简介
主页:https://3d-representation-learning.github.io/nerf-dy/
机器人操作模型学习的核心问题之一是如何确定 dynamics model 的状态表示,理想的表示应该易于捕捉环境动态,展示对场景中对象的良好3D理解,并适用于各种对象集,如刚性或可变形的对象和流体。
- image-space dynamics:在图像像素空间中直接学习 dynamics
model,在这种高维空间中建模动力学具有挑战性,这些方法在进行长视距未来预测时通常会产生模糊的图像。
- keypoint representation:只专注于预测被确定为关键点的任务相关特征,在类别级别的泛化方面表现良好,即同一组关键点可以表示同一类别中的不同实例,但不足以建模具有较大变化的对象,如流体和颗粒材料
- low-dimensional latent space:学习潜在空间中的 dynamics model,这些方法中的大多数使用二维卷积神经网络和重建损失来学习 dynamics model——这与预测图像空间中的 dynamics model 存在相同的问题,即,它们的学习表示缺乏 equivariance to 3D transformations,另一方面,Time contrastive networks 旨在从多视图输入中学习视图不变表示,但不需要对3D内容进行详细建模。因此,对于状态估计器来说,以前未见过的场景和相机姿态是数据分布外的情况。
贡献点
- 用神经辐射场渲染模块和时间对比学习扩展了一个自动编码框架,能够学习3d感知场景表示,用于纯视觉观察的 dynamics 建模和控制。
- 通过在测试时加入自动解码器机制,框架可以调整学习到的表示,并以训练分布外的摄像机视点指定的目标完成控制任务
- 第一个使用时不变 dynamics module 增强神经辐射场的人,支持未来的预测和不同类型物体在广泛环境中的新视图合成。
Model-Based RL in Robotic Manipulation
可以根据基于模型的RL方法是使用基于物理的模型还是数据驱动的模型,以及它们假设完全状态访问还是仅进行可视化观察来对它们进行分类。
- 依赖于基于物理模型的方法通常假设环境的全状态信息,并且需要对象模型的知识,这使得它们很难推广到新的对象或部分可观察的场景
- 对于数据驱动模型,人们尝试学习 closed-loop planar pushing 或 dexterous manipulation 的 dynamics module。尽管它们取得了令人印象深刻的结果,但它们依赖于为特定任务定制的状态估计器,限制了它们对更通用和更多样化的操作任务的适用性。
- 人们提出了各种基于模型的RL方法来从视觉观察中学习状态表示,如 image-space dynamics 、keypoint representation 和 low dimensional latent space。
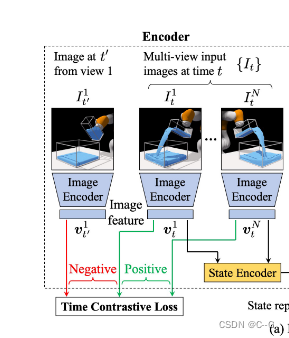
实现流程

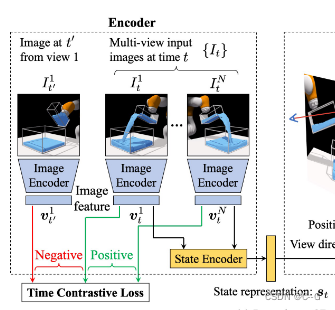
左:将输入图像映射到潜在状态表示的编码器
首先将图像发送到图像编码器(Image Encoder)中生成图像特征表示 v,然后使用状态编码器(State Encoder) 将来自同一时间步长的图像特征组合得到状态表示
s
t
s_t
st,应用 time contrastive loss 使模型不受相机视点的影响。
中间:以场景表示作为输入,并根据给定的视点生成视觉观察的解码器。
使用L2损耗来保证重建图像与真实图像相似。
右:一个 dynamics model ,通过考虑当前的状态表示
s
t
s_t
st 和 动作
a
t
a_t
at 来预测未来的场景表现形式
s
^
t
+
1
\hat{s}_{t+1}
s^t+1
使用L2损失来加强预测的潜在表示与从真实视觉观察
I
t
+
1
