Github个人博客:https://joeyos.github.io
粒子滤波原理及其matlab仿真
系统建模
粒子滤波算法不受线性高斯模型的约束,与卡尔曼滤波器一样,粒子滤波算法同样需要知道系统的模型,如果不知道系统的模型,也要想办法构建一个模型来逼近真实的模型。这个真实模型就是各应用领域内系统的数学表示,主要包括状态方程和量测方程。
状态方程和过程噪声
X(k) = f (X(k-1), W(k));
观测方程和测量噪声
Z(K) = h (X(k), V(k));
核心思想
粒子滤波是一种基于蒙特卡洛仿真的近似贝叶斯滤波算法。其核心思想是用一些离散随机采样点近似系统随机变量的概率密度函数,以样本均值代替积分运算,从而获得状态的最小方差估计。
均值思想
粒子滤波的均值思想就是利用粒子集合的均值来作为滤波器的估计值。如果粒子集合的分布不能很好的覆盖真实值,那么滤波器经过几次迭代必然会出现滤波发散。
权重计算
权重计算时粒子滤波算法的核心,它的重要意义在于,根据权重大小能实现优质粒子的大量复制,对劣质粒子实现淘汰制。另外,经过权重计算,它也是重新指导粒子空间分布的依据。权重最终影响滤波结果。
优胜劣汰
粒子的“优胜劣汰”主要体现在对粒子的复制上,这种机制从某种意义上说保证了粒子滤波的最终目标得以实现。实现“优胜劣汰”的重要手段是重采样算法。重采样的思想是通过对样本重新采样,大量繁殖权重高的粒子,淘汰权值低的粒子,从而抑制退化。
随机重采样(randomR.m)
多项式重采样(MultinomialR.m)
系统重采样(systematicR.m)
残差重采样(residualR.m)
粒子滤波器(Particle Filter)
蒙特卡洛采样
蒙特卡洛方法是从后验概率分别采集带权重的粒子集(样本集),用粒子集表示后验分布,将积分转化为求和形式。
贝叶斯重要性采样
对蒙特卡洛采样方法,后验概率分布可以用有限的离散样本集来近似。通常后验概率分布函数是无法直接得到的,贝叶斯采样原理的基本思想是,先从一个已知的且容易采样的参考分布中抽样,通过对参考分布的采样获得的粒子集进行加权求和来近似后验分布。
序列重要性采样(SIS滤波器)
贝叶斯重要性采样是一种常用的简单的蒙特卡洛方法,但是没有考虑到递推估计的特点。贝叶斯估计也是一个序列估计问题,因此在采样上也必须有序列关系。序列重要性采样,不改变过去1的序列样本集,而采用递归的形式计算重要性权值。
