1.Sampler类
Sampler是所有采样类的基类。采样类中最重要的是take_sample函数,采样类的schedule函数调用之后,它的take_sample函数将会被一个专门的线程每1秒定时调用。
Sampler类的定义:
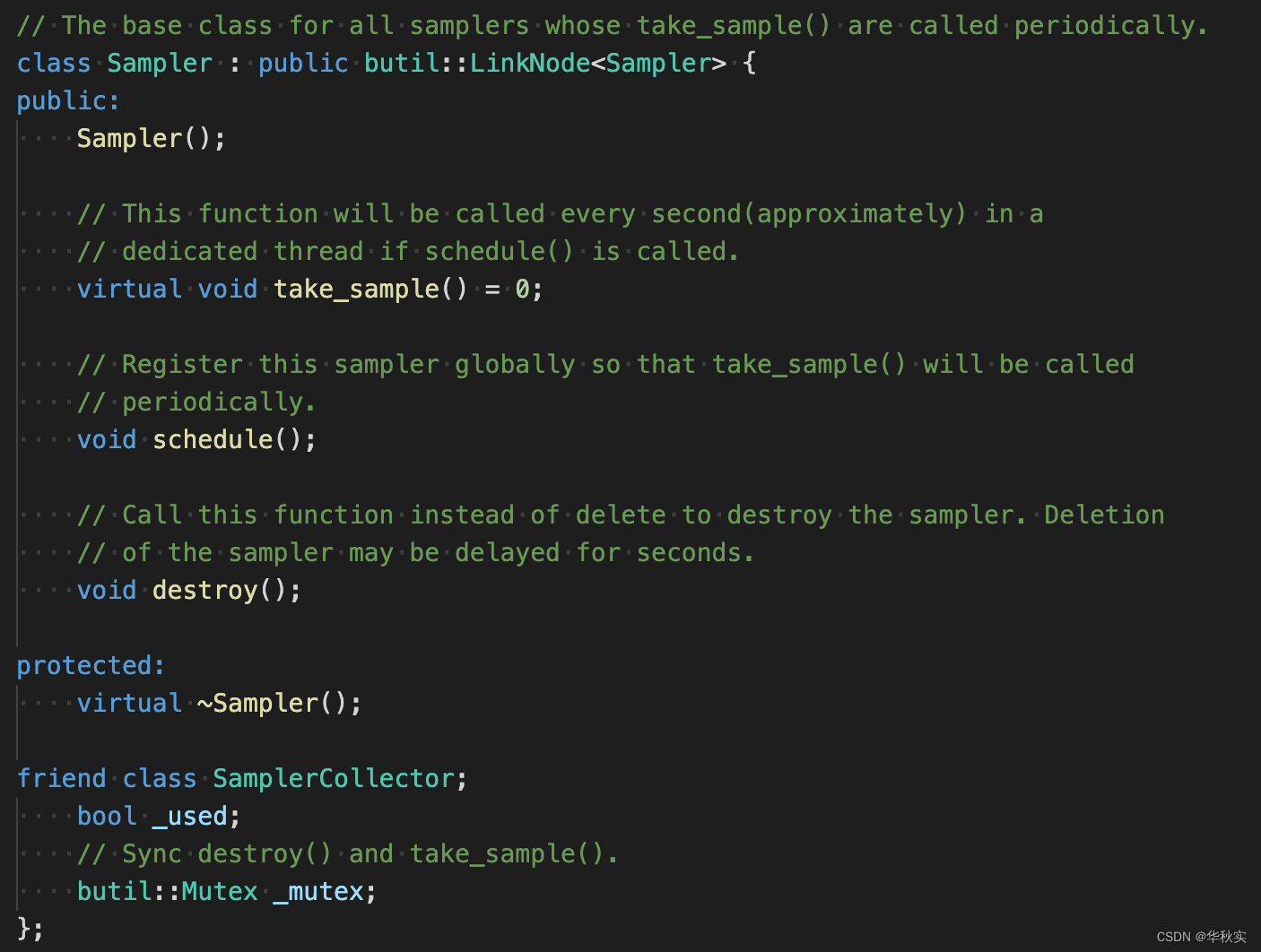
Sampler是一个纯虚类,take_sample是纯虚函数需要子类实现。
Sampler继承自LinkNode,即拥有了previous_和next_指针,可以作为双向链表的节点。
Sampler有两个成员变量,一个是_used表示当前采样类是否生效;一个是_mutex保护_used。
构造函数、析构函数和destroy函数
默认_used设为true。
如果采样类不再使用,则调用其destroy函数,设置_used为false,实现延迟删除,至于从哪里删除,后面会讲到。

schedule函数:

注册当前采样类的地址到全局单例SamplerCollector中,后面讲到SamplerCollector时再详细介绍内部实现。
2.Sample类
定义:
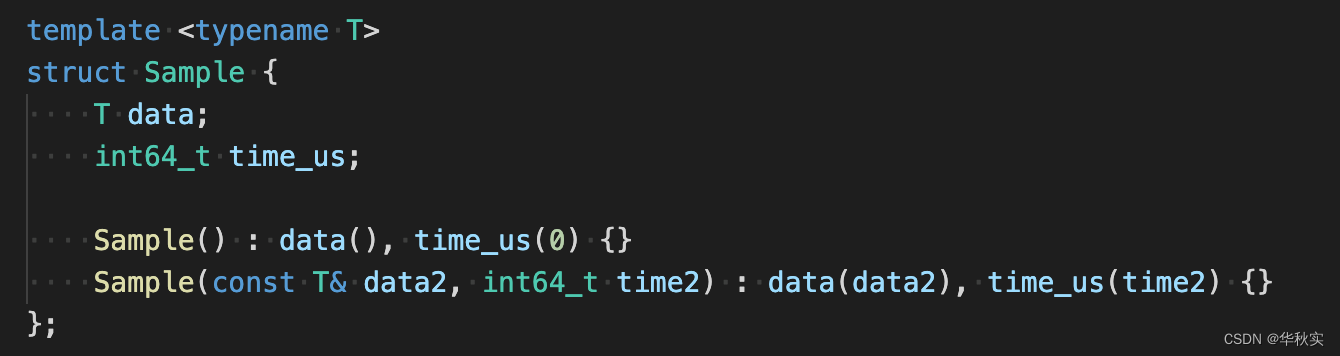
这个类很简单,保存了bvar的类型T的值data,和时间time_us。它用于保存一次采样的结果和采样时的时间。