I_{t+1}
It+1 中提取的场景表示
s
t
+
1
s_{t+1}
st+1 相似。
3D-Aware Scene Representation Learning
NeRF 公式回顾
3D point x ∈
R
3
R^3
R3
a viewing direction unit vector d ∈
R
3
R^3
R3 from a camera
rendering function
f
N
e
R
F
(
x
,
d
)
=
(
σ
,
c
)
f_{NeRF}(x, d) = (σ, c)
fNeRF(x,d)=(σ,c)
r(h) = o + hd is the camera ray with its origin o ∈
R
3
R^3
R3 and unit direction vector d ∈
R
3
R^3
R3
C( r) =
∫
h
n
e
a
r
h
f
a
r
T
(
h
)
σ
(
h
)
c
(
h
)
d
h
∫^{h_{far}}_{h_{near}} T (h)σ(h)c(h)dh
∫hnearhfarT(h)σ(h)c(h)dh
T
(
h
)
=
e
x
p
(
−
∫
h
n
e
a
r
h
σ
(
s
)
d
s
)
T (h) = exp(− ∫^h_{h_{near}} σ(s)ds)
T(h)=exp(−∫hnearhσ(s)ds)

Neural Radiance Field for Dynamic Scenes
NeRF的一个关键限制是它假设场景是静态的,对于动态场景,它必须为每个时间步学习一个单独的辐射场,这严重限制了NeRF用于规划和控制的能力,因为它无法处理具有不同初始状态或输入动作序列的动态场景
为了使
f
N
e
R
F
f_{NeRF}
fNeRF 能够对动态场景建模,学习一个编码函数
f
e
n
c
f_{enc}
fenc,它将每个时间步的视觉观察映射到一个特征表示 s,并学习了基于 s 的体积亮度场解码函数。让
{
I
t
}
\{I_t\}
{It} 表示从一个或多个摄像机视点捕获时间 t 处3D场景的2D图像集。
从第 i 个视点拍摄的图像表示为
I
t
i
I^i_t
Iti ,使用 ResNet-18 为每张图像提取一个特征向量。将 ResNet-18 在池化层之前的输出发送到全连接层,得到 256维的图像特征
v
t
i
v^i_t
vti。该图像特征与相应的摄像机视点信息(通过将摄像机视点矩阵扁平化得到的16维向量)连接,使用小型多层感知器(MLP)进行处理,生成最终的图像特征
对多个摄像机视点的图像特征进行平均,然后使用另一个小MLP进行编码,并规范化以获得单元 L2 范数,从而生成时刻 t 的场景表示
s
t
s_t
st
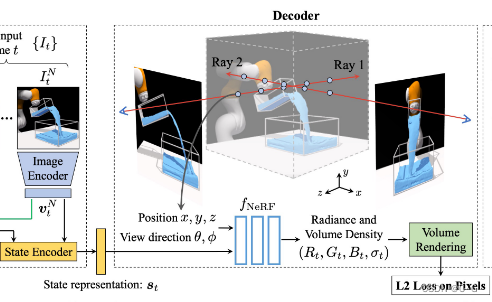
给定三维点 x、观看方向单位向量 d 和 场景表示
s
t
s_t
st,学习函数
f
d
e
c
(
x
,
d
,
s
t
)
=
(
σ
t
,
c
t
)
f_{dec}(x, d, s_t) = (σ_t, c_t)
fdec(x,d,st)=(σt,ct) 来预测密度
σ
t
σ_t
σt 和RGB颜色
c
t
c_t
ct 所代表的亮度场。
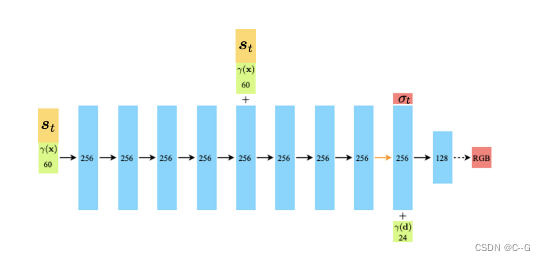
利用沿相机光线的集成信息从输入视点渲染图像像素的颜色,然后利用公式式1计算图像重建损失
在每次训练迭代中,我们从不同的视点渲染两张图像,以计算更精确的梯度更新。
f
d
e
c
f_{dec}
fdec 依赖于场景表示
s
t
s_t
st,迫使它对场景的3D内容进行编码,以支持从不同的相机姿势进行渲染。
Time Contrastive Learning
为了使图像编码器是viewpoint invariant(不管视点如何,都能起作用)的,使用多视图 Time Contrastive Loss(TCN)对每个图像
v
