1. 系统概要
手写数字识别画板系统,按照MVC原则开发,主要由两部分组成:交互界面(视图View)部分是传统的HTML +CSS+JS网页(这同样也是一种遵循MVC开发方式);手写数字识别部分(模型Model)是使用Python开发的深度学习的模型;两者间通过基于Flask框架开发的Python Web服务连接(控制Control),具体而言,两者间手写数字识别部分功能的信息传输方式为:HTTP请求收发JSON格式的数据。
项目Jupyter Noteook(阿里天池)
https://tianchi.aliyun.com/notebook-ai/detail?postId=469149
项目Gitee地址
https://gitee.com/ranlychan/hand-writting-digit-rec-web-app
项目Github地址
https://github.com/ranlychan/HandWrittingDigitRecWebApp
2. 界面设计
2.1 移动界面设计准则
相较于Web界面设计,移动界面有其特殊性,其设计需要从一般准则中针对移动场景做出更加细化的阐释,如下 :
(1) 内容优先:界面布局应以内容为核心,提供符合用户期望的内容。
(2) 为触摸而设计:界面的交互系统以自然手势为基础建构,符合人体工学并保持一致性。
(3) 转换输入方式:使用各种手机的设备特性和设计手段,减少在应用内的文字输入。
(4) 流畅性:保持应用交互的手指及手势的操作流、用户的注意流和界面反馈转场的流畅性。
(5) 多通道设计:发挥设备的多通道特性、协同的多通道界面和交互,让用户更有真实感和沉浸感。
(6) 易学性:保持界面架构简单、明了,导航设计清晰易理解,操作简单可见,通过界面元素的表意的和界面提供的线索就能让用户清楚地知道其操作方式。
(7) 为中断而设计:考虑应用的使用情境,确保在各个产出中断的情境下,让用户恢复之前的操作,保持用户的劳动付出。
(8) 智能有爱:给用户提供让他感到惊喜有趣的、智能高效的、贴心的设计。
2.2 数字手写板Web界面设计
界面基本要素
- 工具按钮:选择画笔、选择橡皮、撤回操作、全屏清除、识别数字
- 颜色按钮:黑白红蓝等预先选择好的颜色按钮,用于选择画笔颜色
- 粗细调节:画笔/橡皮粗细范围调节
交互操作说明
如下为进入页面后的工作区域图:

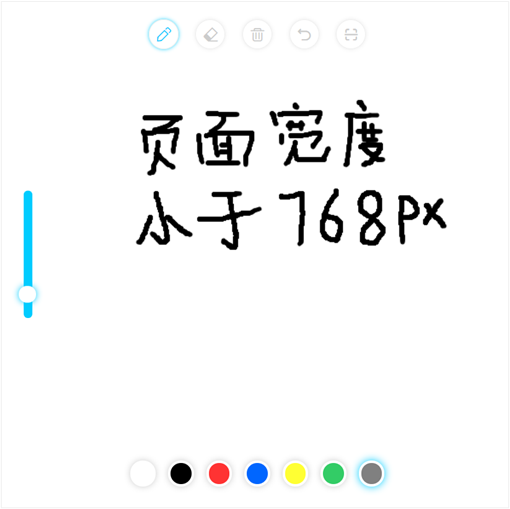
其中,单击工具栏最左端的“画笔”图标,可切换画笔工具在画布上绘制线条;画布区域为页面除了工具图标、颜色选择器、粗细调节器等覆盖区域外的白色区域;
单击下方工具栏左数第二的“橡皮”图标可切换橡皮工具,将画布上的画笔痕迹擦除;单击下方工具栏左数第三的“垃圾桶”图标可将画布全部清空;
单击下方工具栏左数第四的“回撤”图标可将回撤到上一步操作(可回撤使用画笔、橡皮或清空画布的三个操作);
单击下方工具栏最右端的“扫描”图标可尝试对当前画布内容进行手写数字识别,识别的结果将以文字和图片形式弹窗显示。其中图片形式即在画布内容基础上,框选出识别到的手写数字,并将识别数字附在框的左上角(如图2.3)。

