Python介绍
Python诞生于1989年,圣诞节创始人是吉多·范罗苏姆。
特点:简单优雅,面向对象,免费开源,开发效率快,强大的库,标准库,第三方库。
基本语法
1.赋值语句
#变量赋值
str_name = "liujunwei" #变量名+表达式
str_name_1 = "liujunwei" + ",你好" #变量名+表达式1+表达式2
name = 1+3*4/5 #序列
2.del语句
# 删除变量名(删除以后就不存在了)
del name
3.if 语句
#判断函数
# 推荐练习(个人所得税、成绩表...)
if 真值表达式1:
语句块1
elif 真值表达式2:
语句块2
...
else:
语句块n
请注意真值表达式哪里,不要使用赋值符号 =
应该使用判断符号 ==、 !=、 <= 、>=、<、>
4.for循环语句
#for循环典型案例
#1.1+2+3+...N的计算
sum = 0
for i in range(101):
sum += i
print("1+2+3+...+100=",sum)
# 2.输出列表的每个元素
list_1 = ['张三','李四','王五']
for i in list_1:
print(i)
4.while循环语句
#while循环
#1.使用while循环计算1+3+5+99=?
sum = 0
i = 1
while(i<100):
sum += i
i += 2
print('1+3+5+...+99=',sum)
# 2.死循环
while True:
4.1循环下的语句
break语句:break终止程序,简单理解遇到break程序直接就直接终止。
continue语句:continue不再执行continue之后的语句,重新开始执行下一次循环。
数据类型
1.数据可变性
不可变数据类型: 数值型、字符串型、元组
可变数据类型: 列表、字典、集合
整数型int、浮点型float、字符串型str、布尔型bool
2.数据类型
整数型int:数据为整数
num_1 = int(1)
浮点型float:含有小数的整数
num_1 = float(1.2)
字符串str:
num_1 = str('西游记!')
布尔型(判断返回值True False)
num_1 = True
num_2 = False
2.1 格式化输出
格式化输出字符串%s
#打印字符串
num_3 = 100
print("西游记%s"%(num_3))
print(type('%s'%(num_3)))
格式化输出整数型%d
#格式化输出整数型%d
print("西游记%d周年"%(100))
格式化输出浮点型%f
#格式化输出浮点型%f
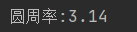
print("圆周率:%f"%(3.14))
输出结果

这里我们发现了小数点后面默认有6位
如果我们只需要让他有两位怎么办?
请看下面演示:
#指定打印浮点数的小数保留位数
print("圆周率:%.2f"%(3.14159))
输出结果:
其实我们只需要在(%后面加上.保留的位数)即可
例如我想保留5位:
#指定打印浮点数的小数保留位数(5位)
print("圆周率:%.5f"%(3.1415926))

输出结果

指定占位符的宽度
向左占位
#指定占位符的宽度
print("姓名:%5s年龄:%5d身高:%.2f"%('张金树',19,1.76))

输出结果:

向右占位
#指定占位符的宽度(向右占位)
print("姓名:%-5s年龄:%-5d身高:%.2f"%('张金树',19,1.76))
输出结果:

科学计数法
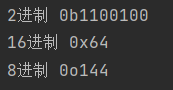
#科学计数法
print('2进制',bin(100))
print('16进制',hex(100))
print('8进制',oct(100))
输出结果:
3.列表,字典,集合,元组
1.1列表(list)
1.创建列表
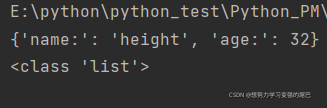
list = ["huarzil",32,3.14,True,["zhuangsan","lisi"],(32,29,30),{"name:":"height","age:":32}]
#2.创建空列表
emptylist = []
3.使用list创建列表
str_1 = '这是个列表'
list_2 = list(str_1)
print(type(list_2))
输出结果:
4.新增数据
list_test = []
print("原始list_test:",list_test)
列表增加数据
1.使用append()函数向列表尾部追加元素
list_test.append('这是我第一次追加的元素')
print(list_test)
list_test.append('这是我第二次追加的元素')
print(list_test)
list_test.append('由此我们可以知道,每次追加的元素都是在所有元素的尾部!')
print(list_test)
输出 结果:

2.使用extend()函数添加列表元素(一次性可以多个添加)
append_list = ["这是append函数"]
extend_list = ['刘备','诸葛亮','关羽','张飞']
append_list.extend(extend_list)
print(append_list)
输出结果:

3. insert()
insert(): 选定指定索引位置然后插入元素
insert(x,value):
x位置理解:
1.将value插入至列表的第x位之后
2.将value插入至列表索引值的x后
在刘备前面插入“三国演义”
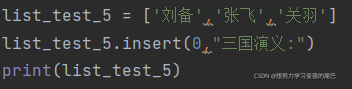
输出结果:

列表查找元素
1 使用print函数直接输出一个整列表

输出结果:

2 使用索引值访问某一个元素
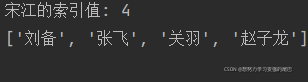
我们这里输出赵子龙:

输出结果:

3 使用 for 循环拿到所有元素的值
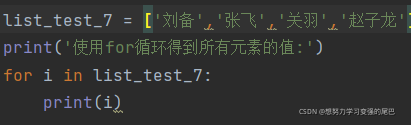
输出结果:
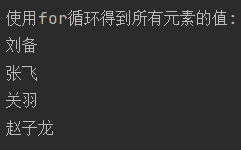
4 使用for循环和enumerte()得到索引值和元素

输出结果:
列表删除数据
1 知道元素的值,remove()删除指定某一个元素
删除宋江:

打印结果:
2 知道索引,不知道元素值使用del
删除宋江:
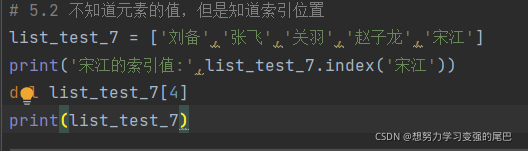
输出结果:
3 删除整个列表
直接:del 列表名字
列表更改数据
1.通过索引,重新赋值
#通过索引值,重新赋值
Xi_You_Ji = ['唐僧','孙悟空','猪八戒','牛魔王']
Xi_You_Ji[3] = '沙僧'
print(Xi_You_Ji)
输出结果:

2.通过切片,重新赋值
#通过切片进行重新赋值
Xi_You_Ji = ['唐僧','孙悟空','猪八戒','牛魔王','红孩儿']
print('重新赋值前:',Xi_You_Ji)
Xi_You_Ji[3:4] = '沙僧','白龙马'
print('重新赋值后:',Xi_You_Ji)
输出结果:

列表的其他操作
查看出现次数
count()
用法:
#count()查看元素出现次数
num_5 = [1,2,3,3,2,2,3,23,23,4,4,4,5,6,7,7]
print('num_5中2出现的次数为%d次'%num_5.count(2))
不止列表可以使用count()
变量名.count(元素)
查看列表中多少个元素
len()
#len()查看有多少个元素
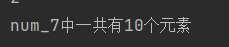
num_7 = [1,2,3,4,5,6,7,8,9,0]
print('num_7中一共有%d个元素'%len(num_7))
输出结果:
通过for循环拿到所有元素的值
#通过for循环遍历所有元素
Xi_You_Ji = ['唐僧','孙悟空','猪八戒','沙僧','白龙马']
for i,data in enumerate(Xi_You_Ji):
print(i,data)
enumerate()每个元素的索引值
输出结果:

列表排序
默认排序是大写排序
#列表排序
# 降序排序
name_1 = ['Play','play','a','A','YES','yes']
name_1.sort()
print(name_1)
# 升序排序
name_1 = ['Play','play','a','A','YES','yes']
name_1.sort(reverse=True)
print(name_1)
输出结果:

将列表的顺序打乱
#将列表打乱random
import random
name_1 = ['Play','play','a','A','YES','yes']
print('原有列表:',name_1)
random.shuffle(name_1)
print('打乱列表:',name_1)
输出结果:

1.2字典(dictionary)
字典是一种无序、可变的序列
字典基本格式:建值对(key : value)
字典是由键、值对构成。一个键对应着一个值。
字典的值可以是任何数据
字典的键必须是满足命名规则
值可以是任何数据类型
创建基本的字典格式:
#字典:键不能重复
#考点:列表中嵌套字典(学生信息管理系统!)
Student = {
'name':'温胡可',
'age' : '19岁',
'class':'数据1班',
'id':'21264000',
'sex':'男'
}
每个键值对之间要用逗号分割
访问字典:
ict_2 = {
'name':'zhangsan',#字符串
'age':18,#整型
'flot':18.2,#浮点型
'live_statu':True,#布尔型
'dianhua':['17381956695','15397613092'],#列表
'shenfenzheng':('510107200209190017','四川成都'),#元组
'address':{'nation':'china','privince':'sichuan','city':'luzhou'}#字典
}
print('输出的年龄为{}岁'.format(dict_2['age']))
输出结果:

通过键访问字典中字典的值
访问china
dict_2 = {
'name':'zhangsan',#字符串
'age':18,#整型
'flot':18.2,#浮点型
'live_statu':True,#布尔型
'dianhua':['17381956695','15397613092'],#列表
'shenfenzheng':('510107200209190017','四川成都'),#元组
'address':{'nation':'china','privince':'sichuan','city':'luzhou'}#字典
}
print('输出的结果为{}'.format(dict_2['address']['nation']))
输出结果:

修改字典的值
通过键修改值
dict_2 = {
'name':'zhangsan',#字符串
'age':18,#整型
'flot':18.2,#浮点型
'live_statu':True,#布尔型
'dianhua':['17381956695','15397613092'],#列表
'shenfenzheng':('510107200209190017','四川成都'),#元组
'address':{'nation':'china','privince':'sichuan','city':'luzhou'}#字典
}
# 修改字典的值
dict_2['age'] = 32
print('修改后的值:',dict_2['age'])
输出结果:

删除字典的键、值
pop(‘键’)
# 3.2 删除字典的键,值
dict_2 = {
'name':'zhangsan',#字符串
'age':18,#整型
'flot':18.2,#浮点型
'live_statu':True,#布尔型
'dianhua':['17381956695','15397613092'],#列表
'shenfenzheng':('510107200209190017','四川成都'),#元组
'address':{'nation':'china','privince':'sichuan','city':'luzhou'}#字典
}
s = dict_2.pop('name')
del函数使用
# 3.3del全局方法可以清空整个字典,也可以只删除单一元素
dict_2 = {
'name':'zhangsan',#字符串
'age':18,#整型
'flot':18.2,#浮点型
'live_statu':True,#布尔型
'dianhua':['17381956695','15397613092'],#列表
'shenfenzheng':('510107200209190017','四川成都'),#元组
'address':{'nation':'china','privince':'sichuan','city':'luzhou'}#字典
}
del dict_2['flot']
del dict_2
遍历字典
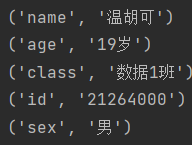
Student = {
'name':'温胡可',
'age' : '19岁',
'class':'数据1班',
'id':'21264000',
'sex':'男'
}
# 通过键去取值
print(Student['name'])
#遍历字典
for i in Student.items():
print(i)
输出结果:
1.3集合(set)
集合特点就是:元素不重复
# 3.集合:元素不重复
set_1 = {1,2,3,4,5,6,1,2}
print(set_1)
输出结果:

函数
函数的四种输出方式
# 1.无参无返回值函数
def no_money():
sum_1 = 0
for i in range(1,101):
sum_1 += i
print(sum_1)
# 函数调用
no_money()
# 2.无参有返回值函数
def series_add():#只能计算1——100
sum_1 = 0
for i in range(1,101):
sum_1 += i
return sum_1
# 函数调用
print(series_add())
#3.有参有返回值函数
def series_add(a,b):
sum_1 = 0
for i in range(a,b+1):
sum_1 += i
return sum_1
# 调用函数
print(series_add(1,500))#求1——500的和
# 4.有参数无返回值
def series_add_1(a,b):
sum_1 = 0
for i in range(a,b+1):
sum_1 += i
print(sum_1)
# 调用函数
series_add_1(1,500)#求1——500的和
缺省参数函数
#缺省参数函数
def student_info(name,age,nation='汉族'):
print(name,age,nation)
#默认参数只能放在最后
student_info('张金树',19)
student_info('温胡可',18,'回族')
任意参数函数
#任意参数函数(随便调用多少参数)
def my_function(*k):
for data in k:
print(data)
my_function('温胡可','罗天恩','张金树','罗少陪')
my_function('Liujunwei',19,'男性')
文件操作
文件打开方式
'''文件的打开方式:
r:只读方式打开文本,文本必须存在
w:只写方式打开文件文本,文本存在清空文本从头开始书写,
若不存在则根据文件名创建新文件只写打开
a:以只写的方式打开文件文本,文本若存在则从文本尾部书写,文件原来存在的内容不会清楚,若不存在则根据文件名创建文件,并且以只写打开。
后面追加+的话,可以可读可写'''
文件的两种打开语法
open
f = open('文件名.txt','r')
f.close()#关闭文件
with open as
with open('文件名.txt','r',encoding='UTF-8') as j:
j.close
将数据写入打开文件
f = open('文件名.txt','a',encoding='UTF-8')#最后一个是字符编码
f.write('中国万岁')
f.close()
注意:打开了文件,操作了以后一定要close()
最后祝各位期末蒙的全对,考的全会!
学习知识要善于思考,思考,再思考。—— 爱因斯坦
作者:想努力学习变强的尾巴
日期:2022/1/6