t
i
v^i_t
vti 的特征表示进行正则化
TCN损失鼓励同一时间步不同视点图像的特征相似,而排斥不同时间步图像的特征不相似。
给定时间步长 t,随机选择一个图像
I
t
i
I^i_t
Iti 作为锚点,使用图像编码器提取其图像特征
v
t
i
v^i_t
vti ,然后从同一时间步但不同的摄像机视点随机选取一幅正图像
I
t
i
′
I^{i'}_t
Iti′ 和从不同时间步但相同的摄像机视点随机选取一幅负图像
I
t
′
i
I^{i}_{t'}
It′i,提取他们的图像特征
v
t
i
′
和
v
t
′
i
v^{i'}_t 和 v^i_{t'}
vti′和vt′i
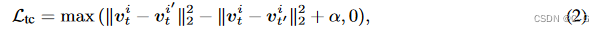
其中α是一个超参数,表示正负对之间的空白
Learning the Predictive Model
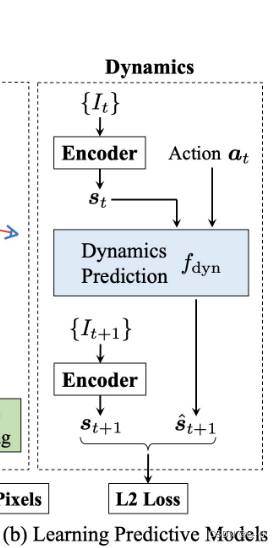
在得到 潜在状态表示 s 后,使用监督学习来估计 forward dynamics model(MLP网络),
s
^
t
+
1
=
f
d
y
n
(
s
t
,
a
t
)
\hat{s}_{t+1} = f_{dyn}(s_t, a_t)
s^t+1=fdyn(st,at). 给定
s
t
s_t
st 和一系列动作
{
a
t
,
a
t
+
1
,
…
}
\{a_t, a_{t+1},…\}
{at,at+1,…},通过迭代地向 forward dynamics model 中输入动作来预测未来的 H 步。
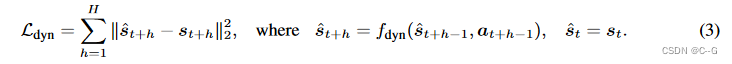
将最终损失定义为 图像重建损失、时间对比损失 和 动态预测损失的组合:
L
=
L
r
e
c
+
L
t
c
+
L
d
y
n
L = L_{rec} + L_{tc} + L_{dyn}
L=Lrec+Ltc+Ldyn 。
首先通过最小化 $L_{rec} 和
L
t
c
L_{tc}
Ltc,使用随机梯度下降(SGD)训练编码器
f
e
n
c
f_{enc}
fenc 和 解码器
f
d
e
c
f_{dec}
fdec ,从而确保学习到的场景表示 s 编码3D内容并具有 viewpoint-invariant.。
然后冻结编码器,利用SGD最小化
L
d
y
n
L_{dyn}
Ldyn 来训练动态模型
f
d
y
n
f_{dyn}
fdyn
Visuomotor Control

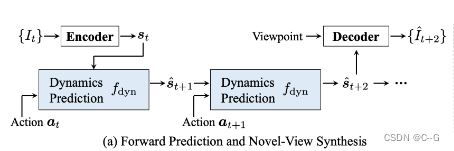
Forward prediction and viewpoint extrapolation
(a)首先将 t 时刻的输入图像输入到编码器中,得到场景表示
s
t
s_t
st,然后将
s
t
s_t
st 和相应的动作序列作为输入,迭代预测未来。该解码器综合了以预测状态表示和输入视点为条件的视觉观察。
(b)提出了一种基于优化的自动解码推理框架来实现外推观点的概化。给定一个从训练分布之外的视点获取的输入图像,编码器首先预测场景表示
s
t
s_t
st ,然后解码器从
s
t
s_t
st 重建观测
I
^
t
\hat{I}_t
I^t ,再从
I
t
I_t
It 重建摄像机的视点。计算
I
t
I_t
It 和
I
^
t
\hat{I}_t
I^t之间的 L2 距离,并通过解码器反向传播梯度来更新
s
t
s_t
st。更新过程重复 K次,从而得到更精确的底层3D场景
s
t
s_t
st 。
Online Planning for Closed-Loop Control
当给定目标图像
I
g
o
a
l
I^{goal}
Igoal 及其相关的摄像机姿态时,通过编码器
f
e
n
c
f_{enc}
fenc 将其输入得到目标配置
s
g
o
a
l
s^{goal}
sgoal 的状态表示。
使用相同的方法来计算当前场景
s
1
