一、什么是Jupyter Notebook?
1. 简介
Jupyter Notebook是基于网页的用于交互计算的应用程序。其可被应用于全过程计算:开发、文档编写、运行代码和展示结果。——Jupyter Notebook官方介绍
简而言之,Jupyter Notebook是以网页的形式打开,可以在网页页面中直接编写代码和运行代码,代码的运行结果也会直接在代码块下显示的程序。如在编程过程中需要编写说明文档,可在同一个页面中直接编写,便于作及时的说明和解释。
2. 组成部分
① 网页应用
网页应用即基于网页形式的、结合了编写说明文档、数学公式、交互计算和其他富媒体形式的工具。简言之,网页应用是可以实现各种功能的工具。
② 文档
即Jupyter Notebook中所有交互计算、编写说明文档、数学公式、图片以及其他富媒体形式的输入和输出,都是以文档的形式体现的。
这些文档是保存为后缀名为.ipynb的JSON格式文件,不仅便于版本控制,也方便与他人共享。
此外,文档还可以导出为:HTML、LaTeX、PDF等格式。
3. Jupyter Notebook的主要特点
① 编程时具有语法高亮、缩进、tab补全的功能。
② 可直接通过浏览器运行代码,同时在代码块下方展示运行结果。
③ 以富媒体格式展示计算结果。富媒体格式包括:HTML,LaTeX,PNG,SVG等。
④ 对代码编写说明文档或语句时,支持Markdown语法。
⑤ 支持使用LaTeX编写数学性说明。
二、安装Jupyter Notebook
0. 先试用,再决定
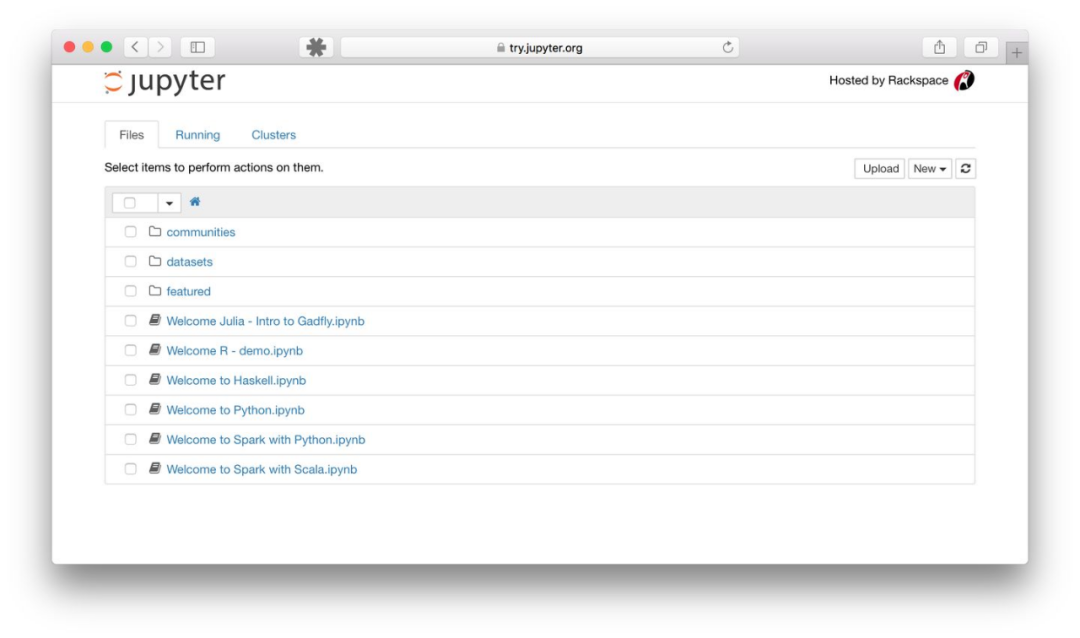
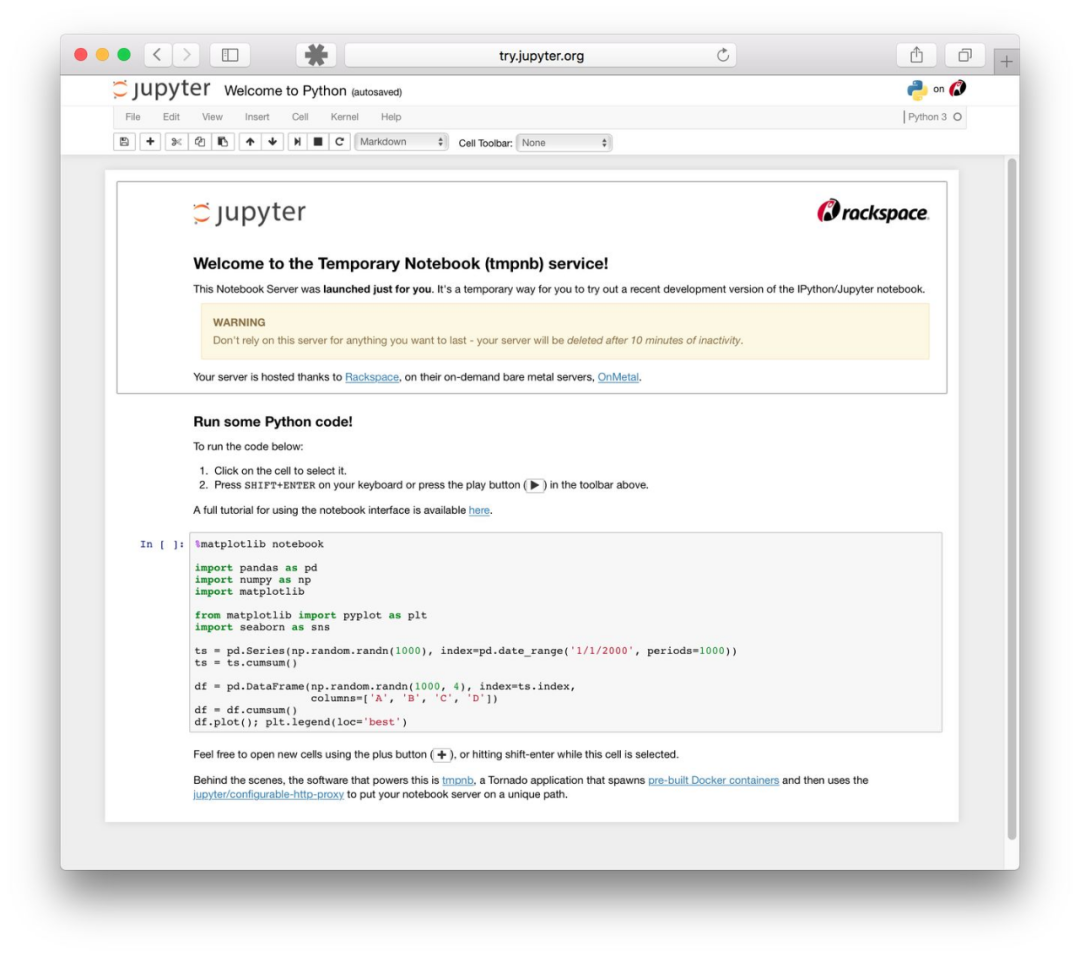
如果看了以上对Jupyter Notebook的介绍你还是拿不定主意究竟是否适合你,那么不要担心,你可以先免安装试用体验一下,戳这里,然后再做决定。
值得注意的是,官方提供的同时试用是有限的,如果你点击链接之后进入的页面如下图所示,那么不要着急,过会儿再试试看吧。

如果你足够幸运,那么你将看到如下界面,就可以开始体验啦。
1. 安装
① 安装前提
安装Jupyter Notebook的前提是需要安装了Python(3.3版本及以上,或2.7版本)。
② 使用Anaconda安装
如果你是小白,那么建议你通过安装Anaconda来解决Jupyter Notebook的安装问题,因为Anaconda已经自动为你安装了Jupter Notebook及其他工具,还有python中超过180个科学包及其依赖项。
你可以通过进入Anaconda的官方下载页面自行选择下载;如果你对阅读英文文档感到头痛,或者对安装步骤一无所知,甚至也想快速了解一下什么是Anaconda,那么可以前往我的另一篇文章:12. Anaconda介绍、安装及使用
你想要的,都在里面!