Bootstrp/采样-重要性再采样(SIR滤波器)
SIR滤波器和SIS滤波器都属于基本粒子滤波器,都使用重要性采样算法,但是两者又有区别。对于SIR滤波器,重采样总是会被执行,在算法中通常两次重要性采样之间需要一次重采样,而SIS滤波器只是在需要是才进行重采样,因此SIS的计算量比SIR的计算量要小。
粒子滤波算法通用流程
- 初始化
- 循环开始
- 重要性采样->计算权重->归一化权重
- 重采样
- 输出
- 循环结束
粒子滤波仿真实例
一维系统建模
状态模型:x(k) = f (x(k-1), k) + w(k-1)
观测方程:z(k) = x(k)^2 / 20 +v(k)
f(x((k-1), k) = 0.5x(k-1) + 2.5x(k-1) / (1+x(k-1)^2) + 8cos(1.2k)
w(k),v(k)为均值为0、方差分别为Q(k)=10,R(k)=1的高斯噪声。状态x(k)与x(k-1)为非线性关系,观测方程中z(k)和x(k)也是非线性关系。
一维系统仿真
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%% 粒子滤波一维系统仿真
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
function Particle_For_UnlineOneDiv
clear all;close all;clc;
randn('seed',1); %为了保证每次运行结果一致,给定随机数的种子点
%初始化相关参数
T=50;%采样点数
dt=1;%采样周期
Q=10;%过程噪声方差
R=1;%测量噪声方差
v=sqrt(R)*randn(T,1);%测量噪声
w=sqrt(Q)*randn(T,1);%过程噪声
numSamples=100;%粒子数
ResampleStrategy=4;%=1为随机采样,=2为系统采样
%%%%%%%%%%%%%%%%%%%%%%%%%%%
x0=0.1;%初始状态
%产生真实状态和观测值
X=zeros(T,1);%真实状态
Z=zeros(T,1);%量测
X(1,1)=x0;%真实状态初始化
Z(1,1)=(X(1,1)^2)./20+v(1,1);%观测值初始化
for k=2:T
%状态方程