s_1
s1 的状态表示
在线规划问题的目标是找到一个行动序列
a
1
,
…
,
a
T
−
1
a_1,…, a_{T−1}
a1,…,aT−1 ,使预测的未来表示 和 在时间 T 处的目标表示 距离最小
给定一系列动作,模型迭代地预测一系列潜在状态表示,通过模型预测控制(MPC)的在线规划,该潜在空间 dynamics model 可用于下游闭环控制任务。

许多现有的现成的基于模型的RL方法可以用来解决MPC问题,如:random shooting,gradient-based trajectory optimization,cross-entropy method,and model-predictive path integral (MPPI) planners,其中 MPPI 的性能最好,在实验中指定动作空间为手臂末端执行器的位置和方向,然后,利用逆运动学计算手臂的关节角
Auto-Decoder for Viewpoint Extrapolation
当从训练分布之外的摄像机姿态捕获测试时间视觉观察时,端到端视觉运动 agents 的性能会显著下降。
卷积图像编码器也有同样的问题,因为它对相机姿态的变化不是等变的,这意味着它很难推广到非分布的相机视图。
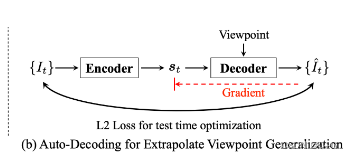
如上图b所示,当遇到来自训练分布之外的视点的图像,其像素分布与训练模型的像素分布有很大差异时,将其通过编码器
f
e
n
c
f_{enc}
fenc 将给一个场景表示
s
t
s_t
st 的 amortized estimation。由于训练过程中从未遇到过该视点,因此解码后的图像很有可能与真实图像不一致
在测试时通过应用基于优化的推理(也称为自动解码)框架来解决这个问题,该框架通过体积渲染器和神经隐式表示反向传播到状态估计。这是受到渲染函数
f
d
e
c
(
x
,
d
,
s
t
)
=
(
σ
t
,
c
t
)
f_{dec}(x, d, s_t) = (σ_t, c_t)
fdec(x,d,st)=(σt,ct) 是视点等变量的启发,其中输出只依赖于状态表示
s
t
s_t
st、位置 x 和光线方向 d,这意味着输出对相机沿相机光线的位置是不变的,也就是说,即使沿着相机光线移动相机或近或远,
f
d
e
c
f_{dec}
fdec 仍然倾向于生成相同的结果。利用这一特性,计算输入图像与重建图像
L
a
d
=
‖
I
t
−
I
^
t
‖
2
2
L_{ad} =‖ I_t− \hat{I}_t ‖^2_2
Lad=‖It−I^t‖22 之间的 L2 距离,然后使用随机梯度下降更新场景表示
s
t
s_t
st。重复这个更新过程 K 次,以获得底层3D场景的状态表示。注意,此更新只更改场景表示,同时保持解码器中的参数不变。将得到的表示形式作为公式4中的
s
g
o
a
l
s^{goal}
sgoal 来解决在线规划问题。

自动解码测试时间优化的定性结果。
根据上图图b所示的管道,如果输入图像
I
t
I_t
It 在训练分布之外,如左列所示,编码器将无法生成最精确的状态表示。当将预测的状态嵌入
s
t
s_t
st 和与输入相同的视点传递给解码器时,生成的图像与下面的场景不匹配,如第二列所示。然后计算生成的图像和真实观测之间像素的L2距离,反向传播梯度直到状态表示,并使用SGD更新
s
t
s_t
st 。译码器的平移等方差特性使其能够有效优化潜在表示,使其更好地反映场景中的3D内容。优化后,生成的视觉观测值更接近地面真实值,如第三列所示。相反,使用基于cnn的解码器的普通自动编码器即使进行了测试时自动解码优化也不能捕获底层场景,如右图所示。
details
使用模型预测路径积分(MPPI)来解决MPC问题。
MPPI是一个基于采样的、无梯度的优化器,它在采样动作轨迹时考虑时间步骤之间的时间协调。
在时间 t 点,算法首先基于点的当前动作对 M 个动作序列进行采样,
a
t
,
.