常规来说,安装了Anaconda发行版时已经自动为你安装了Jupyter Notebook的,但如果没有自动安装,那么就在终端(Linux或macOS的“终端”,Windows的“Anaconda Prompt”,以下均简称“终端”)中输入以下命令安装:
conda install jupyter notebook
③ 使用pip命令安装
如果你是有经验的Python玩家,想要尝试用pip命令来安装JupyterNotebook,那么请看以下步骤吧!接下来的命令都输入在终端当中的噢!
把pip升级到最新版本Python 3.x
pip3 install --upgrade pip
Python 2.x
pip install --upgrade pip
注意:老版本的pip在安装Jupyter Notebook过程中或面临依赖项无法同步安装的问题。因此强烈建议先把pip升级到最新版本。安装Jupyter NotebookPython 3.x
pip3 install jupyter
Python 2.x
pip install jupyter
三、运行Jupyter Notebook
0. 帮助
如果你有任何jupyter notebook命令的疑问,可以考虑查看官方帮助文档,命令如下:
jupyter notebook --help
或
jupyter notebook -h
1. 启动
① 默认端口启动
在终端中输入以下命令:
jupyter notebook
执行命令之后,在终端中将会显示一系列notebook的服务器信息,同时浏览器将会自动启动Jupyter Notebook。
启动过程中终端显示内容如下:
$ jupyter notebook
[I 08:58:24.417 NotebookApp] Serving notebooks from local directory: /Users/catherine
[I 08:58:24.417 NotebookApp] 0 active kernels
[I 08:58:24.417 NotebookApp] The Jupyter Notebook is running at: http://localhost:8888/
[I 08:58:24.417 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
浏览器地址栏中默认地将会显示:http://localhost:8888。其中,“localhost”指的是本机,“8888”则是端口号。

如果你同时启动了多个Jupyter Notebook,由于默认端口“8888”被占用,因此地址栏中的数字将从“8888”起,每多启动一个Jupyter Notebook数字就加1,如“8889”、“8890”……
② 指定端口启动
如果你想自定义端口号来启动Jupyter Notebook,可以在终端中输入以下命令:
jupyter notebook --port
其中,“”是自定义端口号,直接以数字的形式写在命令当中,数字两边不加尖括号“<>”。如:jupyter notebook --port 9999,即在端口号为“9999”的服务器启动Jupyter Notebook。
③ 启动服务器但不打开浏览器
如果你只是想启动Jupyter Notebook的服务器但不打算立刻进入到主页面,那么就无需立刻启动浏览器。在终端中输入:
jupyter notebook --no-browser
此时,将会在终端显示启动的服务器信息,并在服务器启动之后,显示出打开浏览器页面的链接。当你需要启动浏览器页面时,只需要复制链接,并粘贴在浏览器的地址栏中,轻按回车变转到了你的Jupyter Notebook页面。
例图中由于在完成上面内容时我同时启动了多个Jupyter Notebook,因此显示我的“8888”端口号被占用,最终分配给我的是“8889”。
2. 主页面
① 主页面内容
当执行完启动命令之后,浏览器将会进入到Notebook的主页面,如下图所示。
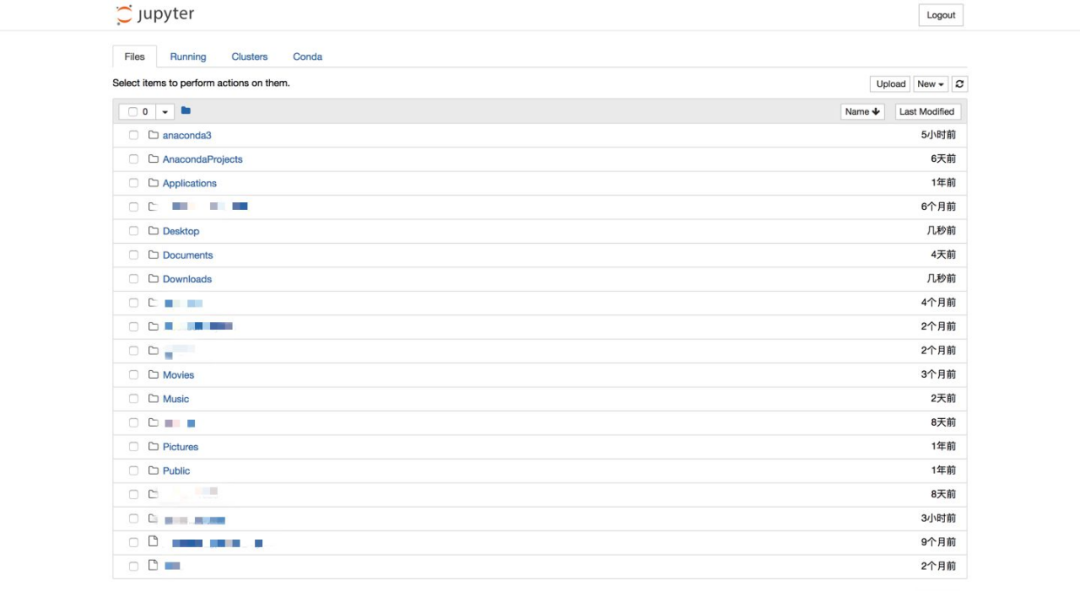
如果你的主页面里边的文件夹跟我的不同,或者你在疑惑为什么首次启动里边就已经有这么多文件夹,不要担心,这里边的文件夹全都是你的家目录里的目录文件。你可以在终端中执行以下2步来查看:
① cd 或 cd - 或 cd ~ 或cd /Users/
这个命令将会进入你的家目录。
“” 是用户名。用户名两边不加尖括号“<>”。
② ls
这个命令将会展示你家目录下的文件。
