域的特征原来不在一个空间,或者说它们在原来那个空间上不相似,那我们就想办法把它们变换到一个空间里面,那这些特征不就相似了?
近年来,基于特征的迁移学习方法大多与神经网络进行结合,在神经网络的训练中进行学习特征和模型的迁移。
(3).基于模型的迁移:就是说构建参数共享的模型。这个主要就是在神经网络里面用的特别多,因为神经网络的结构可以直接进行迁移。比如说神经网络最经典的finetune就是模型参数迁移的很好的体现。
Finetune,也叫微调、finetuning,是深度学习中的一个重要概念。简而言之,finetune就是利用别人已经训练好的网络,针对自己的任务再进行调整。
A.为什么需要已经训练好的网络?在实际的应用中,我们通常不会针对一个新任务,就去从头开始训练一个神经网络。这样的操作显然是非常耗时的。尤其是,我们的训练数据不可能像ImageNet那么大,可以训练出泛化能力足够强的深度神经网络。即使有如此之多的训练数据,我们从头开始训练,其代价也是不可承受的。那么怎么办呢?迁移学习告诉我们,利用之前已经训练好的模型,将它很好地迁移到自己的任务上即可。
B.为什么需要finetune?因为别人训练好的模型,可能并不是完全适用于我们自己的任务。可能别人的训练数据和我们的数据之间不服从同一个分布;可能别人的网络能做比我们的任务更多的事情;可能别人的网络比较复杂,我们的任务比较简单。举一个例子来说,假如我们想训练一个猫狗图像二分类的神经网络,那么很有参考价值的就是在CIFAR-100上训练好的神经网络。但是CIFAR-100有100个类别,我们只需要2个类别。此时,就需要针对我们自己的任务,固定原始网络的相关层,修改网络的输出层,以使结果更符合我们的需要。
C. Finetune的优势:不需要针对新任务从头开始训练网络,节省了时间成本;预训练好的模型通常都是在大数据集上进行的,无形中扩充了我们的训练数据,使得模型更鲁棒、泛化能力更好;Finetune实现简单,使得我们只关注自己的任务即可。在实际应用中,通常几乎没有人会针对自己的新任务从头开始训练一个神经网络。Finetune是一个理想的选择。
深度网络的finetune可以帮助我们节省训练时间,提高学习精度。但是finetune有它的先天不足:它无法处理训练数据和测试数据分布不同的情况。而这一现象在实际应用中比比皆是。因为finetune的基本假设也是训练数据和测试数据服从相同的数据分布。这在迁移学习中也是不成立的。因此,我们需要更进一步,针对深度网络开发出更好的方法使之更好地完成迁移学习任务。以数据分布自适应方法为参考,许多深度学习方法都开发出了自适应层(Adaptation Layer)来完成源域和目标域数据的自适应。自适应能够使得源域和目标域的数据分布更加接近,从而使得网络的效果更好。从上述的分析我们可以得出,深度网络的自适应主要完成两部分的工作:一是哪些层可以自适应,这决定了网络的学习程度;二是采用什么样的自适应方法(度量准则),这决定了网络的泛化能力。
设计深度迁移网络的基本准则:决定自适应层,然后在这些层加入自适应度量,最后对网络进行finetune。
生成对抗网络GAN(Generative Adversarial Nets)受到自博弈论中的二人零和博弈(two-player game)思想的启发而提出。它一共包括两个部分:一部分为生成网络(Generative Network),此部分负责生成尽可能地以假乱真的样本,这部分被成为生成器(Generator);另一部分为判别网络(Discriminative Network),此部分负责判断样本是真实的,还是由生成器生成的,这部分被成为判别器(Discriminator)。生成器和判别器的互相博弈,就完成了对抗训练。