.
.
,
a
T
−
1
v
i
a
a
^
h
k
=
a
h
+
n
h
k
,
k
∈
{
1
,
…
,
M
}
,
h
∈
{
t
,
…
,
T
−
1
}
a_t,...,a_{T−1} via \hat{a}^k_h = a_h + n^k_h, k∈\{1,…, M\}, h∈\{t,…, T−1\}
at,...,aT−1viaa^hk=ah+nhk,k∈{1,…,M},h∈{t,…,T−1}。每个噪声样本
n
h
k
n^k_h
nhk 表示第 k 个轨迹第 h 个时间步处的噪声值,使用滤波系数 β 生成如下:
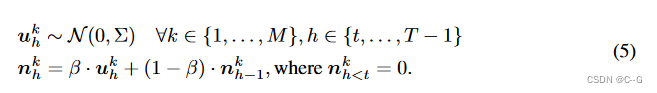
然后,在GPU上使用学习到的模型并roll them out,以推导
s
^
T
k
\hat{s}^k_T
s^Tk, k∈{1,…, M},然后根据奖励对轨迹重新加权,使用奖励加权因子 γ 更新动作序列:
a
h
=
(
∑
k
=
1
M
e
x
p
(
γ
⋅
R
k
)
⋅
a
^
h
k
)
/
(
∑
k
=
1
M
e
x
p
(
γ
⋅
R
k
)
)
,
h
∈
{
t
,,
T
−
1
}
a_h =(∑^M_{k=1} exp (γ·R^k)·\hat{a}^k_h)/(∑^M_{k=1} exp (γ·R^k)), h∈\{t,, T−1\}
ah=(∑k=1Mexp(γ⋅Rk)⋅a^hk)/(∑k=1Mexp(γ⋅Rk)),h∈{t,,T−1},其中
R
k
=
−
‖
s
^
T
k
−
s
g
o
a
l
‖
2
2
R^k =−‖\hat{s}^k_T−s^{goal}‖^2_2
Rk=−‖s^Tk−sgoal‖22 。这个过程在 L 迭代中重复,在这个迭代中选择最佳动作序列。