3.SamplerCollector类
定义:
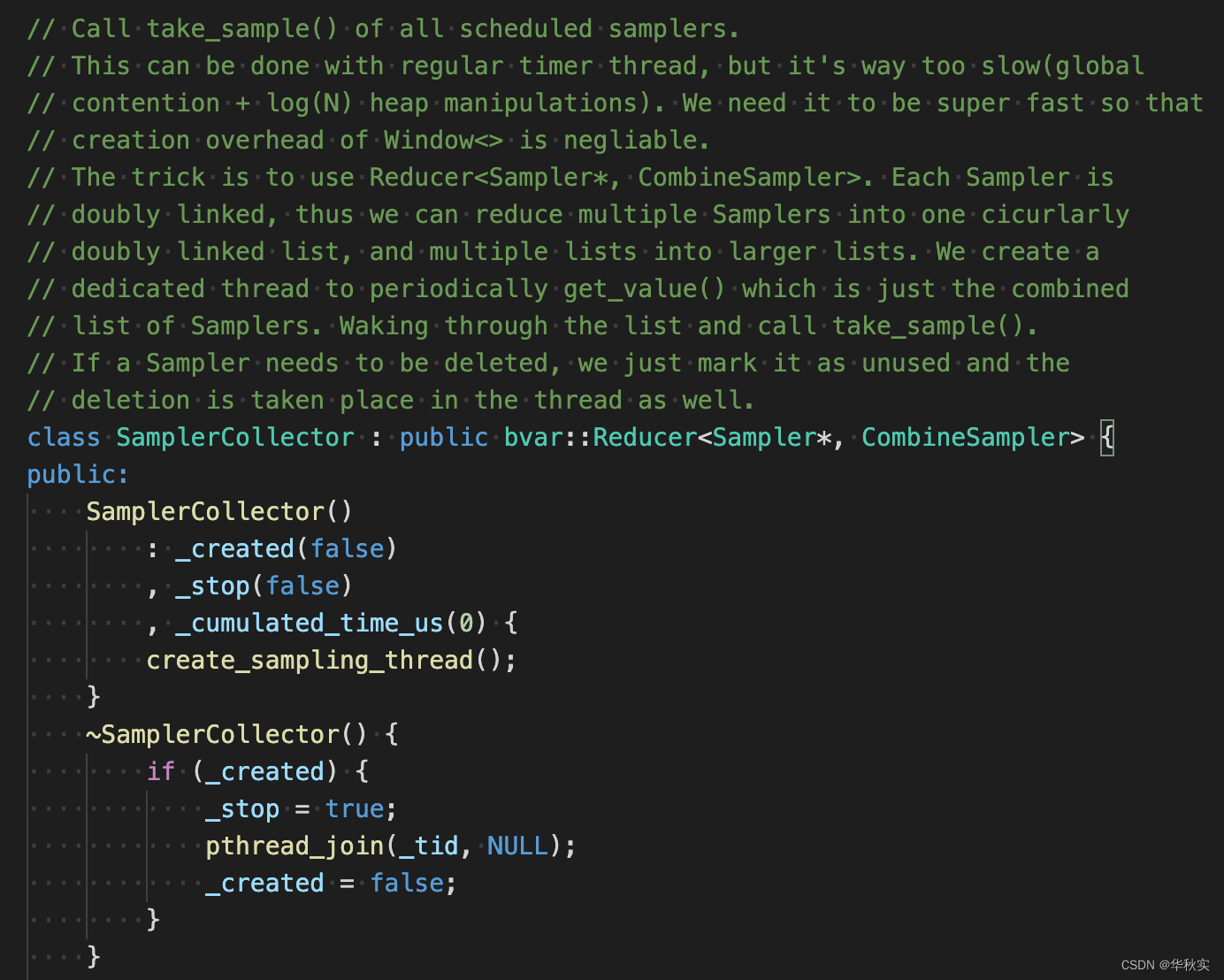
上面的注释可以帮助理解为什么SamplerCollector要设计成继承自Reducer。正常情况我们一般的实现是这样,用一个容器C保存所有注册的采样类和一个mutex M保护,设置定时线程来定期采样。但是这个性能不好,每次开始采样前都要用M加锁保护,以至于创建Window<>(创建Window<>是会创建sampler类、并注册到SamplerCollector中)需要等锁释放。如果想让创建Window<>的开销可以忽略不计,还需要更好的方案。
这里就提供了一个更好的方案,就是继承自Reducer<Sampler*, CombineSampler>。这样SamplerCollector就是一个bvar,保存的是Sampler*,累加器是CombineSampler,看一下CombineSampler的实现:
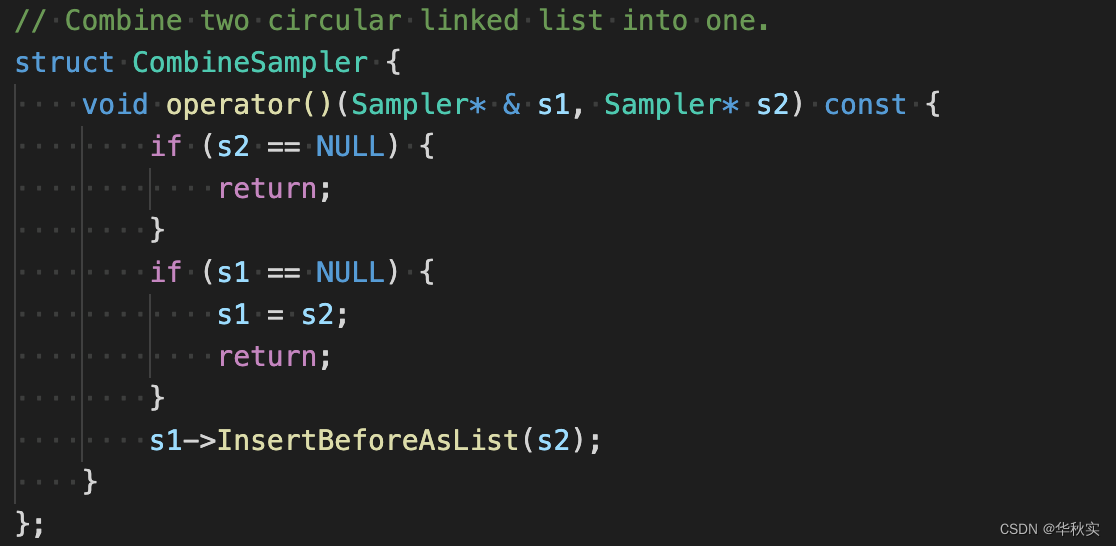
前面说了Sampler*是可以作为双向链表的节点的。CombineSampler的两个参数是2个双向链表,它的操作就是把两个双向链表连接起来。
