作者:刘楚杰,时间:2022年11月13日
未经本人允许禁止转载
常见的分治算法通常将一个问题平分为两个子问题,然后先解决两个子问题,再来处理当前问题。
给 n n n个数,将这些数从小到大排列
思路:
我们先将这些数平分成左半部分和右半部分,分别先对左半部分和右半部分从小到大排序,然后我们再来处理当前这些数:
因为左半部分与右半部分都已经排好序,假设当前这些数的左端点指针为 l e f t left left,右端点指针为 r i g h t right right,存储这些数的数组为 a [ ] a[\ ] a[ ], m i d = ( l e f t + r i g h t ) 2 mid = \frac{(left + right)}{2} mid=2(left+right),也就是说,我们先分别对 a [ l e f t ] 到 a [ m i d ] a[left]到a[mid] a[left]到a[mid]、 a [ m i d + 1 ] 到 a [ r i g h t ] a[mid+1]到a[right] a[mid+1]到a[right]从小到大排序,然后再对两边从小到大合并,合并的方法为:
C++代码:
void ssort(int left, int right)
{
if(left == right)
return;
int mid = (left + right) / 2;
ssort(left, mid);
ssort(mid + 1, right);
int i = left, j = mid + 1;
for(int q = left; q <= right; q ++)
{
if(j > right || a[i] <= a[j])
b[q] = a[i++];
else
b[q] = a[j++];
}
for(int q = left; q <= right; q ++)
a[q] = b[q];
return;
}
在一个排列中,如果一对数的前后位置与大小顺序相反,即前面的数大于后面的数,那么它们就称为一个逆序。一个排列中逆序的总数就称为这个排列的逆序数。
比如一个元素个数为4的数列,其元素为2,4,3,1,则(2,1),(4,3),(4,1),(3,1)是逆序,逆序数是4
现在求给定数列的逆序数
思路:
对于这个问题,我们很容易想到 Θ ( n 2 ) \Theta(n^2) Θ(n2)的算法,也就是枚举一个数后面的所有的数,记录比这个数小的数的个数。
但如果我们使用归并排序去处理,这道题的时间复杂度可以从 Θ ( n 2 ) \Theta(n^2) Θ(n2)降低为 Θ ( n l o g 2 n ) \Theta(nlog_2n) Θ(nlog2n),
我们如何使用归并排序的方法去求逆序对的个数呢?
对于 a [ l e f t ] a[left] a[left]到 a [ r i g h t ] a[right] a[right],我们把它们分为 a [ l e f t ] a[left] a[left]到 a [ m i d ] a[mid] a[mid]、 a [ m i d + 1 ] a[mid+1] a[mid+1]到 a [ r i g h t ] a[right] a[right]两个部分,其中, m i d = ( l e f t + r i g h t ) ÷ 2 mid = (left + right) \div 2 mid=(left+right)÷2,分别先对左半部分和右半部分从小到大排序,接下来再进行合并:
C++代码:
int ssort(int left, int right)
{
if(left == right)
return 0;
int mid = (left + right) / 2;
int sum = 0;
sum += ssort(left, mid);
sum += ssort(mid + 1, right);
int i = left, j = mid + 1;
for(int q = left; q <= right; q ++)
{
if(j > right || a[i] <= a[j])
b[q] = a[i++];
else
b[q] = a[j], sum += (q - j), j ++;
}
for(int q = left; q <= right; q ++)
a[q] = b[q];
return sum;
}
给 n n n个数,将这些数从小到大排列
思路:
如果我们使用归并排序,虽然其时间复杂度为最优,但其需要多开一个数组,比较消耗内存,空间复杂度较大,而快速排序则不需要多开一个数组,但快速排序的时间复杂度不稳定,最优时为 n l o g 2 n nlog_2n nlog2n,最差时为 n 2 n^2 n2,最差的情况为:原本的数列按从大到小排序,而我们需要更改为从小到大排序,对于这种情况,有一种优化的方法:将数列打乱后进行快速排序。
快速排序的内容:
假设我们选定的基准为 a [ m i d ] a[mid] a[mid], m i d = l e f t + r i g h t 2 mid = \frac{left + right}{2} mid=2left+right,
我们如何将比 a [ m i d ] a[mid] a[mid]小的数放到 a [ m i d ] a[mid] a[mid]左边,将比 a [ m i d ] a[mid] a[mid]大的数放大 a [ m i d ] a[mid] a[mid]右边呢?