自解码测试时间优化的更新迭代次数K为500。将MPPI优化过程中采样轨迹M设置为1000个。更新操作序列的迭代次数 L 对于第一次步骤设置为100,对于后续控制步骤设置为10,以在效率和有效性之间保持更好的权衡。奖励权重因子 γ 设为 50,过滤系数 β 设为 0.7。对于 FluidPour 和 FluidShake,控制水平 T 都设置为 80。所有比较方法的超参数都是相同的。
效果
对于编码器和解码器模型,使用初始学习率为
5
e
−
4
5e^{−4}
5e−4 的 adam 优化器,并在所有实验中降低到
5
e
−
5
5e^{−5}
5e−5 。批量大小为2个。解码器中的超参数与原始NeRF模型相同,只是在这里,物体和摄像机之间的远近距离不同。在 FluidPour 环境中,near = 2.0, far = 9.5。在FluidShake环境中,near = 2.0, far = 7.0。在RigidStack环境中,near = 2.0和far = 7.0。在FluidPour环境中,near = 2.0, far = 6.0。
在 FluidPour 环境中,生成了1,000个训练轨迹。每条轨迹有300帧,有20个围绕物体采样的摄像头视图,距离世界原点固定。控制任务的动作空间是杯子的位置和倾斜角度,这是在构建训练集时随机生成的。
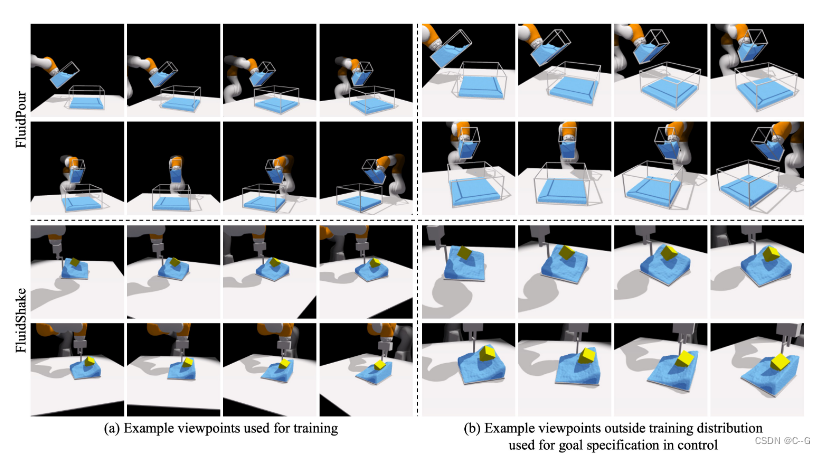
用于训练的视点与随后的视点外推实验的比较。
(a)展示了模型在训练中使用的一些示例图像。对于这两种环境,摄像机都是从固定的距离放置,并面向世界原点。
(b)为了评估模型的视点外推能力,即处理来自训练分布之外视点的视觉观察,生成另一组更近、更高、更向下的视点。
从图中可以明显看出,使用像素差测量时,训练中使用的视点图像与用于视点外推的图像有很大的不同。因此,建立一个可以直接在3D上推理的模型,以提供所需的外推泛化能力是非常必要的。虽然模型在训练过程中可以获得来自多个摄像头的视觉观察,但在执行下游控制任务时,它只能从一个摄像头观察环境。
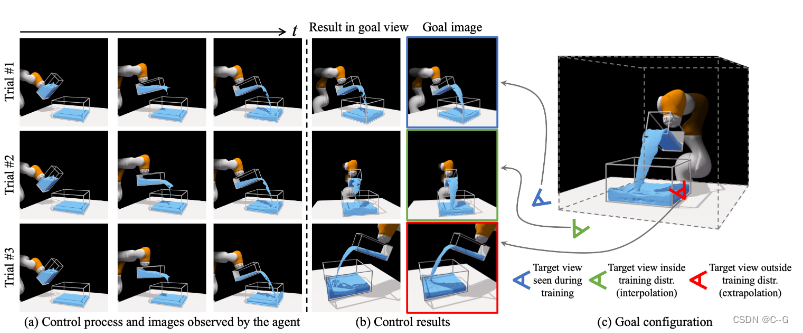