② 设置Jupyter Notebook文件存放位置
如果你不想把今后在JupyterNotebook中编写的所有文档都直接保存在根目录下,那你需要修改Jupyter Notebook的文件存放路径。
⑴ 创建文件夹/目录
Windows用户在想要存放Jupyter Notebook文件的磁盘中新建文件夹并为该文件夹命名;双击进入该文件夹,然后复制地址栏中的路径。
Linux/macOS用户在想要存放Jupyter Notebook文件的位置创建目录并为目录命名,命令为:mkdir ;进入目录,命令为:cd ;查看目录的路径,命令为:pwd;复制该路径。
注意:“”是自定义的目录名。目录名两边不加尖括号“<>”。
⑵ 配置文件路径
一个便捷获取配置文件所在路径的命令:
jupyter notebook --generate-config
注意:这条命令虽然可以用于查看配置文件所在的路径,但主要用途是是否将这个路径下的配置文件替换为默认配置文件。如果你是第一次查询,那么或许不会出现下图的提示;若文件已经存在或被修改,使用这个命令之后会出现询问“Overwrite /Users/raxxie/.jupyter/jupyter_notebook_config.py with default config? [y/N]”,即“用默认配置文件覆盖此路径下的文件吗?”,如果按“y”,则完成覆盖,那么之前所做的修改都将失效;如果只是为了查询路径,那么一定要输入“N”。

常规的情况下,Windows和Linux/macOS的配置文件所在路径和配置文件名如下所述:
Windows系统的配置文件路径:C:\Users\\.jupyter\
Linux/macOS系统的配置文件路径:/Users//.jupyter/ 或 ~/.jupyter/
配置文件名:jupyter_notebook_config.py
注意:
① “”为你的用户名。用户名两边不加尖括号“<>”。
② Windows和Linux/macOS系统的配置文件存放路径其实是相同的,只是系统不同,表现形式有所不同而已。
③ Windows和Linux/macOS系统的配置文件也是相同的。文件名以“.py”结尾,是Python的可执行文件。
④ 如果你不是通过一步到位的方式前往配置文件所在位置,而是一层一层进入文件夹/目录的,那么当你进入家目录后,用ls命令会发现找不到“.jupyter”文件夹/目录。这是因为凡是以“.”开头的目录都是隐藏文件,你可以通过ls -a命令查看当前位置下所有的隐藏文件。
⑶ 修改配置文件
Windows系统的用户可以使用文档编辑工具或IDE打开“jupyter_notebook_config.py”文件并进行编辑。常用的文档编辑工具和IDE有记事本、Notepad++、vim、SublimeText、PyCharm等。其中,vim是没有图形界面的,是一款学习曲线较为陡峭的编辑器,其他工具在此不做使用说明,因为上手相对简单。通过vim修改配置文件的方法请继续往下阅读。
Linux/macOS系统的用户建议直接通过终端调用vim来对配置文件进行修改。具体操作步骤如下:
⒜ 打开配置文件
打开终端,输入命令:
vim ~/.jupyter/jupyter_notebook_config.py

执行上述命令后便进入到配置文件当中了。
⒝ 查找关键词
进入配置文件后查找关键词“c.NotebookApp.notebook_dir”。查找方法如下:
进入配置文件后不要按其他键,用英文半角直接输入/c.NotebookApp.notebook_dir,这时搜索的关键词已在文档中高亮显示了,按回车,光标从底部切换到文档正文中被查找关键词的首字母。
⒞ 编辑配置文件
按小写i进入编辑模式,底部出现“--INSERT--”说明成功进入编辑模式。使用方向键把光标定位在第二个单引号上(光标定位在哪个字符,就在这个字符前开始输入),把“⑴ 创建文件夹/目录”步骤中复制的路径粘贴在此处。
⒟ 取消注释
把该行行首的井号(#)删除。因为配置文件是Python的可执行文件,在Python中,井号(#)表示注释,即在编译过程中不会执行该行命令,所以为了使修改生效,需要删除井号(#)。
⒠ 保存配置文件
先按esc键,从编辑模式退出,回到命令模式。
再用英文半角直接输入:wq,回车即成功保存且退出了配置文件。
注意:
冒号(:) 一定要有,且也是英文半角。
w:保存。
q:退出。
⒡ 验证
在终端中输入命令jupyter notebook打开Jupyter Notebook,此时你会看到一个清爽的界面,恭喜!