我们可以设置两个指针 i i i与 j j j,首先让 i = l e f t i = left i=left, j = r i g h t j = right j=right,然后 j j j往左走, i i i往右走:
注意:需要保证 i ≤ j i \leq j i≤j
这么处理后,我们可能会把 a [ m i d ] a[mid] a[mid]的位置都换了,我们有两种处理方法:
C++代码:
void quick_sort(int left, int right)
{
int i = left, j = right, mid = (left + right) / 2;
int x = a[mid];
while(i <= j)
{
while(a[i] < x) i ++;
while(a[j] > x) j --;
if(i <= j)
{
int b = a[i];
a[i] = a[j], a[j] = b;
i ++, j --;
}
}
if(j > left) quick_sort(left, j);
if(i < right) quick_sort(i, right);
}
给你一个长度为 n n n的序列,求序列中第 k k k小数的多少。
思路:
我们可以直接对这个序列进行从小到大的排序,时间复杂度为 Θ ( n l o g 2 n ) \Theta(nlog_2n) Θ(nlog2n),然后直接输出第 k k k个数
当然,我们也可以修改一下快速排序的代码,使得可以更快地去找到这个数:
我们依旧是选择一个基准,如果然后将比基准小的数都放到基准左边,经比基准大的数都放大基准的右边,记录最后基准所处的位置,如果基准的位置大于 k k k,则对基准左边的数进行相同处理(不处理基准右边的数);如果基准的位置小于 k k k,则对基准右边的数进行相同处理(不处理基准左边的数);如果基准的位置等于 k k k,则直接返回此数;
先遍历树的根节点,然后遍历树的左子树,最后遍历树的右子树,对于所有子树的处理方式相同,如果此节点为叶节点,则直接返回该节点
先序遍历的结果为:
先遍历树的左子树,然后遍历树的根节点,最后遍历树的右子树,对于所有子树的处理方式相同,如果此节点为叶节点,则直接返回该节点
中序遍历的结果为:
先遍历树的左子树,然后遍历树的右子树,最后遍历树的根节点,对于所有子树的处理方式相同,如果此节点为叶节点,则直接返回该节点
后续遍历的结果为:
首先,我们知道,先序遍历的最左边肯定是根节点,在中序遍历中找到这个根节点,则中序遍历中,这个根节点的左边肯定是左子树,这个根节点的右边肯定是右子树。则我们可以将中序遍历中根节点左边和右边的部分分别进行同样的处理:在先序遍历中找到根节点,然后继续在中序遍历中找到左子树和右子树,当最后只有一个字符时,就代表该节点为叶节点。
注意:不管是先序遍历、中序遍历还是后序遍历,左子树的所有节点在字符串中肯定都是连在一起的,中间不可能出现其他的节点,同样,右子树的所有节点在字符串中肯定也是连在一起的,中间不可能出现其他的节点。
假设一棵二叉树的先序遍历为 A B C D F E ABCDFE ABCDFE,中序遍历为 B A D F C E BADFCE BADFCE
则:先序遍历确定 A A A为根节点,从中序遍历,可以确定左子树为 B B B,右子树为 D F C E DFCE DFCE,因为左子树只有一个节点,因此 B B B为叶节点,然后我们看右子树部分:先序遍历为 C D F E CDFE CDFE,中序遍历为 D F C E DFCE DFCE,根据先序遍历,确定根节点为 C C C,中序遍历确定左子树为 D F DF DF,右子树为 E E E。然后我们看左子树比分:先序遍历为 D F DF DF,中序遍历为 D F DF DF,根据先序遍历,确定根节点为 D D D,根据中序遍历,确定右子树为 F F F,因此,这棵树为:
空的代表没有此节点
首先,我们知道,后序遍历的最右边肯定是根节点,在中序遍历中找到这个根节点,则中序遍历中,这个根节点的左边肯定是左子树,这个根节点的右边肯定是右子树。则我们可以将中序遍历中根节点左边和右边的部分分别进行同样的处理:在后续遍历中找到根节点,然后继续在中序遍历中找到左子树和右子树,当最后只有一个字符时,就代表该节点为叶节点。
先序遍历的最左边肯定是根节点,后序遍历的最右边肯定是根节点,但我们无法从中区分出左子树与右子树,因此,给出二叉树的先序遍历和后序遍历,我们无法确定这颗二叉树,因此也就无法求出中序遍历。