X(k,1)=0.5*X(k-1,1)+2.5*X(k-1,1)/(1+X(k-1,1)^2)+8*cos(1.2*k)+w(k-1,1);
%观测方程
Z(k,1)=(X(k,1).^2)./20+v(k,1);
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%
%粒子滤波器初始化,需要设置用于存放滤波估计状态,粒子集合,权重等数组
Xpf=zeros(numSamples,T);%粒子滤波估计状态
Xparticles=zeros(numSamples,T);%粒子集合
Zpre_pf=zeros(numSamples,T);%粒子滤波观测预测值
weight=zeros(numSamples,T);%权重初始化
%给定状态和观测预测的初始采样:
Xpf(:,1)=x0+sqrt(Q)*randn(numSamples,1);
Zpre_pf(:,1)=Xpf(:,1).^2/20;
%更新与预测过程
for k=2:T
%第一步:粒子集合采样过程
for i=1:numSamples
QQ=Q;%跟卡尔曼滤波不同,这里的Q不要求与过程噪声方差一致
net=sqrt(QQ)*randn;%这里的QQ可以看成是网的半径,数值可调
Xparticles(i,k)=0.5.*Xpf(i,k-1)+2.5.*Xpf(i,k-1)./(1+Xpf(i,k-1).^2)+8*cos(1.2*k)+net;
end
%第二步:对粒子集合中的每个粒子,计算其重要性权值
for i=1:numSamples
Zpre_pf(i,k)=Xparticles(i,k)^2/20;
weight(i,k)=exp(-.5*R^(-1)*(Z(k,1)-Zpre_pf(i,k))^2);%省略了常数项
end
weight(:,k)=weight(:,k)./sum(weight(:,k));%归一化权值
%第三步:根据权值大小对粒子集合重采样,权值集合和粒子集合是一一对应的
%选择采样策略
if ResampleStrategy==1
outIndex = randomR(weight(:,k));
elseif ResampleStrategy==2
outIndex = systematicR(weight(:,k)');
elseif ResampleStrategy==3
outIndex = multinomialR(weight(:,k));