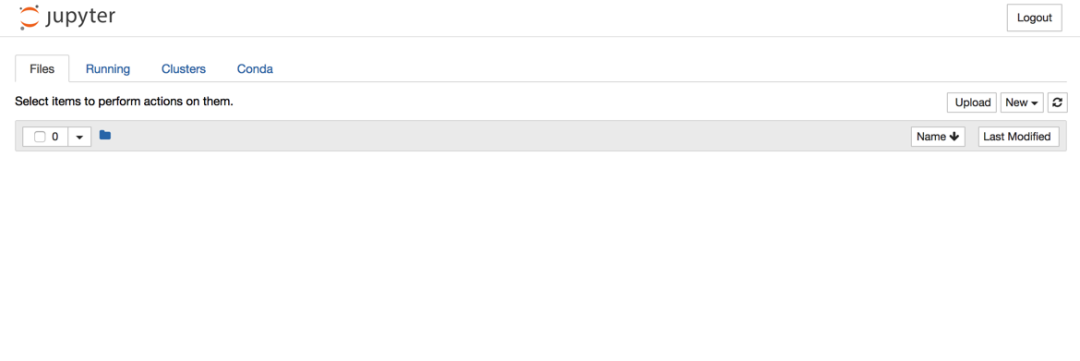
此时你的界面当中应该还没有“Conda”和“Nbextensions”类目。不要着急,这两个类目将分别在“五、拓展功能”中的“1.关联Jupyter Notebook和conda的环境和包——‘nb_conda’”和“2.Markdown生成目录”中安装。
Files页面是用于管理和创建文件相关的类目。
对于现有的文件,可以通过勾选文件的方式,对选中文件进行复制、重命名、移动、下载、查看、编辑和删除的操作。
同时,也可以根据需要,在“New”下拉列表中选择想要创建文件的环境,进行创建“ipynb”格式的笔记本、“txt”格式的文档、终端或文件夹。如果你创建的环境没有在下拉列表中显示,那么你需要依次前往“五、拓展功能”中的“1.关联Jupyter Notebook和conda的环境和包——‘nb_conda’”和“六、增加内核——‘ipykernel’”中解决该问题。
① 笔记本的基本操作
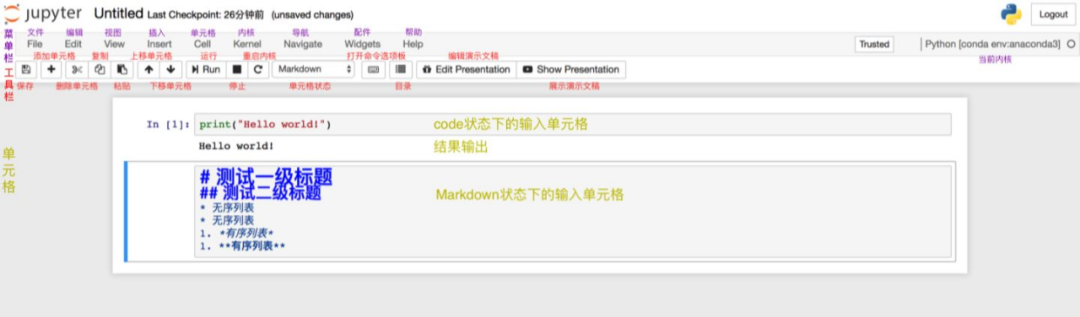
上图展示的是笔记本的基本结构和功能。根据图中的注解已经可以解决绝大多数的使用问题了!
工具栏的使用如图中的注解一样直观,在此不过多解释。需要特别说明的是“单元格的状态”,有Code,Markdown,Heading,Raw NBconvert。其中,最常用的是前两个,分别是代码状态,Markdown编写状态。Jupyter Notebook已经取消了Heading状态,即标题单元格。取而代之的是Markdown的一级至六级标题。而Raw NBconvert目前极少用到,此处也不做过多讲解。
菜单栏涵盖了笔记本的所有功能,即便是工具栏的功能,也都可以在菜单栏的类目里找到。然而,并不是所有功能都是常用的,比如Widgets,Navigate。Kernel类目的使用,主要是对内核的操作,比如中断、重启、连接、关闭、切换内核等,由于我们在创建笔记本时已经选择了内核,因此切换内核的操作便于我们在使用笔记本时切换到我们想要的内核环境中去。由于其他的功能相对比较常规,根据图中的注解来尝试使用笔记本的功能已经非常便捷,因此不再做详细讲解。
② 笔记本重命名的两种方式
⑴ 笔记本内部重命名
在使用笔记本时,可以直接在其内部进行重命名。在左上方“Jupyter”的图标旁有程序默认的标题“Untitled”,点击“Untitled”然后在弹出的对话框中输入自拟的标题,点击“Rename”即完成了重命名。
⑵ 笔记本外部重命名
若在使用笔记本时忘记了重命名,且已经保存并退出至“Files”界面,则在“Files”界面勾选需要重命名的文件,点击“Rename”然后直接输入自拟的标题即可。
2. Running页面
Running页面主要展示的是当前正在运行当中的终端和“ipynb”格式的笔记本。若想要关闭已经打开的终端和“ipynb”格式的笔记本,仅仅关闭其页面是无法彻底退出程序的,需要在Running页面点击其对应的“Shutdown”。更多关闭方法可以查阅“八、关闭和退出”中的“1.关闭笔记本和终端”
3. Clusters页面
Clusters tab is now provided by IPython parallel. See 'IPython parallel' forinstallation details.
Clusters类目现在已由IPython parallel对接,且由于现阶段使用频率较低,因此在此不做详细说明,想要了解更多可以访问IPython parallel的官方网站。
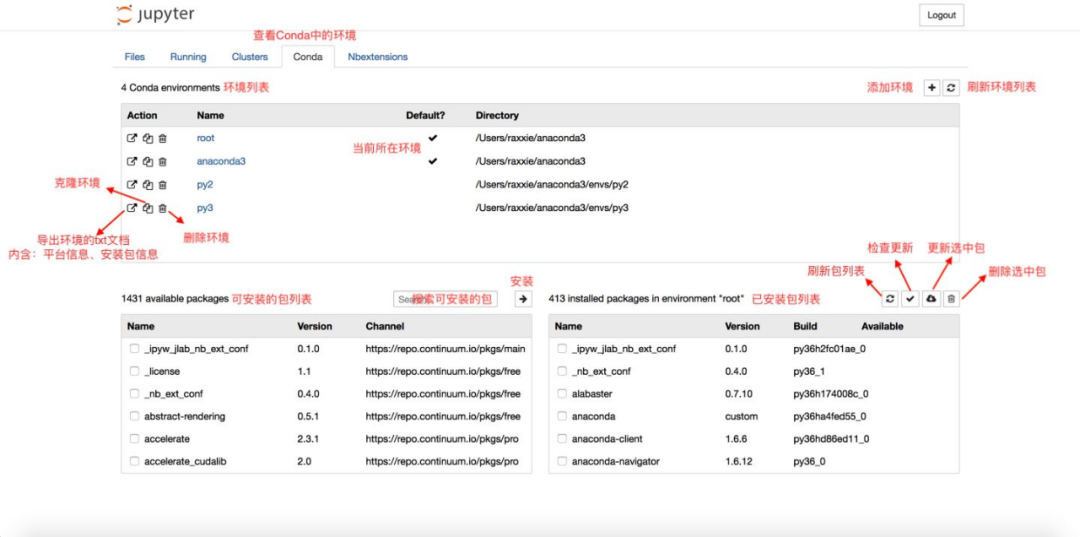
4. Conda页面
Conda页面主要是Jupyter Notebook与Conda关联之后对Conda环境和包进行直接操作和管理的页面工具。详细信息请直接查阅“五、拓展功能”中的“1.关联Jupyter Notebook和conda的环境和包——‘nb_conda’”。这是目前使用Jupyter Notebook的必备环节,因此请务必查阅。
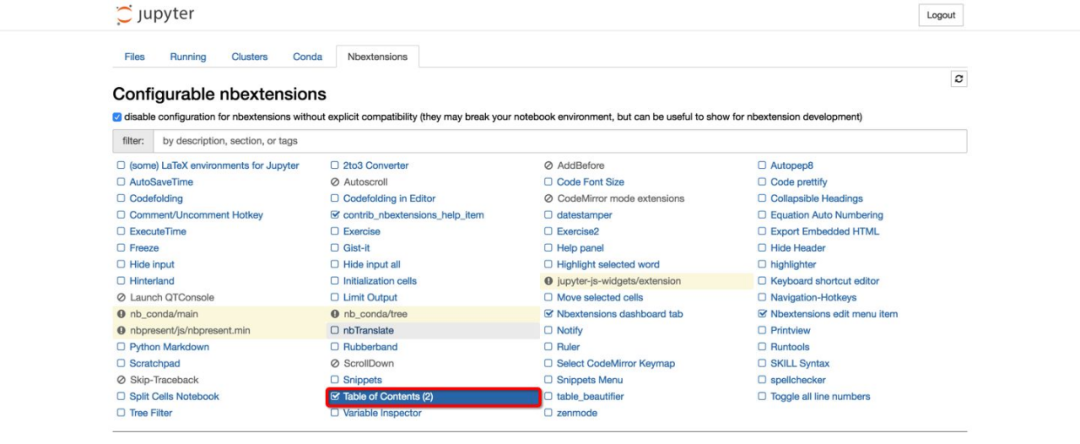
5. Nbextensions页面
Nbextensions页面提供了多个Jupyter Notebook的插件,使其功能更加强大。该页面中主要使用的插件有nb_conda,nb_present,Table of Contents(2)。这些功能我们无需完全掌握,也无需安装所有的扩展功能,根据本文档提供的学习思路,我们只需要安装Talbe of Contents(2)即可,该功能可为Markdown文档提供目录导航,便于我们编写文档。该安装指导请查阅“五、拓展功能”中的“2.Markdown生成目录”。
四、拓展功能
1. 关联Jupyter Notebook和conda的环境和包——“nb_conda”☆
① 安装
conda install nb_conda
执行上述命令能够将你conda创建的环境与Jupyter Notebook相关联,便于你在Jupyter Notebook的使用中,在不同的环境下创建笔记本进行工作。
② 使用
可以在Conda类目下对conda环境和包进行一系列操作。
可以在笔记本内的“Kernel”类目里的“Changekernel”切换内核。
Preview unavailable
③ 卸载
canda remove nb_conda
执行上述命令即可卸载nb_conda包。
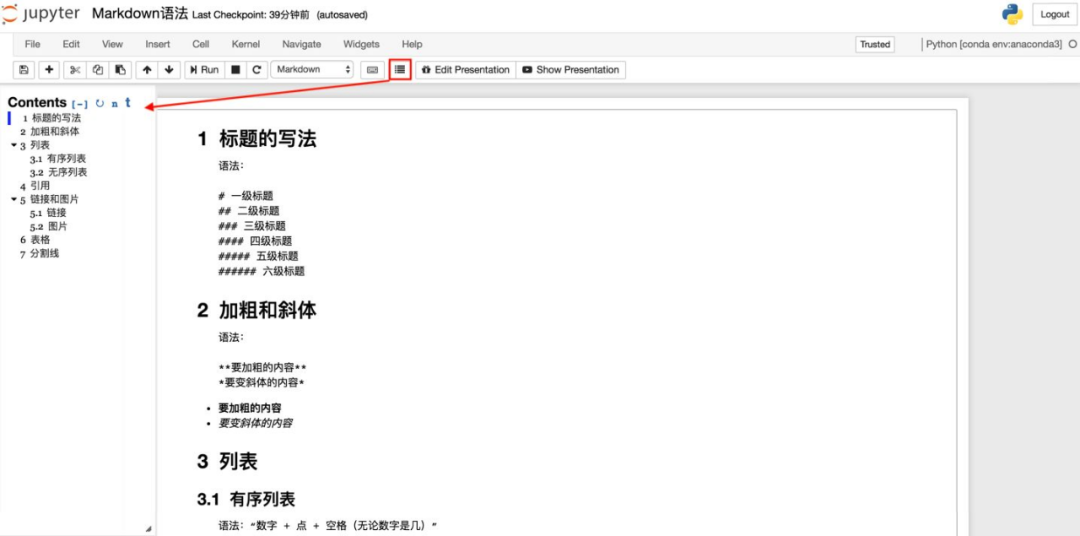
2. Markdown生成目录
不同于有道云笔记的Markdown编译器,Jupyter Notebook无法为Markdown文档通过特定语法添加目录,因此需要通过安装扩展来实现目录的添加。
conda install -c conda-forge jupyter_contrib_nbextensions
执行上述命令后,启动Jupyter Notebook,你会发现导航栏多了“Nbextensions”的类目,点击“Nbextensions”,勾选“Tableof Contents ⑵”