给定先序遍历和后序遍历,限定:若某节点只有一个子节点,则此处将其看做左子节点。
首先,我们知道,先序遍历的最左边肯定是根节点,先序遍历的第二个字符肯定是根节点的左子树的根节点;后序遍历的最右边肯定是根节点,根据根节点的左子树的根节点,在后序遍历中找到这个节点,然后这个节点的左边肯定都是左子树的部分,这个节点的右边到根节点的左边肯定是右子树部分,依次类推。
假设一个表达式中有 + , − , × , ÷ , +,-,\times,\div, +,−,×,÷,次方和阶乘运算,其中,阶乘的优先级最高,其次是次方,然后是乘除,最后是加减。括号( )可以更改优先级,优先算优先级高的,在优先级相同时,从左到右计算。给出一个表达式,求出其值。
思路:
我们在这个表达式中找到所有运算符最后出现的位置,如果没有出现该运算符,则记为-1,然后看出现的优先级最低的字符串,假设其最后位置为 k k k,则我们计算 [ l e f t , k − 1 ] [left, k-1] [left,k−1]的值,计算 [ k + 1 , r i g h t ] [k+1, right] [k+1,right]的值,最后面将这两个值的运算结果(取决于这个运算符)返回。也就是说,我们从最后计算的开始处理,如果优先级相同,则我们先从最后一个运算符开始,然后计算这个运算符左边的部分和右边部分的值,最后再处理这两个值的运算。当然,如果这个运算符号为 ! ! !,也就是阶乘,我们只需要计算这个运算符左边的部分即可,最后返回左边数值的阶乘结果。
注意:因为括号可以更改运算优先级,括号内的部分我们则直接忽略,不统计其内的运算符号,记录括号外部的运算符号最后出现的位置,如果分治后该表达式被括号包围,那么就代表我们已经处理到括号内部的表达式了,去除该表达式最左边和最右边的两个字符,也就是(和),然后继续正常处理即可。
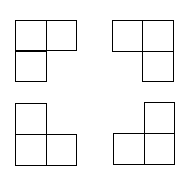
有一个 2 k × 2 k 2^k \times 2^k 2k×2k的方格棋盘,恰有一个方格是黑色的,其他为白色。你的任务是用包含3个方格的 L L L型牌覆盖所有的白色方格。黑色方格不能被覆盖,且任意一个白色方格不能同时被两个或更多牌覆盖。如图所示为 L L L型牌的四种旋转方式:
思路:
本题的棋盘是 2 k × 2 k 2^k \times 2^k 2k×2k的,很容易想到分治:吧棋盘切为4块,则每一块都是 2 k − 1 × 2 k − 1 2^{k-1} \times 2^{k-1} 2k−1×2k−1的。有黑格的那一块可以递归解决,但其他三块没有黑格子,应该怎么办呢?可以构造出一个黑格子,如图,递归边界也不难得出: k = 1 k=1 k=1时一块牌就够了。————《算法竞赛入门经典》
n = 2 k n=2^k n=2k个运动员进行网球循环赛,需要设计比赛日程表。每个选手必须与其他 n − 1 n-1 n−1个选手各赛一次;每个选手一天只能赛一次;循环赛一共进行 n − 1 n-1 n−1天。按此要求设计一张比赛日程表,该表有 n n n行和 n − 1 n-1 n−1列,第 i i i行 j j j列为第 i i i个选手第 j j j填遇到的选手。
思路:
本题的方法有很多,递归分治是其中一种比较容易理解的方法。
我们可以将这个日程表平分为四份,左上半部分可以先让前 2 k − 1 2^{k-1} 2k−1相互比赛,左下半部分可以先让后 2 k − 1 2^{k-1} 2k−1相互比赛,其中左上半部分和左下半部分可以理解为它们是对称的,只是比赛人的编号不一样,因为左下半部分为 2 k − 1 + 1 2^{k-1}+1 2k−1+1到 2 k 2^k 2k编号的人相互比赛,左上半部分为1到 2 k − 1 相互比赛 2^{k-1}相互比赛 2k−1相互比赛
因此,左下半部分可以为左上半部分的编号加上 2 k − 1 得到 2^{k-1}得到 2k−1得到。
因为左上半部分和左下半部分都保证了同一个编号在同一行、同一列中都只出现了一次,而右上半部分为编号 1 到 2 k − 1 和 2 k − 1 + 1 到 2 k 1到2^{k-1}和2^{k-1}+1到2^k 1到2k−1和2k−1+1到2k相互比赛,左下半部分仅有 2 k − 1 + 1 到 2 k 2^{k-1}+1到2^k 2k−1+1到2k,右上半部分也需要填入 2 k − 1 + 1 到 2 k 2^{k-1}+1到2^k 2k−1+1到2k的部分,因此右上半部分可以直接复制左下半部分,同理,右下半部分可以直接复制左上半部分。