elseif ResampleStrategy==4
outIndex = residualR(weight(:,k)');
end
%第四步:根据重采样得到的索引,去挑选对应的粒子,重构的集合便是滤波后的状态集合
%对这个状态集合求均值,就是最终的目标状态、
Xpf(:,k)=Xparticles(outIndex,k);
end
%计算后验均值估计、最大后验估计及估计方差
Xmean_pf=mean(Xpf);%后验均值估计,及上面的第四步,也即粒子滤波估计的最终状态
bins=20;
Xmap_pf=zeros(T,1);
for k=1:T
[p,pos]=hist(Xpf(:,k,1),bins);
map=find(p==max(p));
Xmap_pf(k,1)=pos(map(1));%最大后验估计
end
for k=1:T
Xstd_pf(1,k)=std(Xpf(:,k)-X(k,1));%后验误差标准差估计
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%画图
figure();clf;%过程噪声和测量噪声图
subplot(221);
plot(v);%测量噪声
xlabel('时间');ylabel('测量噪声');
subplot(222);
plot(w);%过程噪声
xlabel('时间');ylabel('过程噪声');
subplot(223);
plot(X);%真实状态
xlabel('时间');ylabel('状态X');
subplot(224);
plot(Z);%观测值
xlabel('时间');ylabel('观测Z');
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
figure();
k=1:dt:T;
plot(k,X,'b',k,Xmean_pf,'r',k,Xmap_pf,'g');%注:Xmean_pf就是粒子滤波结果
legend('系统真实状态值','后验均值估计','最大后验概率估计');
xlabel('时间');ylabel('状态估计');
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
figure();
subplot(121);