3. Markdown在文中设置链接并定位
在使用Markdown编辑文档时,难免会遇到需要在文中设定链接,定位在文档中的其他位置便于查看。因为Markdown可以完美的兼容html语法,因此这种功能可以通过html语法当中“a标签”的索引用法来实现。
语法格式如下:
1[添加链接的正文](#自定义索引词)
2跳转提示
注意:
语法格式当中所有的符号均是英文半角。
“自定义索引词”最好是英文,较长的词可以用下划线连接。
“a标签”出现在想要被跳转到的文章位置,html标签除了单标签外均要符合“有头()必有尾()”的原则。头尾之间的“跳转提示”是可有可无的。
“a标签”中的“id”值即是为正文中添加链接时设定的“自定义索引值”,这里通过“id”的值实现从正文的链接跳转至指定位置的功能。、
4. 加载指定网页源代码
① 使用场景
想要在Jupyter Notebook中直接加载指定网站的源代码到笔记本中。
② 方法
执行以下命令:
1%load URL
其中,URL为指定网站的地址。
5. 加载本地Python文件
① 使用场景
想在Jupyter Notebook中加载本地的Python文件并执行文件代码。
② 方法
执行以下命令:
%load
Python文件的绝对路径
③ 注意
Python文件的后缀为“.py”。
“%load”后跟的是Python文件的绝对路径。
输入命令后,可以按CTRL 回车来执行命令。第一次执行,是将本地的Python文件内容加载到单元格内。此时,Jupyter Notebook会自动将“%load”命令注释掉(即在前边加井号“#”),以便在执行已加载的文件代码时不重复执行该命令;第二次执行,则是执行已加载文件的代码。
6. 直接运行本地Python文件
① 使用场景
不想在Jupyter Notebook的单元格中加载本地Python文件,想要直接运行。
② 方法
执行命令:
%run
Python文件的绝对路径
或
!python3
Python文件的绝对路径
或
!python
Python文件的绝对路径
③ 注意
Python文件的后缀为“.py”。
“%run”后跟的是Python文件的绝对路径。
“!python3”用于执行Python3.x版本的代码。
“!python”用于执行Python2.x版本的代码。
“!python3”和“!python”属于 !shell命令 语法的使用,即在Jupyter Notebook中执行shell命令的语法。
输入命令后,可以按 control return 来执行命令,执行过程中将不显示本地Python文件的内容,直接显示运行结果。
7. 在Jupyter Notebook中获取当前位置
① 使用场景
想要在Jupyter Notebook中获取当前所在位置的绝对路径。
② 方法
%pwd
或
!pwd
③ 注意
获取的位置是当前Jupyter Notebook中创建的笔记本所在位置,且该位置为绝对路径。
“!pwd”属于 !shell命令 语法的使用,即在JupyterNotebook中执行shell命令的语法。
8. 在Jupyter Notebook使用shell命令
① 方法一——在笔记本的单元格中
⑴ 语法
1!shell命令
在Jupyter Notebook中的笔记本单元格中用英文感叹号“!”后接shell命令即可执行shell命令。
② 方法二——在Jupyter Notebook中新建终端
⑴ 启动方法
在Jupyter Notebook主界面,即“File”界面中点击“New”;在“New”下拉框中点击“Terminal”即新建了终端。此时终端位置是在你的家目录,可以通过pwd命令查询当前所在位置的绝对路径。
⑵ 关闭方法
在Jupyter Notebook的“Running”界面中的“Terminals”类目中可以看到正在运行的终端,点击后边的“Shutdown”即可关闭终端。
9. 隐藏笔记本输入单元格
① 使用场景
在Jupyter Notebook的笔记本中无论是编写文档还是编程,都有输入(In [])和输出(Out [])。当我们编写的代码或文档使用的单元格较多时,有时我们只想关注输出的内容而暂时不看输入的内容,这时就需要隐藏输入单元格而只显示输出单元格。
② 方法一
⑴ 代码
from IPython.display import display
from IPython.display import HTML
import IPython.core.display as di # Example: di.display_html('<h3>%s:</h3>' % str, raw=True)
# 这行代码的作用是:当文档作为HTML格式输出时,将会默认隐藏输入单元格。
di.display_html('<script>jQuery(function() {if (jQuery("body.notebook_app").length == 0) { jQuery(".input_area").toggle(); jQuery(".prompt").toggle();}});</script>', raw=True)
# 这行代码将会添加“Toggle code”按钮来切换“隐藏/显示”输入单元格。
di.display_html('''<button onclick="jQuery('.input_area').toggle(); jQuery('.prompt').toggle();">Toggle code</button>''', raw=True)
在笔记本第一个单元格中输入以上代码,然后执行,即可在该文档中使用“隐藏/显示”输入单元格功能。
缺陷:此方法不能很好的适用于Markdown单元格。
③ 方法二
⑴ 代码
from IPython.display import HTML
HTML('''<script>
code_show=true;
function code_toggle() {
if (code_show){
$('div.input').hide();
