标签:Kafka3.Kafka-eagle3;
一、简介
Kafka是一个开源的分布式事件流平台,常被用于高性能数据管道、流分析、数据集成和关键任务应用,基于Zookeeper协调的处理平台,也是一种消息系统,具有更好的吞吐量、内置分区、复制和容错,这使得它成为大规模消息处理应用程序的一个很好的解决方案;
二、环境搭建
1、Kafka部署
1、下载安装包:kafka_2.13-3.5.0.tgz
2、配置环境变量
open -e ~/.bash_profile
export KAFKA_HOME=/本地路径/kafka3.5
export PATH=$PATH:$KAFKA_HOME/bin
source ~/.bash_profile
3、该目录【kafka3.5/bin】启动zookeeper
zookeeper-server-start.sh ../config/zookeeper.properties
4、该目录【kafka3.5/bin】启动kafka
kafka-server-start.sh ../config/server.properties
2、Kafka测试
1、生产者
kafka-console-producer.sh --broker-list localhost:9092 --topic test-topic
>id-1-message
>id-2-message
2、消费者
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test-topic
id-1-message
id-2-message
3、查看topic列表
kafka-topics.sh --bootstrap-server localhost:9092 --list
test-topic
4、查看消息列表
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test-topic --from-beginning --partition 0
id-1-message
id-2-message
3、可视化工具
配置和部署
1、下载安装包:kafka-eagle-bin-3.0.2.tar.gz
2、配置环境变量
open -e ~/.bash_profile
export KE_HOME=/本地路径/efak-web-3.0.2
export PATH=$PATH:$KE_HOME/bin
source ~/.bash_profile
3、修改配置文件:system-config.properties
efak.zk.cluster.alias=cluster1
cluster1.zk.list=localhost:2181
efak.url=jdbc:mysql://127.0.0.1:3306/kafka-eagle