综合上面的信息,SamplerCollector继承自Reducer<Sampler*, CombineSampler>之后,调用operator<<函数可以轻易的添加Sampler到stl数据中,这个过程是没有锁的,就解决了前面说的问题:想让创建Window<>的开销可以忽略不计;调用get_value函数可以通过累加器CombineSampler将所有的Sampler组成一个双向链表。
成员变量
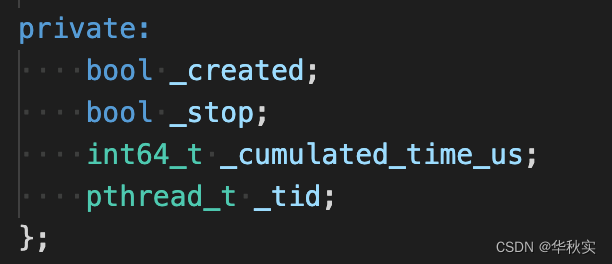
_created:是否创建了采样线程
_stop:是否需要退出采样线程中的循环
_cumulated_time_us:采样线程中遍历所有的Sampler*进行采样花费的时间的总和
_tid:采样线程id
函数create_sampling_thread
SamplerCollector类的构造函数中就调用了函数create_sampling_thread。
实现:
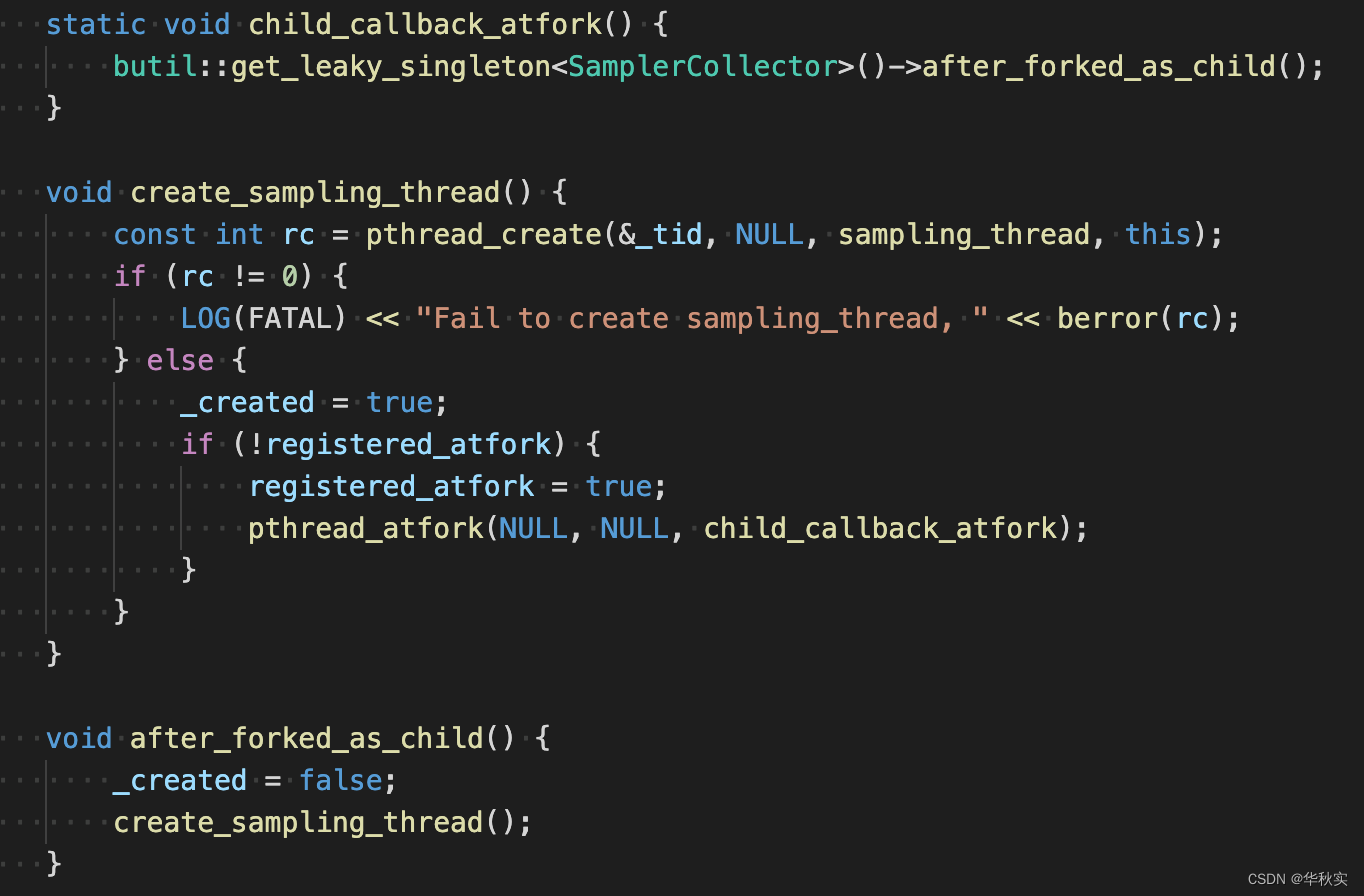
(1)创建采样线程执行函数sampling_thread
(2)如果采样线程创建成功,则通过pthread_atfork注册当fork子进程时在子进程上下文中fork函数返回之前调用child_callback_atfork函数
A)child_callback_atfork函数中创建全局SamplerCollector单例,并调用其after_forked_as_child函数