} else {
$('div.input').show();
}
code_show = !code_show
}
$( document ).ready(code_toggle);
</script>
<form action="javascript:code_toggle()"><input type="submit" value="Click here to toggle on/off the raw code."></form>''')
''')
在笔记本第一个单元格中输入以上代码,然后执行,即可在该文档中使用“隐藏/显示”输入单元格功能。
缺陷:此方法不能很好的适用于Markdown单元格。
10. 魔术命令
由于目前暂时用不到过多的魔术命令,因此暂时先参考官网的文档。
五、增加内核——“ipykernel” ☆
1. 使用场景
场景一:同时用不同版本的Python进行工作,在Jupyter Notebook中无法切换,即“New”的下拉菜单中无法使用需要的环境。
场景二:创建了不同的虚拟环境(或许具有相同的Python版本但安装的包不同),在Jupyter Notebook中无法切换,即“New”的下拉菜单中无法使用需要的环境。
接下来将分别用“命令行模式”和“图形界面模式”来解决以上两个场景的问题。顾名思义,“命令行模式”即在终端中通过执行命令来一步步解决问题;“图形界面模式”则是通过在Jupyter Notebook的网页中通过鼠标点击的方式解决上述问题。
其中,“图形界面模式”的解决方法相对比较简单快捷,如果对于急于解决问题,不需要知道运行原理的朋友,可以直接进入“3. 解决方法之图形界面模式”来阅读。
“命令行模式”看似比较复杂,且又划分了使用场景,但通过这种方式来解决问题可以更好的了解其中的工作原理,比如,每进行一步操作对应的命令是什么,而命令的执行是为了达到什么样的目的,这些可能都被封装在图形界面上的一个点击动作来完成了。对于想更深入了解其运作过程的朋友,可以接着向下阅读。
2. 解决方法之命令行模式
① 同时使用不同版本的Python
⑴ 在Python 3中创建Python 2内核
⒜ pip安装
首先安装Python 2的ipykernel包。
python2 -m pip install ipykernel
再为当前用户安装Python 2的内核(ipykernel)。
python2 -m ipykernel install --user
注意:“--user”参数的意思是针对当前用户安装,而非系统范围内安装。
⒝ conda安装
首先创建Python版本为2.x且具有ipykernel的新环境,其中“”为自定义环境名,环境名两边不加尖括号“<>”。
conda create -n python=2 ipykernel
然后切换至新创建的环境。
Windows: activate 2Linux/macOS: source activate
为当前用户安装Python 2的内核(ipykernel)。
python2 -m ipykernel install --user
注意:“--user”参数的意思是针对当前用户安装,而非系统范围内安装。
⑵ 在Python 2中创建Python 3内核
⒜ pip安装
首先安装Python 3的ipykernel包。
python3 -m pip install ipykernel
再为当前用户安装Python 2的内核(ipykernel)。
python3 -m ipykernel install --user
注意:“--user”参数的意思是针对当前用户安装,而非系统范围内安装。
⒝ conda安装
首先创建Python版本为3.x且具有ipykernel的新环境,其中“”为自定义环境名,环境名两边不加尖括号“<>”。
conda create -n python=3 ipykernel
然后切换至新创建的环境。
Windows: activate 2Linux/macOS: source activate
为当前用户安装Python 3的内核(ipykernel)。
python3 -m ipykernel install --user
注意:“--user”参数的意思是针对当前用户安装,而非系统范围内安装。
② 为不同环境创建内核
⑴ 切换至需安装内核的环境
Windows: activate 2Linux/macOS: source activate
注意:“”是需要安装内核的环境名称,环境名两边不加尖括号“<>”。
⑵ 检查该环境是否安装了ipykernel包
conda list
执行上述命令查看当前环境下安装的包,若没有安装ipykernel包,则执行安装命令;否则进行下一步。
conda install ipykernel
⑶ 为当前环境下的当前用户安装Python内核
若该环境的Python版本为2.x,则执行命令:
python2 -m ipykernel install --user --name --display-name ""
若该环境的Python版本为3.x,则执行命令:
python3 -m ipykernel install --user --name --display-name ""
注意:“”为当前环境的环境名称。环境名两边不加尖括号“<>”。
“”为自定义显示在Jupyter Notebook中的名称。名称两边不加尖括号“<>”,但
双引号必须加。
“--name”参数的值,即“”是Jupyter内部使用的,其目录的存放路径为
~/Library/Jupyter/kernels/。如果定义的名称在该路径已经存在,那么将自动覆盖该名称目录的内容。
“--display-name”参数的值是显示在Jupyter Notebook的菜单中的名称。
⑷ 检验
使用命令jupyter notebook启动Jupyter Notebook;在“Files”下的“New”下拉框中即可找到你在第⑶步中的自定义名称,此时,你便可以尽情地在Jupyter Notebook中切换环境,在不同的环境中创建笔记本进行工作和学习啦!