因此,我们只需要处理左上半部分,剩下的部分都可以通过左上半部分得到,而左上半部分继续分治递归即可。
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|
| 2 | 1 | 4 | 3 | 6 | 5 | 8 | 7 |
| 3 | 4 | 1 | 2 | 7 | 8 | 5 | 6 |
| 4 | 3 | 2 | 1 | 8 | 7 | 6 | 5 |
| 5 | 6 | 7 | 8 | 1 | 2 | 3 | 4 |
| 6 | 5 | 8 | 7 | 2 | 1 | 4 | 3 |
| 7 | 8 | 5 | 6 | 3 | 4 | 1 | 2 |
| 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
注意:第一列为队伍名,后面的第 k k k列为该队伍第 k − 1 k-1 k−1天与之比赛的队伍名
在平面上有 n n n个巨人和 n n n个鬼,没有三者在同一条直线上。每个巨人需要选择一个不同的鬼,向其发送质子流消灭它。质子流由巨人发射,沿直线进行,遇到鬼后消失。由于质子流交叉是很危险的,所有质子流经过的线段不能有交点。请设计一种给巨人和鬼配对的方案。
思路:
由于只需要一种配对方案,从直观上来说本题是一定有解的。由于每一个巨人和鬼都需要找一个目标,不妨先给“最特殊”的巨人或鬼寻找“搭档”。
考虑 y y y坐标最小的点(即最低点)。如果有多个这样的点,考虑最左边的点(即其中最左边的点),则所有点的极角在范围 [ 0 , π ) [0, \pi) [0,π)内。不妨设它是一个巨人,然后把所有其他点按照极角从小到大的顺序排序后依次检查。
情况一:第一个点是鬼,那么配对完成,剩下的巨人和鬼仍然是一样多,而且不会和这一条线段交叉。
情况二:第一个点是巨人,那么继续检查,知道已检查的点中鬼和巨人一样多为止。找到了这个“鬼和巨人”配对区间后,只需要把此区间内的点配对,再把区域外的点配对即可。这个配对过程是递归的,好比棋盘覆盖中一样,会不会找不到这样的配对区间呢?不会的。因为检查完第一个点后鬼少一个,而检查完最后一个点时鬼多一个,而巨人和鬼的数量差每次只能改变1,因此“从少到多”的过程中一定会有“一样多”的时候。————《算法竞赛入门经典》
将 n n n个圆盘从第一根柱子上移到第三根柱子上,相当于先将前 n − 1 n-1 n−1个圆盘从第一根柱子移到第二根柱子上,然后将第 n n n个圆盘从第一根柱子移到第三根柱子上,再将前 n − 1 n-1 n−1个圆盘从第二根柱子移到第三根柱子上;将前 n − 1 n-1 n−1根柱子从第 A A A根柱子上移动到第 B B B根柱子上可以使用同样的方法,使用分治递归实现。
汉诺塔问题可以详见:
汉诺塔问题
在平面直角坐标上给定n个点的坐标,找到距离最短的两个点,输出这两个点的距离。
思路:
我们很容易想到 Θ ( n 2 ) \Theta(n^2) Θ(n2)的算法:枚举所有的两个点组合,找到其中距离最短的那一组。
其实这题使用分治算法能够更快地解出题目:
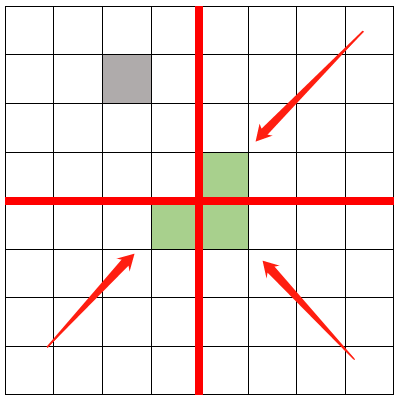
先将这些点按照 x x x坐标从小到大排序,排序后为 a 1 , a 2 , a 3 , . . . , a n a_1, a_2, a_3, ..., a_n a1,a2,a3,...,an,接下来使用分治思路:
我们处理 b i b_i bi时, b i b_i bi内部的循环不会超过7次,也就是说在 b i b_i bi之后至多有7个点的与 b i b_i bi的纵向距离小于 d d d:在选定的 a m i d 的 a_{mid}的 amid的左边,也就是与 a m i d 横向距离 a_{mid}横向距离 amid横向距离小于d的那一部分中,我们画一个边长为 d d d的正方形,这个正方形的左右边界就是选定左半部分的左右边界,因为左半部分所有点之间的最短距离肯定 ≥ d \geq d ≥d,因此,在这个正方形中,至多可以放入四个点,同理,在选定的右半部分同样如此,假设 a i a_i ai就是处于正方形的左上角,则这样最多有7个点与 a i a_i ai的纵向距离 ≤ d \leq d ≤d————由此可以推出,这个算法的时间复杂度为 Θ ( n l o g 2 n ) \Theta(nlog_2n) Θ(nlog2n)