B)after_forked_as_child中重置_created为false,并调用create_sampling_thread以实现在子进程中创建采样线程。
采样线程执行run函数
采样线程首先调用的函数sampling_thread,它的实现很简单就是调用SamplerCollector::run函数:
所以看run函数:
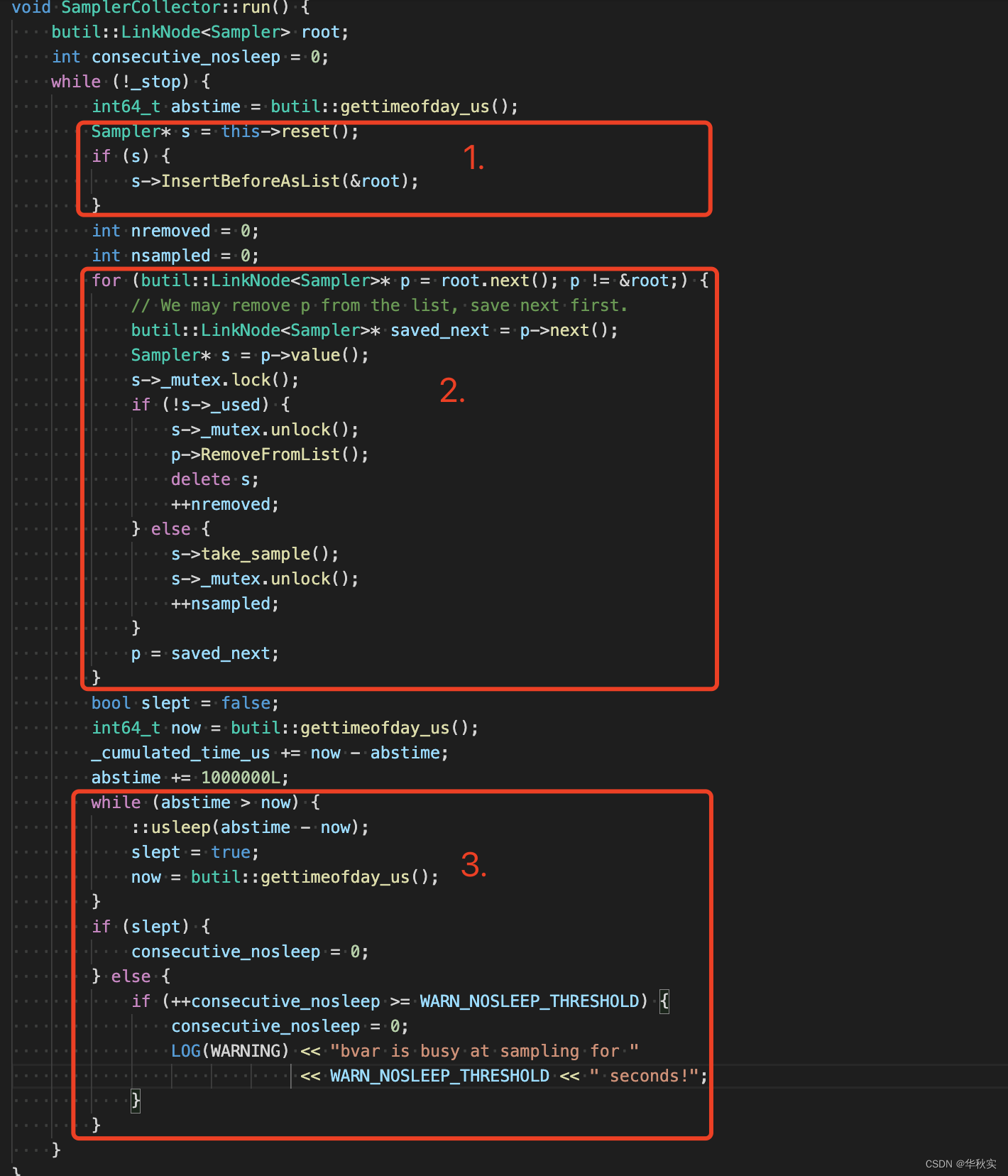
1.获得所有的Sampler
1)调用SamplerCollector::reset函数,Reducer::reset函数中执行了_combiner.reset_all_agents,通过前文知道它把所有stl保存的Sampler*连接成一个双向链表s返回,原来的保存的地方重置为null。
2)reset函数返回的双向链表s和root连接到一起。即root是之前就已经获得的所有的Sampler构造的双向链表,s是最新加入的Sampler构造的双向链表。
2.遍历所有的Sampler
1)遍历root中的所有Sampler,判断是否被destroy(_used字段),如果是,则从root中删除、并delete,否则进行2)