plot(Xmean_pf,X,'+');%粒子滤波估计值与真实状态值如成1:1关系,则会对称分布
xlabel('后验均值估计');ylabel('真值');
hold on;
c=-25:1:25;
plot(c,c,'r');%画红色的对称线y=x
hold off;
subplot(122);%最大后验估计值与真实状态值如成1:1关系,则会对称分布
plot(Xmap_pf,X,'+');
xlabel('Map估计');ylabel('真值');
hold on;
c=-25:25;
plot(c,c,'r');%画红色的对称线y=x
hold off;
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%画直方图,此图形是为了看粒子集的后验密度
domain=zeros(numSamples,1);
range=zeros(numSamples,1);
bins=10;
support=[-20:1:20];
figure();
hold on;%直方图
xlabel('时间');ylabel('样本空间');
vect=[0 1];
caxis(vect);
for k=1:T
%直方图反映滤波后的粒子集合的分布情况
[range,domain]=hist(Xpf(:,k),support);
%调用waterfall函数,将直方图分布的数据画出来
waterfall(domain,k,range);
end
axis([-20 20 0 T 0 100]);
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
figure();
xlabel('样本空间');ylabel('后验密度');
k=30;%k=?表示要查看第几个时刻的粒子分布与真实状态值的重叠关系
[range,domain]=hist(Xpf(:,k),support);
plot(domain,range);
%真实状态在样本空间中的位置,画一条红色直线表示
XXX=[X(k,1),X(k,1)];
YYY=[0,max(range)+10];
line(XXX,YYY,'Color','r');
axis([min(domain) max(domain) 0 max(range)+10]);
figure();
k=1:dt:T;