GAN的目标很明确:生成训练样本。这似乎与迁移学习的大目标有些许出入。然而,由于在迁移学习中,天然地存在一个源领域,一个目标领域,因此,我们可以免去生成样本的过程,而直接将其中一个领域的数据(通常是目标域)当作是生成的样本。此时,生成器的职能发生变化,不再生成新样本,而是扮演了特征提取的功能:不断学习领域数据的特征,使得判别器无法对两个领域进行分辨。这样,原来的生成器也可以称为特征提取器(Feature Extractor)。
(4).基于关系的迁移:这个方法用的比较少,这个主要就是说挖掘和利用关系进行类比迁移。比如老师上课、学生听课就可以类比为公司开会的场景。这个就是一种关系的迁移。这种方法比较关注源域和目标域的样本之间的关系。
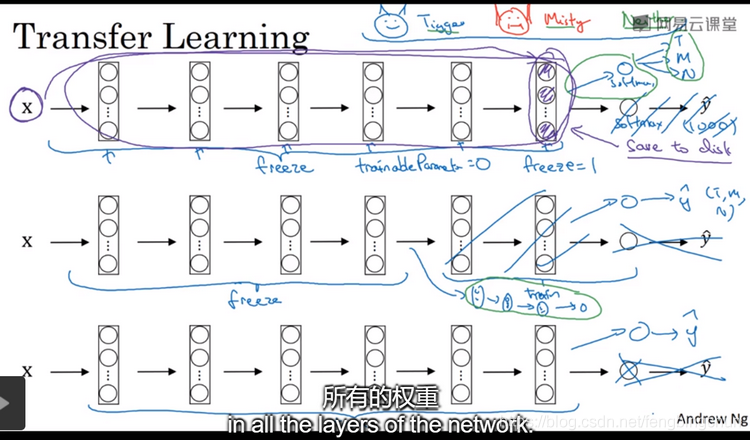
如果你要做一个计算机视觉的应用,相比于从头训练权重,或者说从随机初始化权重开始,不如你下载别人已训练好的网络结构的权重,你通常能够进展的相当快。用这个作为预训练,然后转换到你感兴趣的任务上。计算机视觉的研究社区,非常喜欢把许多数据集上传到网上,比如ImageNet、MS COCO或者Pascal类型的数据集。你可以下载花费了别人几周甚至几个月而做出来的开源的权重参数,把它当作一个很好的初始化用在自己的神经网络上。用迁移学习把公共的数据集的知识迁移到你自己的问题上。如下图,假如说你要建立一个猫的检测器用来检测你自己的宠物猫,Tigger、Misty或者Neither,忽略两只猫同时出现在一种图的情况。你现在可能没有Tigger和Misty的大量图像,所以你的训练集会很小。此时可以从网上下载一些神经网络的开源实现,不仅把代码下载下来也要把权重(weights)下载下来。有许多训练好的网络你都可以下载,例如ImageNet,它有1000个不同的类别,因此这个网络会有一个Softmax单元,它可以输出1000个可能类别之一。你可以去掉这个Softmax层,创建你自己的Softmax单元用来输出Tigger、Misty、Neither三个类别。就网络而言,建议你把所有的层都看作是冻结的(frozen)。你冻结的网络中包含所有层的参数,你只需要训练和你的Softmax层有关的参数。这个Softmax层有三个可能的输出。通过使用其他人预训练的权重,你很可能得到很好的性能,即使只有一个小的数据集。幸运的是,大多数深度学习框架都支持这种操作,事实上,取决于用的框架。如果你的数据越多,你可以冻结越少的层,训练越多的层。这个理念就是,如果你有一个更大的训练集,也许有足够多的数据,那么不要单单训练一个Softmax单元,而是考虑训练中等大小的网络,包含你最终要用的网络的后面几层。最后,如果你有大量数据,你应该做的就是用开源的网络和它的权重把整个当作初始化然后训练整个网络。
迁移学习的应用:计算机视觉、图像分类、文本分类、行为识别、自然语言处理、视频监控、舆情分析、人机交互等。
注:以上所有的内容的整理均来自网络,主要参考:http://jd92.wang/assets/files/transfer_learning_tutorial_wjd.pdf
GitHub:https://github.com/fengbingchun/NN_Test