2)调用Sampler::take_sample进行采样操作,take_sample是Sampler具体子类实现的
3.sleep
1)如果上述全过程花费的时间不超过1s,则sleep多余的时间
2)如果花费超过1s,则consecutive_nosleep+1,consecutive_nosleep超过WARN_NOSLEEP_THRESHOLD(默认值2)时打印log
4.ReducerSampler类
ReducerSampler是Sampler类的子类,定义如下:

继承自Sampler,有4个模板参数:
R:一般就是Reducer类或Reducer子类
T、Op、InvOp:Reducer类的三个模板参数
成员变量:
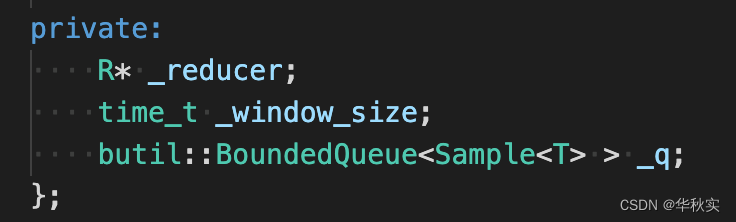
_reducer:保存传入的R类型对象指针
_window_size:窗口大小
_q:保存所有Sample的有界队列(即循环队列);当容量全部有值、再加入新增时将替换最早加入的值。
构造函数
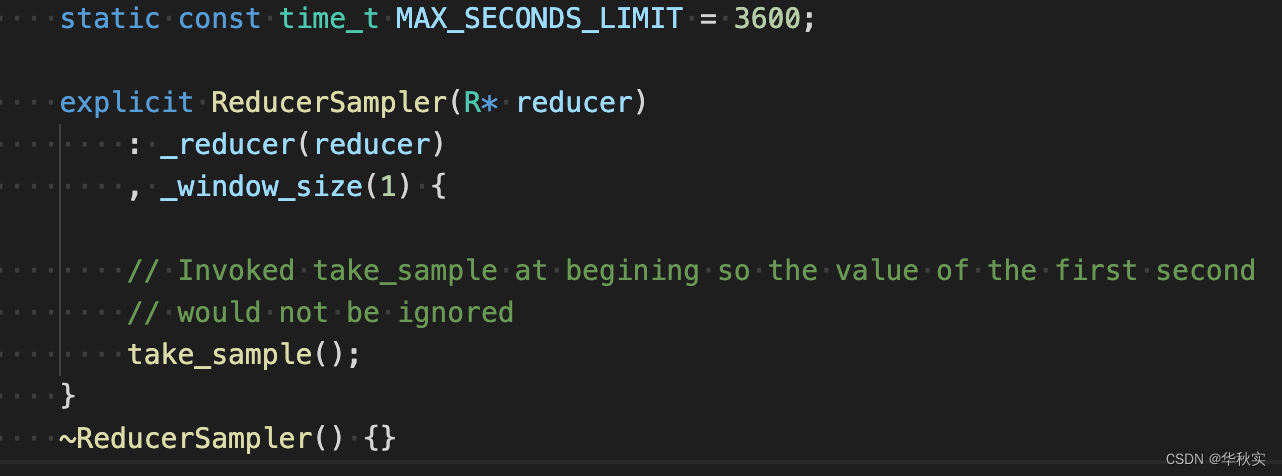
初始化_reducer,设置_window_size为1;调用take_sample。
函数take_sample
函数是具体的采样操作。
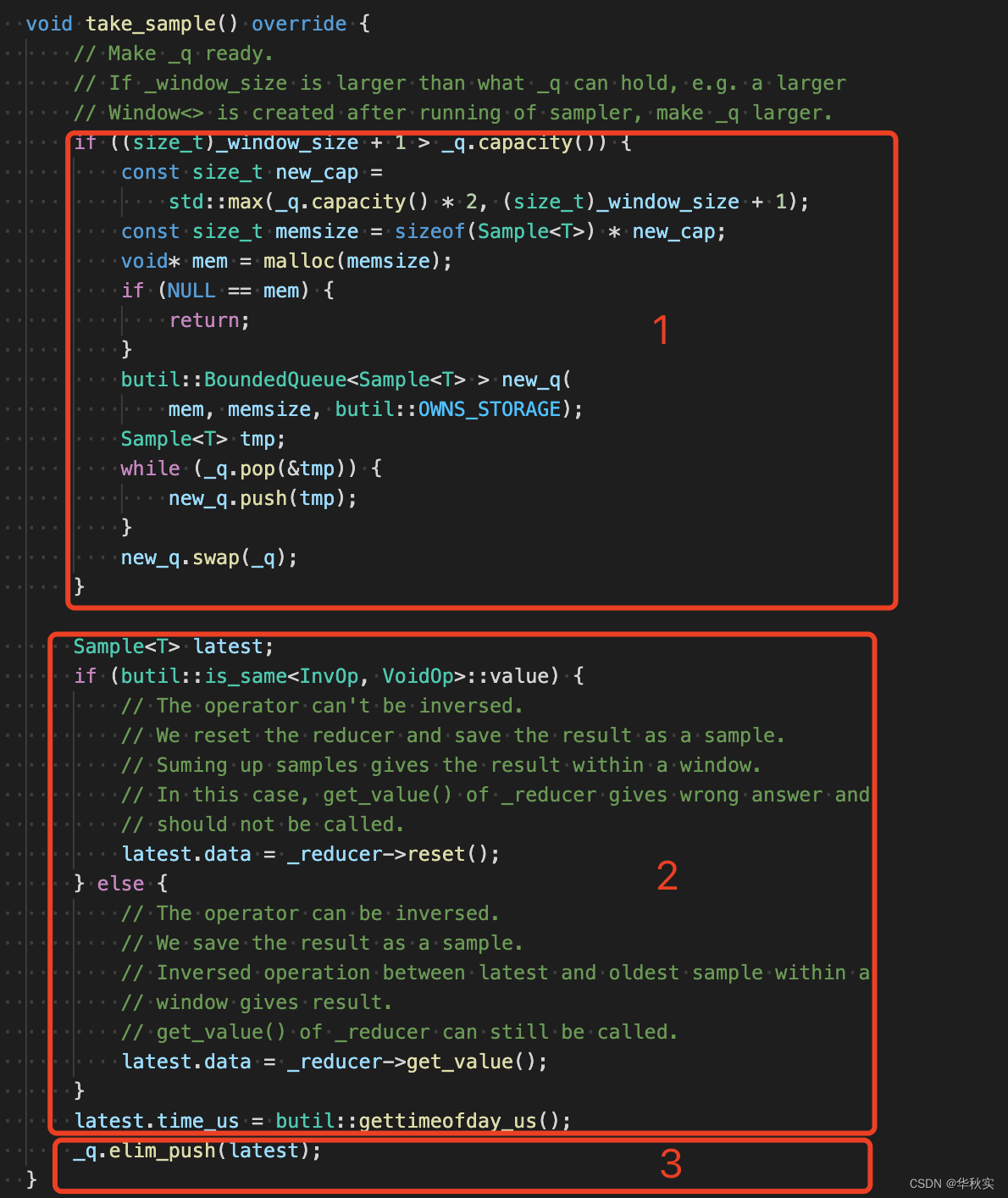