3. 解决方法之图形界面模式
① 你创建了一个新的环境,但却发现在Jupyter Notebook的“New”中找不到这个环境,无法在该环境中创建笔记本。
② 进入Jupyter Notebook → Conda → 在“Condaenvironment”中点击你要添加ipykernel包的环境 → 左下方搜索框输入“ipykernel”→ 勾选“ipykernel” → 点击搜索框旁的“→”箭头 → 安装完毕 → 右下方框内找到“ipykernel”说明已经安装成功
③ 在终端control c关闭Jupyter Notebook的服务器然后重启Jupyter Notebook,在“File”的“New”的下拉列表里就可以找到你的环境啦。
六、Jupyter Notebook快捷键
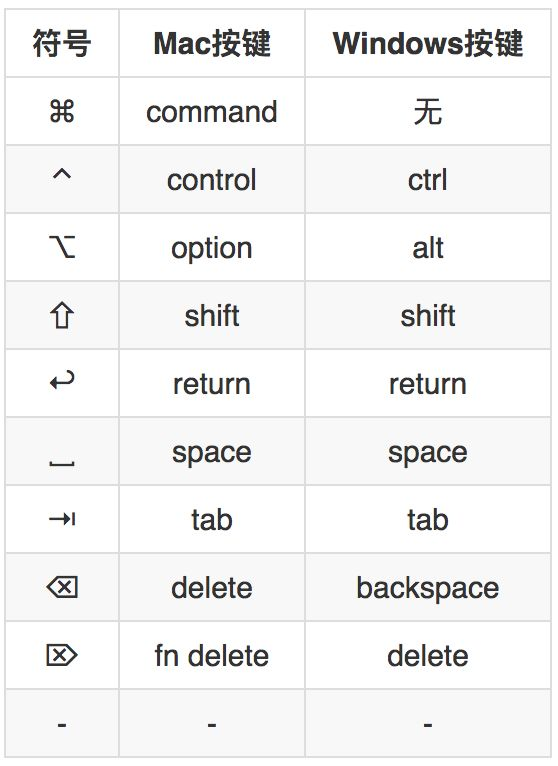
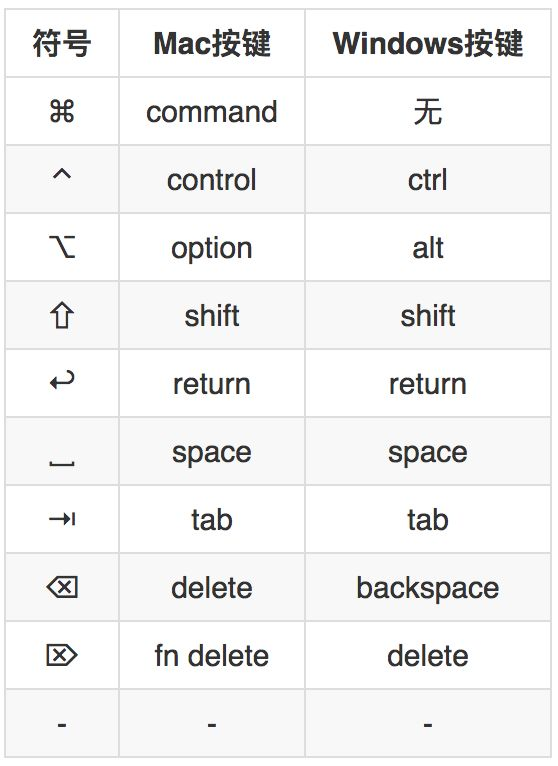
1. Mac与Windows特殊按键对照表
2. Jupyter Notebook笔记本的两种模式
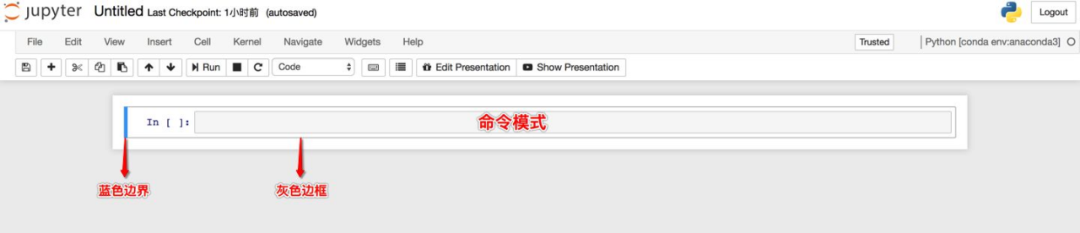
① 命令模式
命令模式将键盘命令与Jupyter Notebook笔记本命令相结合,可以通过键盘不同键的组合运行笔记本的命令。
按esc键进入命令模式。
命令模式下,单元格边框为灰色,且左侧边框线为蓝色粗线条。
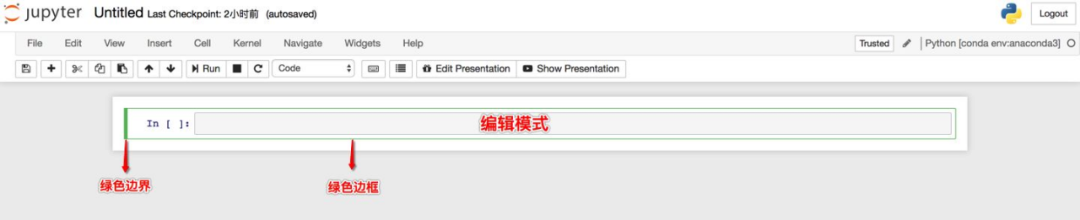
② 编辑模式
编辑模式使用户可以在单元格内编辑代码或文档。
按enter或return键进入编辑模式。
编辑模式下,单元格边框和左侧边框线均为绿色。
3. 两种模式的快捷键
① 命令模式
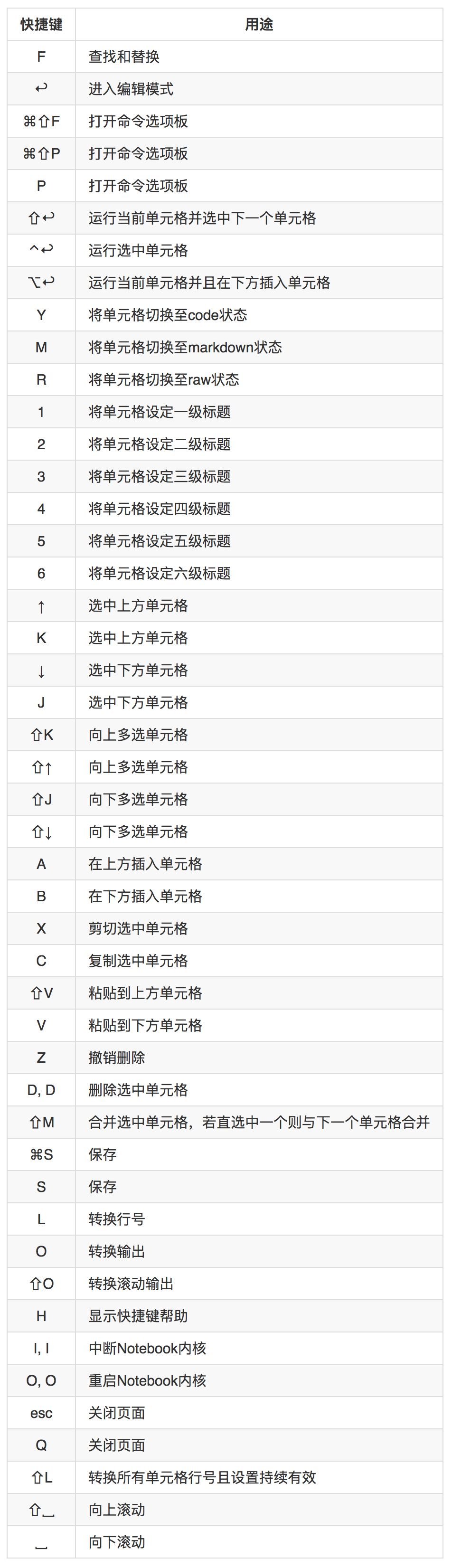
② 编辑模式
4. 查看和编辑快捷键
① 查看快捷键
① 进入Jupyter Notebook主界面“File”中。
② 在“New”的下拉列表中选择环境创建一个笔记本。
③ 点击“Help”。
④ 点击“Keyboard Shortcuts”。
② 编辑快捷键
⑴ 方法一
① 进入Jupyter Notebook主界面“File”中。
② 在“New”的下拉列表中选择环境创建一个笔记本。
③ 点击“Help”。
④ 点击“Keyboard Shortcuts”。
⑤ 弹出的对话框中“Command Mode (press Esc to enable)”旁点击“EditShortcuts”按钮。
⑵ 方法二
① 进入Jupyter Notebook主界面“File”中。
② 在“New”的下拉列表中选择环境创建一个笔记本。
③ 点击“Help”。
④ 点击“Edit Keyboard Shortcuts”。