4、本地新建数据库:kafka-eagle,注意用户名和密码是否一致
5、启动命令
efak-web-3.0.2/bin/ke.sh start
命令语法: ./ke.sh {start|stop|restart|status|stats|find|gc|jdk|version|sdate|cluster}
6、本地访问【localhost:8048】 username:admin password:123456
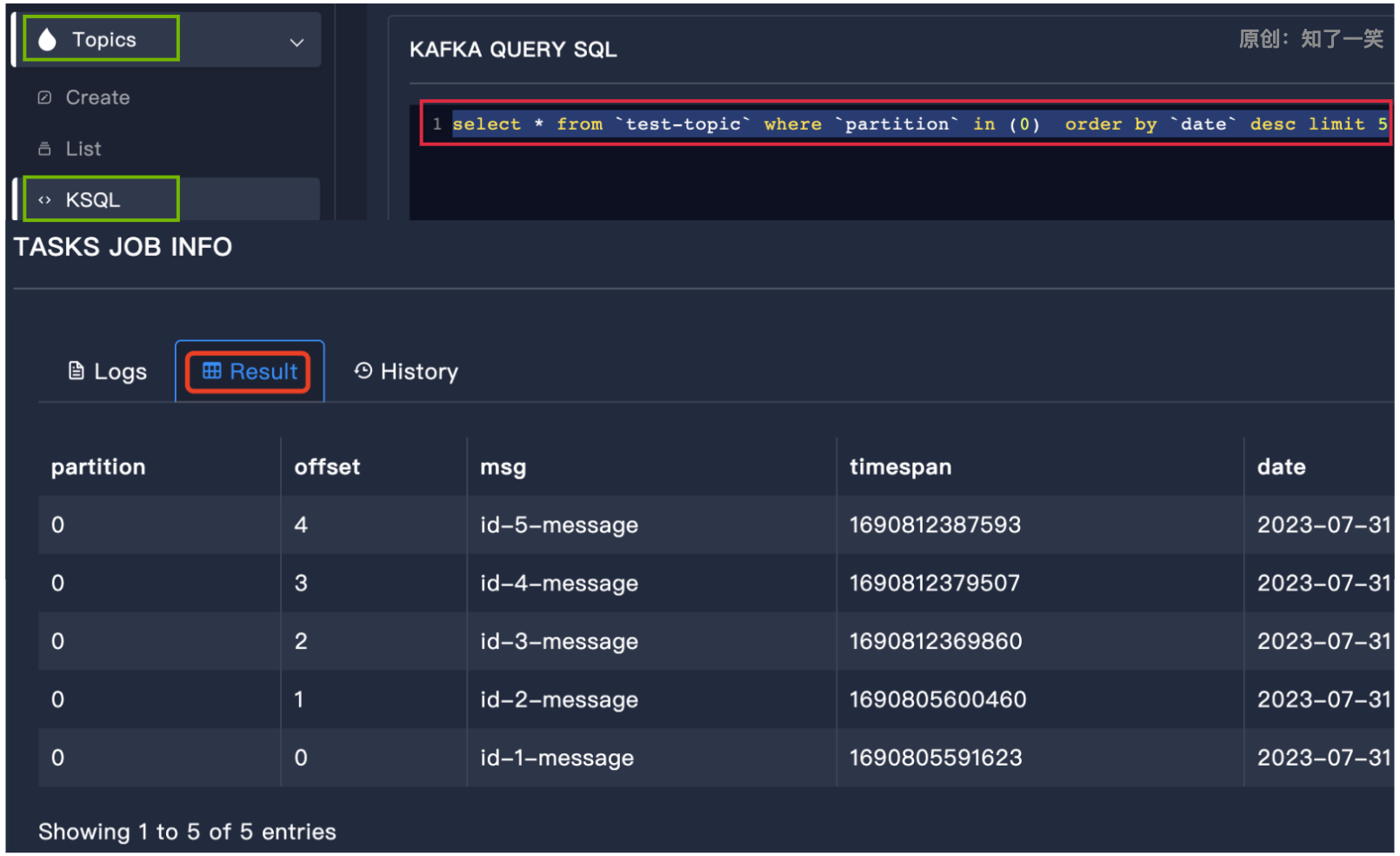
KSQL语句测试
select * from `test-topic` where `partition` in (0) order by `date` desc limit 5
select * from `test-topic` where `partition` in (0) and msg like '%5%' order by `date` desc limit 3

三、工程搭建
1、工程结构

2、依赖管理
这里关于依赖的管理就比较复杂了,首先spring-kafka组件选择与boot框架中spring相同的依赖,即6.0.10版本,在spring-kafka最近的版本中3.0.8符合;
但是该版本使用的是kafka-clients组件的3.3.2版本,在Spring文档的kafka模块中,明确说明spring-boot:3.1要使用kafka-clients:3.4,所以从spring-kafka组件中排除掉,重新依赖kafka-clients组件;
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>${spring-kafka.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka-clients.version}</version>
</dependency>
3、配置文件
配置kafka连接地址,监听器的消息应答机制,消费者的基础模式;
spring:
# kafka配置
kafka:
bootstrap-servers: localhost:9092
listener:
missing-topics-fatal: false
ack-mode: manual_immediate
consumer:
group-id: boot-kafka-group
enable-auto-commit: false
max-poll-records: 10
properties:
max.poll.interval.ms: 3600000
四、基础用法
1、消息生产
模板类KafkaTemplate用于执行高级的操作,封装各种消息发送的方法,在该方法中,通过topic和key以及消息主体,实现消息的生产;