1._q容量不足_window_size,则扩容量
2.获得_reducer最新值
1)如果没有反向op,例如Maxer、Miner,则获得当前的最新值返回、并重置原保存的值
2)如果有反向op,例如Adder,则获得当前的最新值返回即可,之后需要窗口内的值时可以通过反向op操作来得到
3)无论有没有反向op都可以通过1)来实现,但是对于有反向op的,用2)效率会更高
3.加入到_q中
1)保存当前时间(采样时间)到time_us
2)采样结果Sample保存到_q中
函数get_value
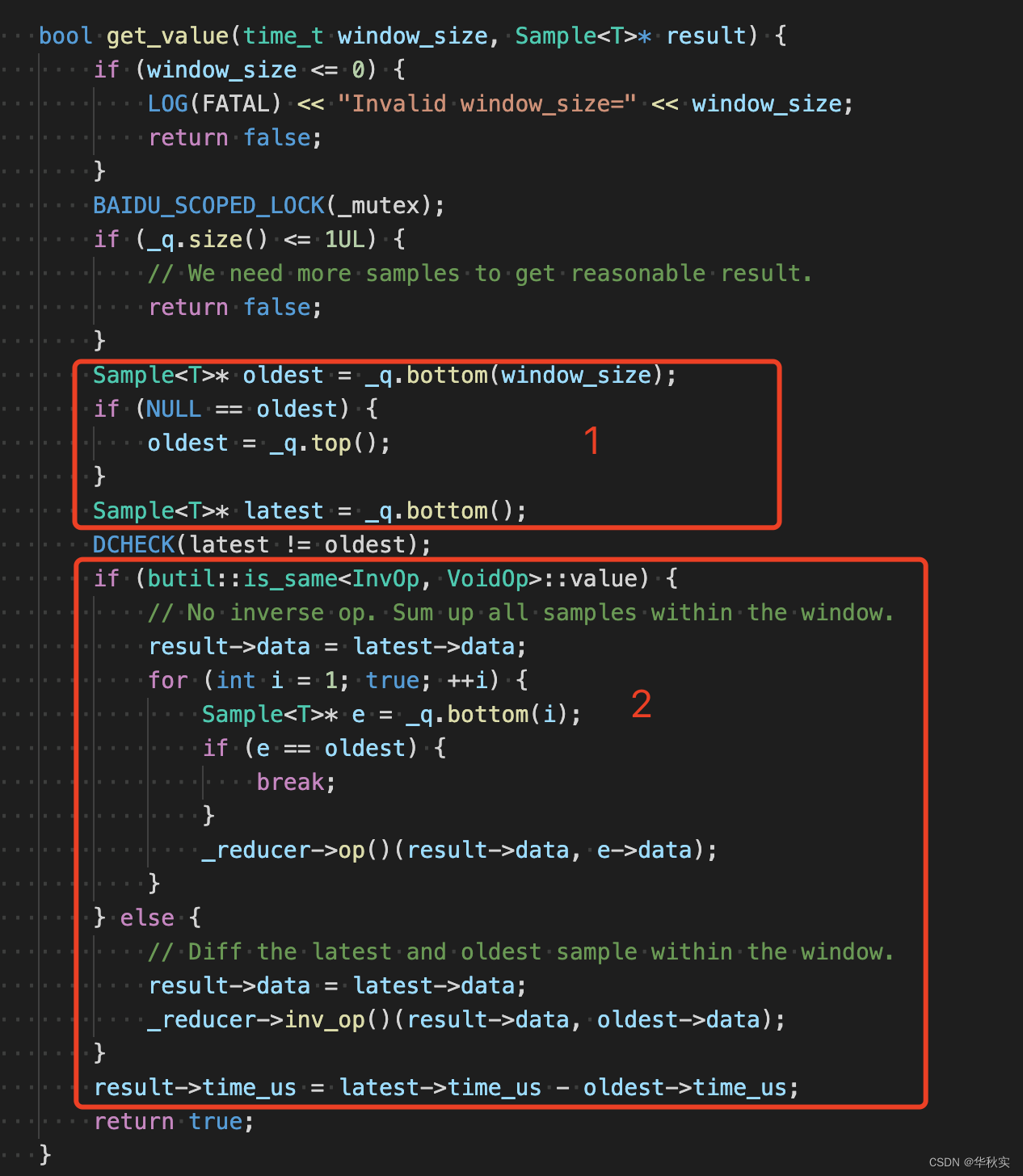
1.获得窗口前后的采样值
1)最新采样的值保存到latest
2)从现在往过去数第window_size个采样结果保存到oldest;如果全部采样结果就不足window_size个,则保存最老的采样结果到oldest
3)上述两个值作为窗口前后的采样值
2.根据上述值计算窗口内的值
1)如果没有反向op,那么就老老实实地从oldest依次到latest,依次执行op操作(op例如取最大值)
2)如果有反向op,那么就可以根据inv_op、oldest、latest快速计算得到(例如对于Adder,latest - oldest就是窗口类的值)