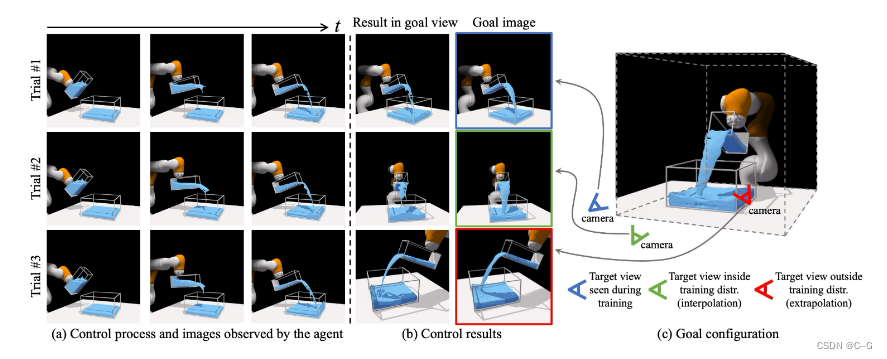
对三种测试场景的定性控制结果。
右边的图像显示了要实现的目标状态。
左边的三列显示控制过程,它们也是 agent 的输入图像。
第四列是来自与目标图像相同视点的控制结果。
试验1使用与 agent 不同的视角指定目标,但在训练过程中遇到过。
试验2使用的目标视图是训练视点的插值。
试验3使用训练分布之外的外推观点。
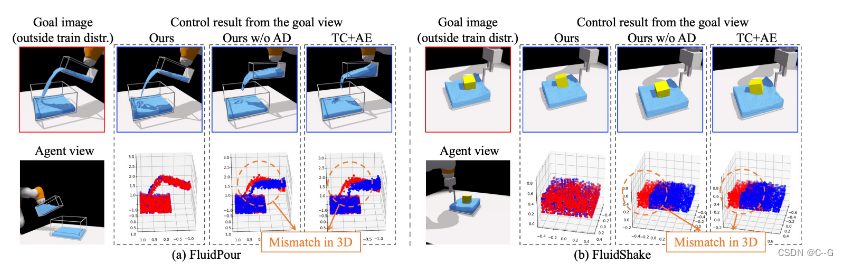
与对照任务的 baseline 方法之间的定性比较。
展示了在 FluidPour 和 FluidShake 环境下的闭环控制结果。
目标图像的视点(每个块的左上角图像)在训练分布之外,与agent观察到的视点(每个块的左下角图像)不同。
最终控制结果比不执行自动解码测试时间优化的变体(无AD)和性能最好的基线(TC+AE)要好得多,这两者都未能完成任务,当在流体和浮动立方体的3D点空间中测量时,它们的控制结果(蓝色点)显示出明显偏离目标配置(红色点)。
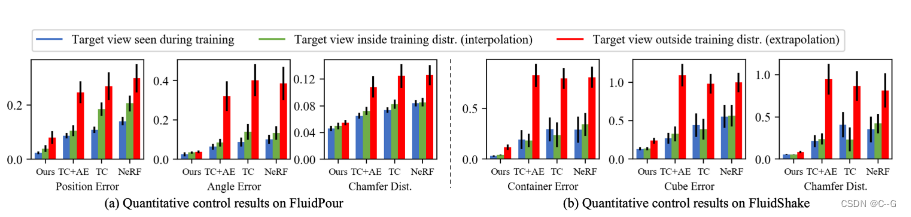
与 FluidPour 和 FluidShake 的 baselines 之间的定量比较。在每种环境中,使用三种不同的评价指标在三种设置下的结果进行比较
(1)训练时看到的目标图像视图
(2)训练时看不到的目标图像视图在训练分布内(插值)
(3)训练分布外(外推)。
柱的高度表示平均值,误差柱表示标准误差。在所有测试设置下
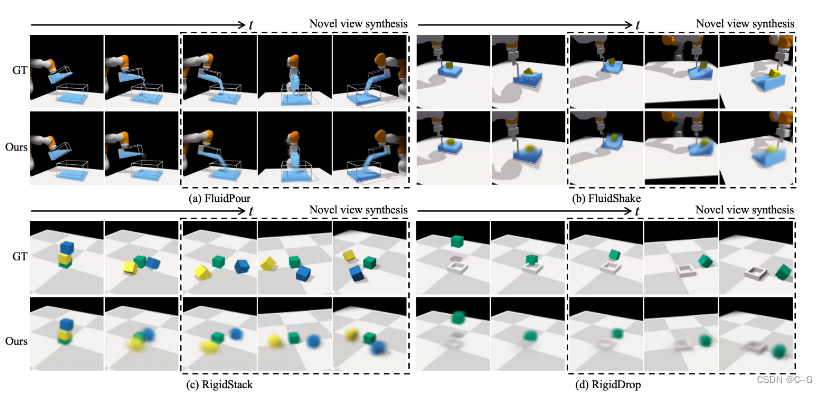
四种环境的前瞻性预测和新视角综合。
给定场景表示和输入动作序列,动态模型预测后续的潜在场景表示,并将其作为解码器模型的输入,根据不同视点重构相应的视觉观察。
在每个块中,基于从左到右的开环未来动态预测渲染图像。
虚线框中的图像将模型在最后时间步中的新视图合成结果与三个不同视点的地面真相进行比较。