plot(k,Xstd_pf,'-');
xlabel('时间');ylabel('状态估计误差标准差');
axis([0,T,0,10]);
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%函数功能:实现随机重采样算法
%输入参数:weight为原始数据对应的权重大小
%输出参数:outIndex是根据weight对inIndex筛选和复制结果
function outIndex=randomR(weight)
%获得数据的长度
L=length(weight);
%初始化输出索引向量,长度与输入索引向量相等
outIndex=zeros(1,L);
%第一步:产生[0,1]上均匀分布的随机数组,并升序排序
u=unifrnd(0,1,1,L);
u=sorf(u);
%u=(1:L)/L%这个是完全均匀
%第二步:计算粒子权重积累函数cdf
cdf=cumsum(weight);
%第三步:核心计算
i=1;
for j=1:L
%此处的基本原理是:u是均匀的,必然是权值大的地方
%有更多的随机数落入该区间,因此会被多次复制
while(i<=L)&(u(i)<=cdf(j))
%复制权值大的粒子
outIndex(i)=j;
%继续考察下一个随机数,看它落在哪个区间
i=i+1;
end
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 多项式重采样子函数
% 输入参数:weight为原始数据对应的权重大小
% 输出参数:outIndex是根据weight筛选和复制结果
function outIndex = multinomialR(weight);
%获取数据长度
Col=length(weight)
N_babies= zeros(1,Col);
%计算粒子权重累计函数cdf
cdf= cumsum(weight);
%产生[0,1]均匀分布的随机数
u=rand(1,Col)
%求u^(j^-1)次方
uu=u.^(1./(Col:-1:1))
%如果A是一个向量,cumprod(A)将返回一个包含A各元素积累连乘的结果的向量
%元素个数与原向量相同
ArrayTemp=cumprod(uu)
%fliplr(X)使矩阵X沿垂直轴左右翻转
u = fliplr(ArrayTemp);
j=1;