3)oldest、latest采样时间间隔保存到result->time_us
使用ReducerSampler的地方
ReducerSampler中有如下定义:
typedef detail::ReducerSampler<Reducer, T, Op, InvOp> sampler_type;
在Reducer::get_sampler首次被调用时将创建ReducerSampler对象(传入this指针)、并加入到全局单例SamplerCollector中:

那么Reducer::get_sampler什么时候被调用呢,下面的Window<>创建的时候。下面会介绍到。
5.WindowBase类
定义:
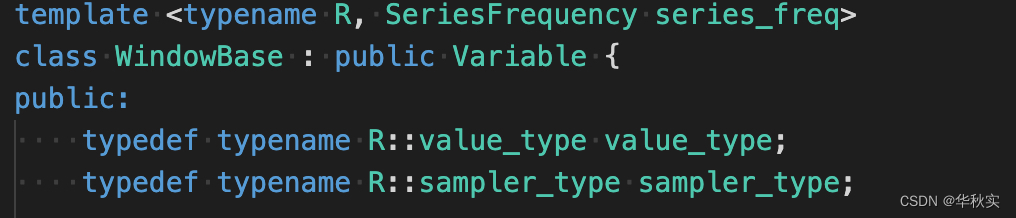
模板参数:
R:具体的bvar类型
SeriesFrequency:和SeriesSampler有关,我们这次不介绍这个。
成员变量:

_var:指针指向具体的bvar的对象
_window_size:窗口大小;根据前面我们知道,窗口是指采样点的窗口,虽然采样线程是每1s采样一次,但由于要遍历所有的Sampler的take_sample,所以对于每个Sampler而言不一定是每1s采样一次
_sampler:属于bvar对象_var的采样对象,弱引用
_series_sampler:我们这次不介绍SeriesSampler相关的。
