内核代码版本:2.6.11.1
1、进程
进程是任何多道程序设计的操作系统中的基本概念。通常把进程定义为程序执行的一个实例。
在Linux源代码中,进程通常称为任务(task)或线程(thread)。Linux系统的线程实现非常特别:他对线程和进程并不特别区分。对于Linux而言,线程只不过是特殊的进程罢了。
当一个进程创建的时候,它几乎与父进程相同,它接受父进程地址空间的一个(逻辑)拷贝,并从进程创建系统调用的下一条指令开始执行与父进程相同的代码。尽管父子进程可以共享含有程序代码的页,但是它们有独立的数据拷贝(堆和栈),因此子进程对一个内存单元的修改对父进程是不可见得(反之亦然)。
2、进程描述符
为了管理进程,内核必须对每个进程所做的事情进行清楚的描述。此结构称之为进程描述符。在Linux系统中使用task_struct结构体表示。此结构定义在<linux/sched.h>中。
内核把进程的列表存放在任务队列(task list)的双向循环链表中。task_struct相对较大,在32位的机器上大约有1.7KB。
2.1、分配进程描述符
Linux通过slab分配器分配task_struct结构,这样能达到对象复用和缓存着色的目的。(预分配和重复使用task_struct可避免动态分配和释放所带来的的资源消耗)
在2.6以后的版本中使用slab分配器动态生成task_struct,所以只需要在栈底(对于向下增长的栈)或栈顶(向上增长的栈)创建一个新的结构struct thread_info。thread_info结构就保存了进程的基本信息,并有一个指针指向task_struct。
在X86上,struct thread_info在文件<include\asm-x86_64\thread_info.h>中定义如下:
struct thread_info {
struct task_struct *task; /* main task structure */
struct exec_domain *exec_domain; /* execution domain */
__u32 flags; /* low level flags */
__u32 status; /* thread synchronous flags */
__u32 cpu; /* current CPU */
int preempt_count;
mm_segment_t addr_limit;
struct restart_block restart_block;
};
下图中显示了在物理内存中存放两种数据结构的方式。线程描述符驻留与这个内存区的开始,而栈顶末端向下增长。
内核进程堆栈:
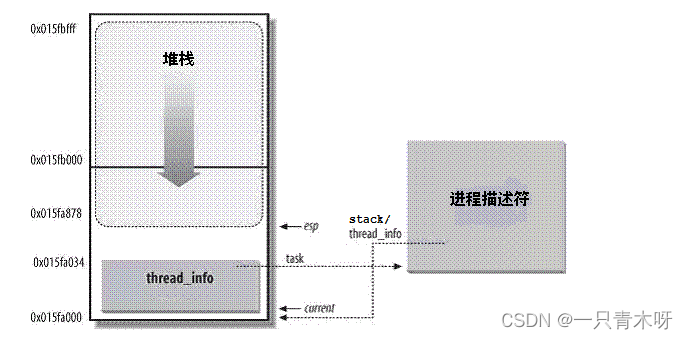
内核态的进程堆栈大小通常为8192个字节(两个页框),考虑到效率的因素,内核让这8K空间占据连续的两个页框并让第一个页框的起始地址是2^13的倍数。
C语言使用联合体表示一个进程的线程描述符和内核栈:
union thread_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};
2.2、标识一个进程
内核通过一个唯一的进程标识值(process identification value)或PID来标识每一个进程,PID存放在进程描述符中的pid字段中。PID被顺序的编号,新创建的进程PID通常是前一个进程的PID加1。不过PID有一个上限,当内核使用的PID达到这个上限的时候就必须开始循环使用的已闲置的小PID号,在Linux中前1000个PID号是给系统用的,我们最好不要去用这些。在缺省的情况下,最大的PID号是32767。64位系统中,系统管理员可把PID的上限扩大到4194303。
路径:include\linux\threads.h
/*
* This controls the default maximum pid allocated to a process
*/
#define PID_MAX_DEFAULT 0x8000 /*32758*/
/*
* A maximum of 4 million PIDs should be enough for a while:
*/
#define PID_MAX_LIMIT (sizeof(long) > 4 ? 4*1024*1024 : PID_MAX_DEFAULT) /*4194304*/
由于循环的使用PID编号,内核必须通过管理一个pidmap_array位图来表示当前已分配的PID号和闲置的PID号。因为一个页框包含32768个位,所以在32位体系结构中pidmap_array位图存放在一个单独的页中。然而64为系统体系结构中,当内核分配超过当前位图大小的PID号时,需要为PID位图增加更多的页。系统会一只保存这些页不被释放。
当然对于一般的桌面系统来说系统默认的PID号上限值是够用的,但在一些服务器中可能需要更多的进程,由于确实需要的话,可以通过修改/proc/sys/kernel/pid_max来提高 PID上限。
2.3、标识当前进程
从效率的观点来看,thread_info结构与内核态堆栈之间的紧密结合提供的主要好处是:内核很容易从esp寄存器的值获得当前在CPU上正在运行的进程的thread_info结构的地址。
事实上,如果thread_union结构长度是8K,则屏蔽掉esp的低13位有效位就可获得thread_info结构的基地址,如果thread_union结构长度是4K,内核需要屏蔽掉esp的低12位有效位就可获得thread_info结构的基地址。这项工作由current_thread_info()来完成(不同架构中有所差异),下面看下arm的current宏:
#define THREAD_SIZE 8192
#define current (get_current())
static inline struct task_struct *get_current(void)
{
return current_thread_info()->task;
}
static inline struct thread_info *current_thread_info(void)
{
register unsigned long sp asm ("sp");
return (struct thread_info *)(sp & ~(THREAD_SIZE - 1));
}
进程最常用的就是进程描述符,而不是thread_info结构。为了获得当前在CPU上运行的进程描述符指针,我们从上面的代码可以看到,内核使用current宏,他的本质是current_thread_info()->task,可以看到在current_thread_info()函数中使用sp指针并屏蔽掉低13位,获取到thread_info的地址,然后通过current_thread_info()->task来获取进程描述符。
这里不同架构中会有所差异,比如说PowerPC,他们当前运行的进程的进程描述符是保存在一个寄存器中。只需要从寄存器中取出进程描述符的地址即可。