for i=1:Col
%此处跟随机采样相似
while (u(i)>cdf(j))
j=j+1;
end
N_babies(j)=N_babies(j)+1;
end;
index=1;
for i=1:Col
if (N_babies(i)>0)
for j=index:index+N_babies(i)-1
outIndex(j) = i;
end;
end;
index= index+N_babies(i);
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 函数功能说明:残差重采样函数
% 输入参数:一组权重weight向量
% 输出参数:为该权重重采样后的索引outIndex
function outIndex = residualR(weight)
N= length(weight);
N_babies= zeros(1,N);
q_res = N.*weight;
N_babies = fix(q_res);
N_res=N-sum(N_babies);
if (N_res~=0)
q_res=(q_res-N_babies)/N_res;
cumDist= cumsum(q_res);
u = fliplr(cumprod(rand(1,N_res).^(1./(N_res:-1:1))));
j=1;
for i=1:N_res
while (u(1,i)>cumDist(1,j))
j=j+1;
end
N_babies(1,j)=N_babies(1,j)+1;
end;
end;
index=1;
for i=1:N
if (N_babies(1,i)>0)
for j=index:index+N_babies(1,i)-1
outIndex(j) = i;
end;
end;
index= index+N_babies(1,i);
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 系统重采样子函数
% 输入参数:weight为原始数据对应的权重大小
% 输出参数:outIndex是根据weight筛选和复制结果
function outIndex = systematicR(weight);
N=length(weight);
N_children=zeros(1,N);