七、关闭和退出
1. 关闭笔记本和终端
当我们在Jupyter Notebook中创建了终端或笔记本时,将会弹出新的窗口来运行终端或笔记本。当我们使用完毕想要退出终端或笔记本时,仅仅关闭页面是无法结束程序运行的,因此我们需要通过以下步骤将其完全关闭。
① 方法一
⑴ 进入“Files”页面。
⑵ 勾选想要关闭的“ipynb”笔记本。正在运行的笔记本其图标为绿色,且后边标有“Running”的字样;已经关闭的笔记本其图标为灰色。
⑶ 点击上方的黄色的“Shutdown”按钮。
⑷ 成功关闭笔记本。
注意:此方法只能关闭笔记本,无法关闭终端。
② 方法二
⑴ 进入“Running”页面。
⑵ 第一栏是“Terminals”,即所有正在运行的终端均会在此显示;第二栏是“Notebooks”,即所有正在运行的“ipynb”笔记本均会在此显示。
⑶ 点击想要关闭的终端或笔记本后黄色“Shutdown”按钮。
⑷ 成功关闭终端或笔记本。
注意:此方法可以关闭任何正在运行的终端和笔记本。
③ 注意
⑴ 只有“ipynb”笔记本和终端需要通过上述方法才能使其结束运行。
⑵“txt”文档,即“New”下拉列表中的“TextFile”,以及“Folder”只要关闭程序运行的页面即结束运行,无需通过上述步骤关闭。
2. 退出Jupyter Notebook程序
如果你想退出Jupyter Notebook程序,仅仅通过关闭网页是无法退出的,因为当你打开Jupyter Notebook时,其实是启动了它的服务器。
你可以尝试关闭页面,并打开新的浏览器页面,把之前的地址输进地址栏,然后跳转页面,你会发现再次进入了刚才“关闭”的Jupyter Notebook页面。
如果你忘记了刚才关闭的页面地址,可以在启动Jupyter Notebook的终端中找到地址,复制并粘贴至新的浏览器页面的地址栏,会发现同样能够进入刚才关闭的页面。
因此,想要彻底退出Jupyter Notebook,需要关闭它的服务器。只需要在它启动的终端上按:
Mac用户:control c
Windows用户:ctrl c
然后在终端上会提示:“Shutdown this notebook server (y/[n])?”输入y即可关闭服务器,这才是彻底退出了Jupyter Notebook程序。此时,如果你想要通过输入刚才关闭网页的网址进行访问Jupyter Notebook便会看到报错页面。
至此,Jupyter Notebook介绍、安装及使用介绍完毕。
了解更多项目实战请关注字节智传公众号

往期精彩
8. CentOS安装zookeeper(集群版)
9. CentOS安装Hbase安装(集群版)
10. CentOS安装Flume
11. CentOS安装Kafka(集群版)
12. Anaconda介绍、安装及使用