构造函数
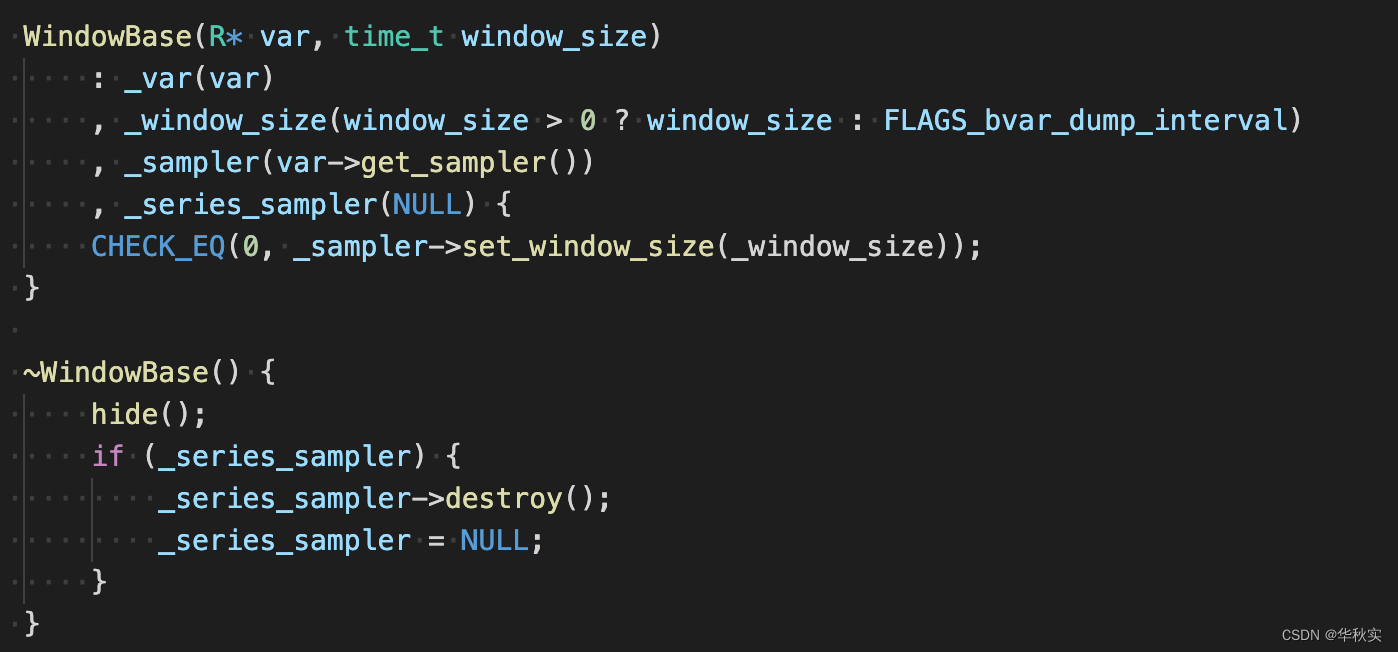
WindowBase类的构造函数需要传2个内容:bvar对象的指针和窗口大小。
_sampler赋值bvar对象的sampler指针,这里是弱引用,并修改_sampler的窗口大小。
get_span函数
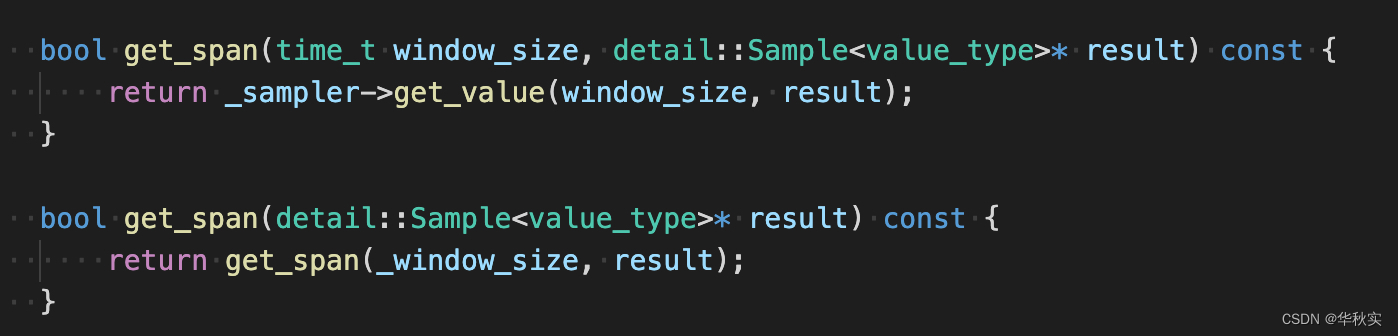
获得指定窗口大小的Sample对象值。
get_value函数
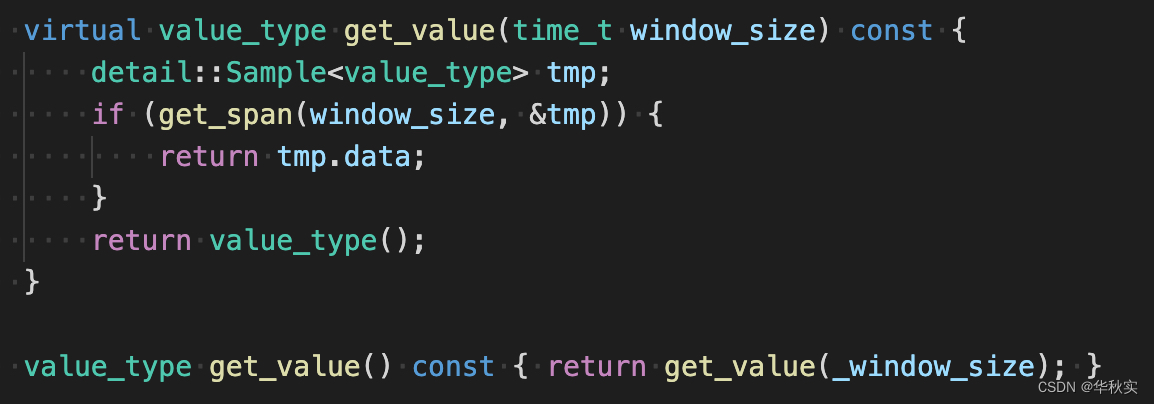
调用get_span获得指定窗口大小的Sample对象值,然后返回Sample.data,即具体的bvar存储的类型的值。
6.WindowBase子类
1.Window类继承自WindowBase,比较简单,不赘述
2.PerSecond类也继承自WindowBase,特别的,它override了get_value函数:

它在获得了Sample.data之后,又除了一下窗口首末真正的采样时间间隔,正如类名一样表示每秒的采样值。
7.最后
其他的一些类,例如LatencyRecorder(时延),PassiveStatus(get_value时调用指定函数对象获得value)都比较简单,就不赘述了。