@RestController
public class ProducerWeb {
@Resource
private KafkaTemplate<String, String> kafkaTemplate;
@GetMapping("/send/msg")
public String sendMsg (){
try {
// 构建消息主体
JsonMapper jsonMapper = new JsonMapper();
String msgBody = jsonMapper.writeValueAsString(new MqMsg(7,"boot-kafka-msg"));
// 发送消息
kafkaTemplate.send("boot-kafka-topic","boot-kafka-key",msgBody);
} catch (JsonProcessingException e) {
e.printStackTrace();
}
return "OK" ;
}
}
2、消息消费
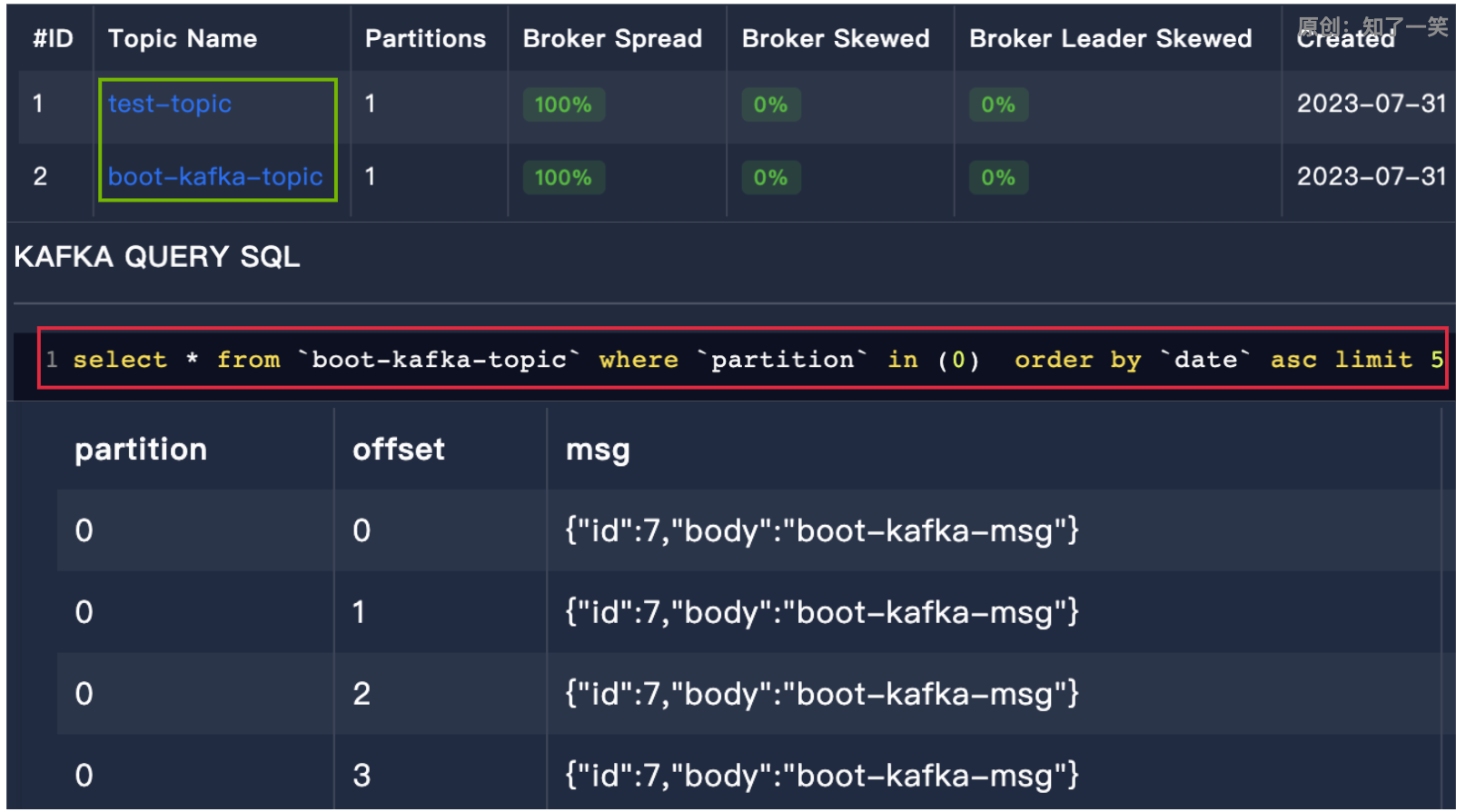
编写消息监听类,通过KafkaListener注解控制监听的具体信息,在实现消息生产和消费的方法测试后,使用可视化工具kafka-eagle查看topic和消息列表;
@Component
public class ConsumerListener {
private static final Logger log = LoggerFactory.getLogger(ConsumerListener.class);
@KafkaListener(topics = "boot-kafka-topic")
public void listenUser (ConsumerRecord<?,String> record, Acknowledgment acknowledgment) {
try {
String key = String.valueOf(record.key());
String body = record.value();
log.info("\n=====\ntopic:boot-kafka-topic,key{},body:{}\n=====\n",key,body);
} catch (Exception e){
e.printStackTrace();
} finally {
acknowledgment.acknowledge();
}
}
}
五、参考源码
文档仓库:
https://gitee.com/cicadasmile/butte-java-note
源码仓库:
https://gitee.com/cicadasmile/butte-spring-parent