1.背景介绍
在实际应用场景中我们会遇见很多无监督分类的任务,样本不具有类别标注,我们无法通过有监督学习设计分类器。基于样本间相似性度量的聚类方法是无监督学习的重要组成部分。一般来说,聚类准则是根据样本之间的距离或相似程度来定义的,通常将相似或者相近的样本分成一类,从而实现整体样本的分类。下面我们将介绍K均值与模糊C均值两种经典的动态聚类算法。
2.模型建立以及求解方法
2.1K均值算法
K均值聚类算法是应用最广泛的基于划分的聚类算法之一,适用于处理大样本数据。它根据样本间的距离作为相似度的度量,目标是根据输入参数K将数据集划分为K簇,所以称之为K均值聚类。K均值算法简单易用,在处理分布接近球体的样本时具有较好的聚类效果。
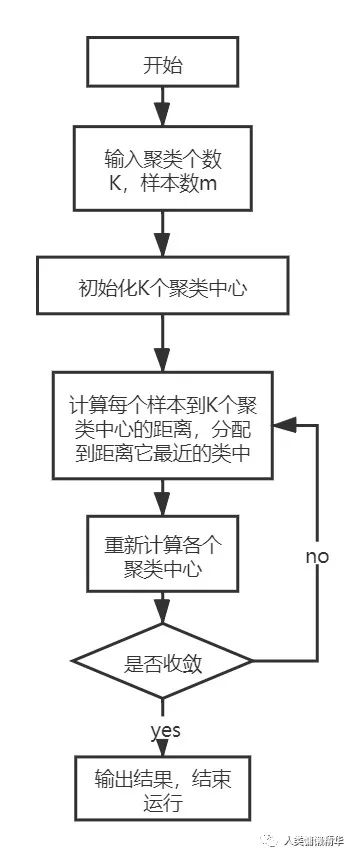
K均值算法采用迭代更新的方法,在每一轮中根据K个聚类中心将样本分成K簇,并将每个簇的质心作为下一次迭代的参考点。数次迭代后,算法就能够得到效果较好的聚类中心。算法流程图如下:
2.2模糊C均值算法
K均值聚类属于硬聚类算法,把数据点划分到确切的某一聚类中。而模糊C均值算法(Fuzzy C-Means,以下简称FCM算法)属于软聚类,也就是说一条样本与不同类之间具有不同的隶属度。隶属度是衡量样本隶属于某一集合的程度的表现,值域范围为。
FCM的目标函数是把m个样本分为c个模糊集合,并给出聚类中心,使得代价函数的值最小。我们构建一个隶属矩阵,其中表示第i条样本对于第j个模糊集合的隶属度。FCM进行归一化约束后,样本数据属于所有类的隶属度的总和应该等于1,即:
FCM的目标函数定义为:
其中,为第j个模糊集合的聚类中心;表示第i条样本与第j个聚类中心间的欧式距离,这里作为一个加权指数;为柔性参数。我们需要让目标函数达到最小,此时的必要条件为:
其中,是(1)的m个约束式的拉格朗日乘数。
我们对输入参量进行求导,从而得到目标函数达到最小值的条件:
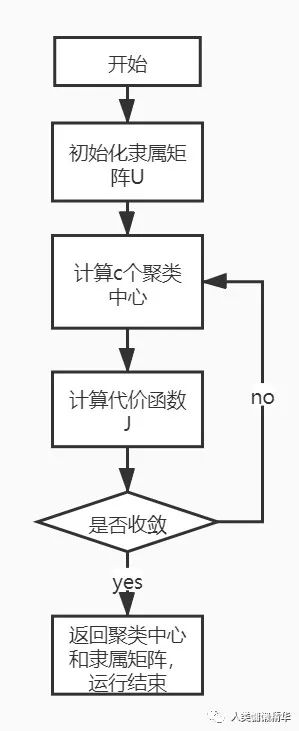
根据上式,我们可以不断进行迭代,计算出新的聚类中心和隶属度矩阵。当代价函数小于某个阈值或者与上一代的代价函数值的变化小于某个阈值,则算法停止。算法流程图如下:
得到最终的隶属矩阵后,可以对m条样本根据最大隶属度进行划分,即一条样本与哪个模糊集合的隶属度最大就将该样本划分到那个类。FCM算法的柔性参数是对算法起控制作用,如果其过大将导致算法难以收敛;如果过小会使算法失去模糊效果,导致性能接近K均值算法。
2.3评价准则:纯度
对于一个聚类集合i,指的是i中成员属于类(class)j 的概率。
其中是聚类i中样本的个数。聚类i的纯度(purity)定义为
整个聚类划分的纯度为
其中K是聚类的数目,m是整个聚类划分的样本数。纯度在[0,1]之间,越接近1,说明聚类的正确率越高。以下我们将用纯度来评价聚类效果。
3.实验
3.1实验环境
本文使用 python3.7 进行编程仿真,并使用了 sklearn、numpy、matplotlib 等 python 库。
3.2iris数据集分类
老朋友iris 数据集中包含了 3 类鸢尾花特征数据。每一类分别有 50 条样本,每条样本有 4 个维度的特征数据(花萼长度,花萼宽度,花瓣长度,花瓣宽度)。
3.2.1iris数据集k均值分类
我们设定k值为3,进行k均值分类。首先,采用150个具有四维特征的样本进行实验,并求得每次聚类的整体纯度。进行十次实验求取平均值,平均纯度为0.8273。可以发现,每次进行聚类时,平均迭代8.86次算法达到收敛,且收敛后得到的聚类效果与初始聚类中心的关系较大,具有一定的随机性。
然后,我们分别采用花萼长度与宽度,花瓣长度与宽度进行聚类,并进行可视化分析。
我们对花萼长度、宽度这两个特征,对150条样本进行比较。如下图所示,可以发现第一类鸢尾花与第二、三两类区分较大。而第二、三两类鸢尾花之间在花萼宽度 上差异较小,难以直接区分,第三类鸢尾花的花萼长度整体较长。

进行K均值聚类后,我们可以得到某次实验的聚类划分图,其中红色的“x”表示聚类中心:
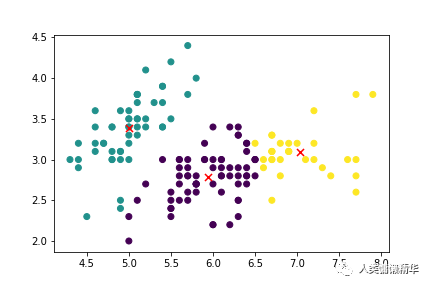
多次实验我们可以得到平均纯度为0.816,平均迭代次数为10.2次