label=zeros(1,N);
label=1:1:N;
s=1/N;
auxw=0;
auxl=0;
li=0;
T=s*rand(1);
j=1;
Q=0;
i=0;
u=rand(1,N);
while (T<1)
if (Q>T)
T=T+s;
N_children(1,li)=N_children(1,li)+1;
else
i=fix((N-j+1)*u(1,j))+j;
auxw=weight(1,i);
li=label(1,i);
Q=Q+auxw;
weight(1,i)=weight(1,j);
label(1,i)=label(1,j);
j=j+1;
end
end
index=1;
for i=1:N
if (N_children(1,i)>0)
for j=index:index+N_children(1,i)-1
outIndex(j) = i;
end;
end;
index= index+N_children(1,i);
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
数据分析
数据分析及说明
仿真过程采用自举滤波(SIR算法),每一步迭代都进行重新抽样,根据ResampleStrategy参数设置1-4之间的整数,分别可以选用随机重采样、系统重采样、残差重采样及多项式重采样策略。
(1)状态曲线图
将状态绘制成曲线,能够从宏观上掌握滤波效果,这时往往将滤波器估计的状态和系统真实状态同时展现在图中。得到Q=10,R=1的非线性条件下基于粒子滤波的仿真曲线:
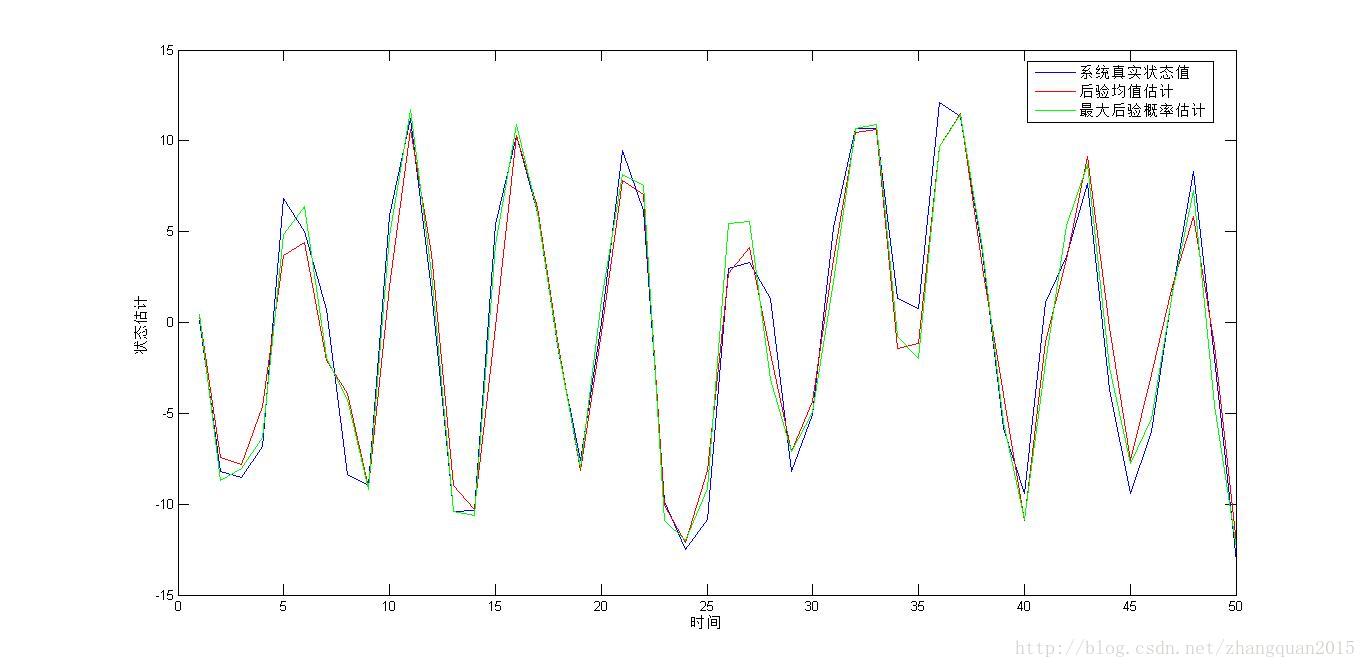
(2)直线散点图:估计与真值的关系
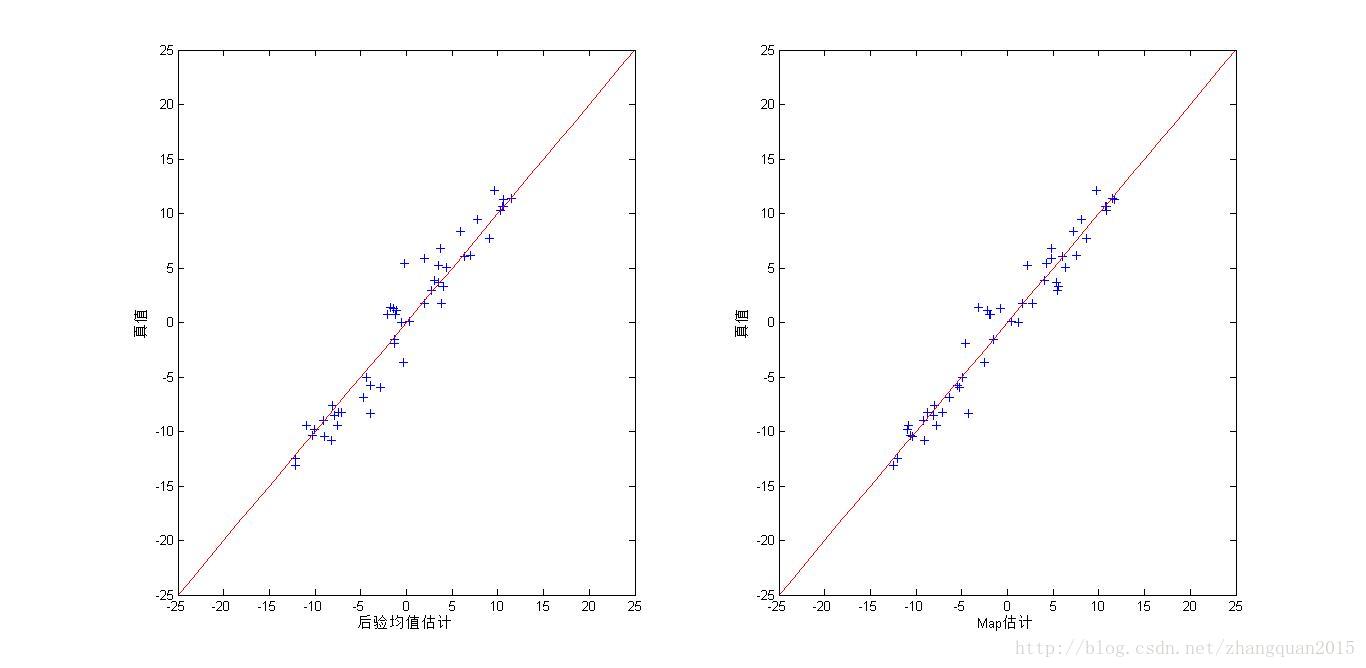
(3)直方图
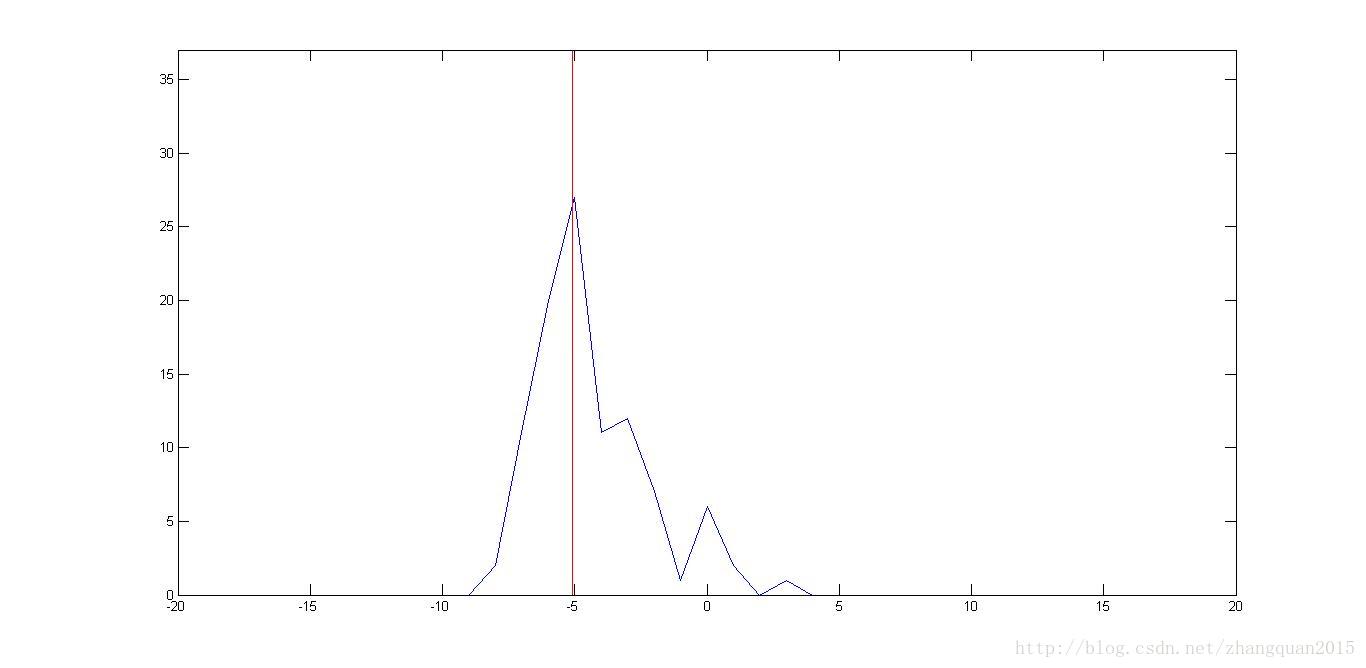
(4)瀑布图
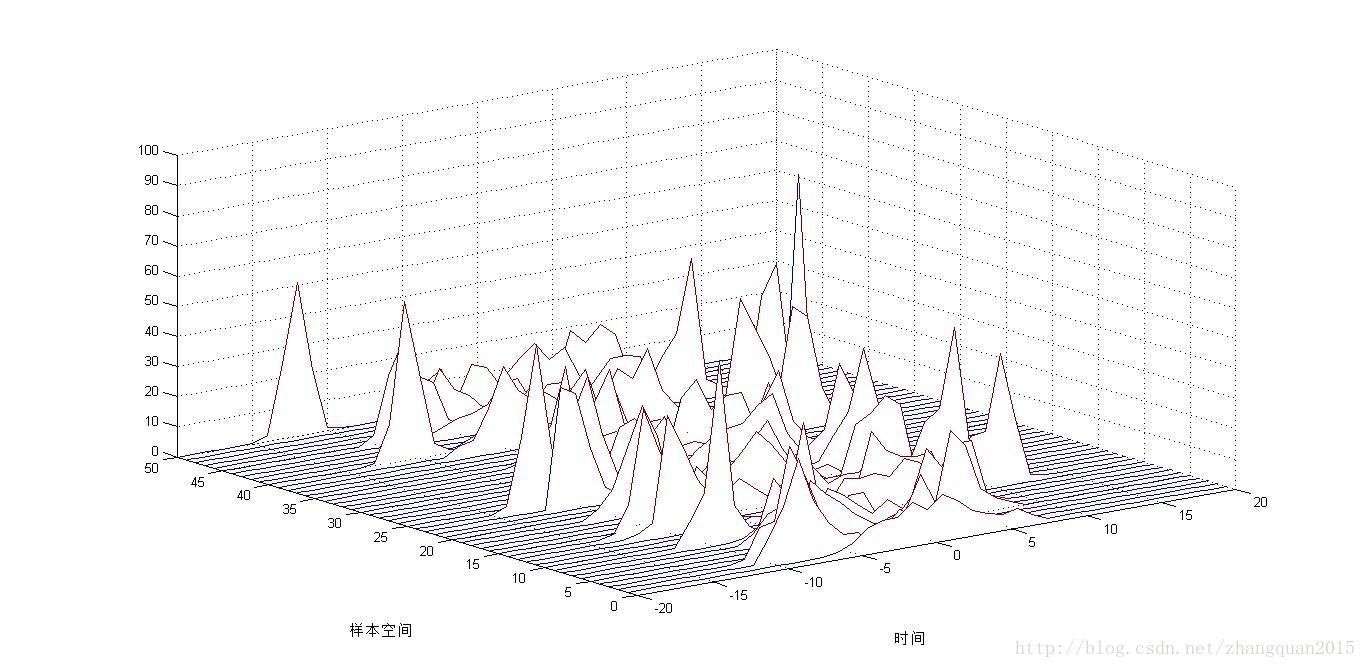
(5)噪声影响
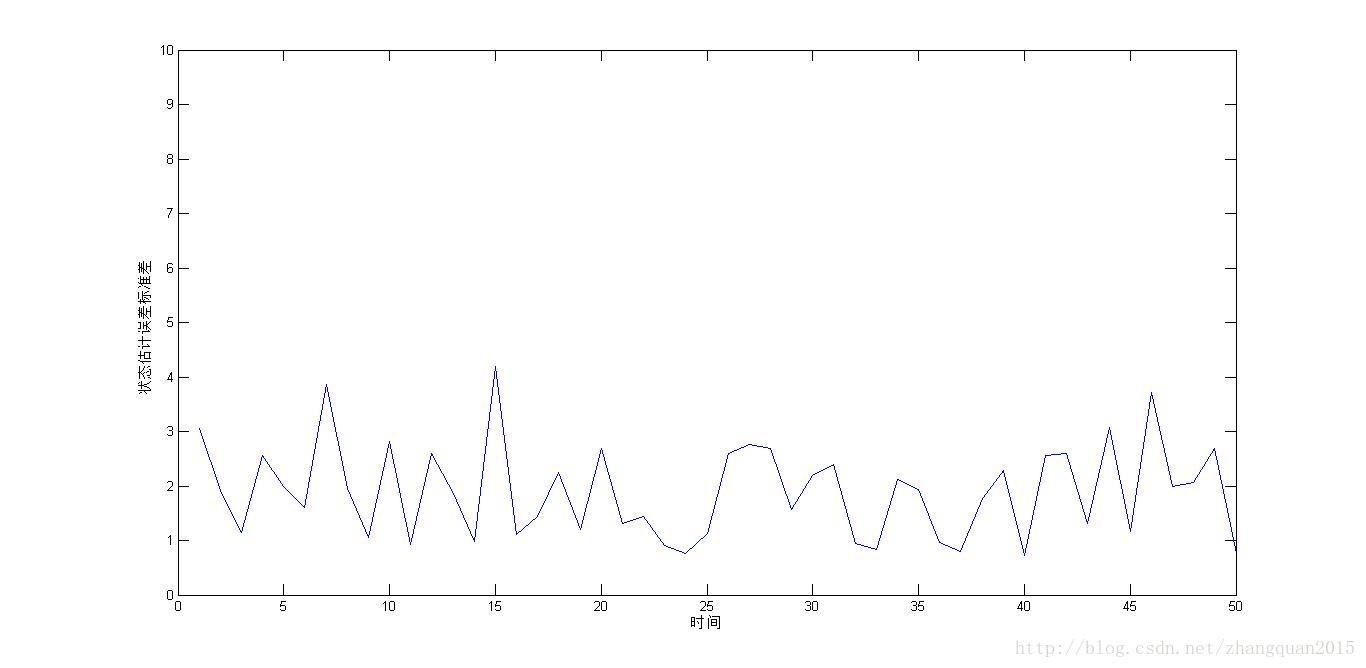
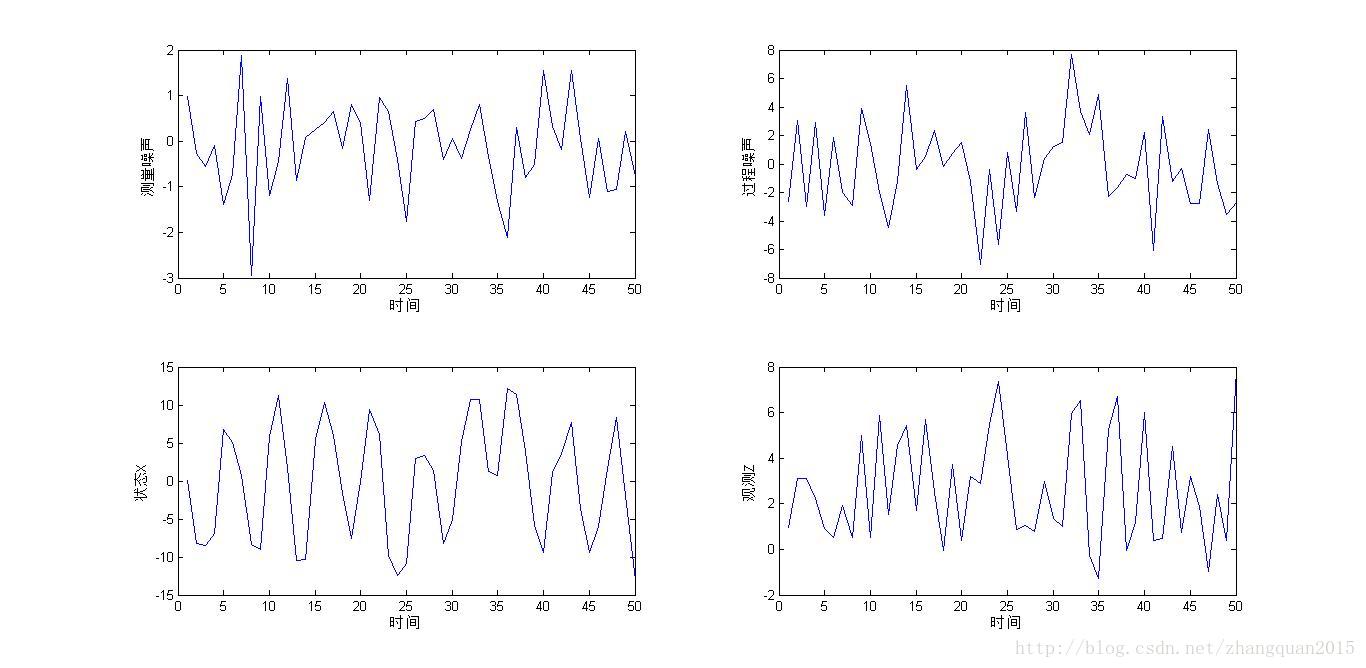
此博客均属原创或译文,欢迎转载但请注明出处
Github个人博客:https://joeyos.github.io