调节画笔和橡皮粗细的工具在页面最右侧,页面宽度小于768px时自适应到页面最左侧。上滑可调粗,下滑调细。对于画笔粗细的调节如2.4所示。

调节画笔颜色的工具在页面最左侧,页面宽度小于768px时自适应到页面最下方。单击即可选择对应颜色,效果如图2.5所示。

3. Web服务
根据W3C的定义,Web服务应当是一个软件系统,用以支持网络间不同机器的互动操作。网路服务通常是许多应用程序接口所组成的,它们通过网络,例如国际互联网的远程服务器,执行客户所提交服务的请求。
3.1 Web应用程序框架概述
Web服务的开发如今越来越依赖于Web应用程序框架(Web Application Framework),其允许用户可以集中精力编写业务程序,而无需过多关注底层协议和线程管理等细节。由于后续将使用Python编写深度学习的模型,所以在此对比介绍并考虑采用基于Python的Web应用程序框架。
不难发现,手写数字识别系统的需求并不复杂,暂时未涉及数据库,是一个基本的B/S应用程序。故而考虑使用精简易用,同时教程丰富的Flask作为开发框架。
3.2 Web服务搭建
3.2.1 开发与运行环境
Flask支持Python 3.6及以上的版本。同时推荐使用虚拟的Python环境构建器作为其环境支持,一般选择virtualenv(可选)。
在Python环境的配置完成后,确保pip正确安装的情况下,可直接使用pip install flask自动安装Flask及其相关依赖。当安装 Flask 时,以下配套软件会被自动安装 :
a) Werkzeug 用于实现WSGI ,即应用和服务之间的标准Python接口。
b) Jinja 用于渲染页面的模板语言。
c) MarkupSafe 与 Jinja 共用,在渲染页面时用于避免不可信的输入,防止注入攻击。
d) ItsDangerous 保证数据完整性的安全标志数据,用于保护 Flask 的 session cookie.
e) Click 是一个命令行应用的框架。用于提供 flask 命令,并允许添加自定义管理命令。
表3.1 项目所使用的开发与运行环境一览
| 项目 |
名称 |
版本 |
| 操作系统 |
Windows |
10家庭中文版21H1 (x64) |
| 集成开发环境 |
PyCharm |
2019.3 (x64) |
| 编译器 |
Python |
3.8 |
| Web Application Framework |
Flask |
2.0.2 |
4.2.2 开始使用Flask
通过Pycharm新建一个Flask项目,项目根目录下会自动生成static、templates文件夹以及app.py主程序。在static文件夹下一般存放css样式、js脚本和其它静态资源。在templates文件夹下存放html网页,称网页文件为模板。主程序app.py中默认代码如下:
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello World!'
if __name__ == '__main__':
app.run()
其中最为重要的部分就是“路由-函数”映射关系的建立。“路由-函数”关系映射指URL访问路径与Python函数间的关系映射。经典的映射关系建立方式为:在被映射的函数function上方使用@app.route('url_path')注解,这样在访问url_path时就会调用function并以http报文返回function函数的return结果。
其次需要对静态文件夹和模板文件夹进行配置,在应用实例化时进行如下配置:
app = Flask(__name__,
template_folder='templates',
static_folder='static',
static_url_path='/static')
有了如上基础,就可以开始着手于手写数字识别的Web服务搭建了。首先明确需要一个可供用户访问和使用的网页来实现画板的功能,其次需要一个POST接口传输用户的手写字体图片内容和程序识别后的内容。
对于手写数字画板网页,需要建立一个canva.html文件于templates文件夹下,并在app.py中建立映射:
@app.route('/')
def hello():
return render_template('canva.html')
使得根路径被访问时显示该主界面。主界面所需的css样式共两个:canvas_style.css及pop_window.css一并存于static/css文件夹下,两个文件分别是画板样式表和识别结果的弹出窗口样式表。
同时,主页面的程序逻辑在main.js中实现,其保存在static/js文件夹下。由于需要使用到js库JQuery,故需要将jquery-3.4.0.min.js下载并存入static/js文件夹。
在html中,调用css样式表一般写在标签内,如下:
<link rel="stylesheet" href="/static/css/canvas_style.css">
<link rel="stylesheet" href="/static/css/pop_window.css">
调用js脚本一般写在</body>之后,</html>之前,如下:
<script src="/static/js/jquery-3.4.0.min.js"></script>
<script src="/static/js/main.js"></script>
值得一提的是,页面的编写由于需要使用到许多图标,如果将图标素材一个个存入本地,逐个编写样式引用的话会比较麻烦,所以这里使用了阿里旗下的iconfont矢量图标库的服务 。只需在iconfont上建立项目,并将挑选的图标归入项目中,就可为项目自动生成一个图标调用css文件,在html中引用了该css文件后,在需要使用图标的位置只需使用 <i class="iconfont">3</i> 这样简单的<i>标签和图标编号即可实现调用。
3.2.4手写数字识别接口开发
接口同样是在app.py中通过路由映射的方式建立,详情如表3.3。
表3.3 手写数字识别接口详情
| 项 |
值 |
数据类型 |
说明 |
| 路径 |
/digit_rec |
/ |
/ |
| Method |
POST |
/ |
请求体和返回值均为JSON格式 |
| 请求参数 |
token |
String |
校验码,用于身份认证 |
|
img |
String |
使用Base64编码的手写数字图片 |
| 返回值 |
code |
String |
状态码 |
|
message |
String |
附带消息 |
|
result |
JSONObject |
返回结果,含识别结果数字数组和标记后的传入图片 |
|
result. numbers |
Array |
识别结果数字数组 |
|
result. marked_img |
String |
标记后的传入图片,使用Base64编码 |
接口实现代码如下:
# post方式http请求与js交互
@app.route('/digit_rec',methods=["POST"])
def digit_rec():
# 默认返回内容
return_dict = {'code': '200', 'message': '处理成功', 'result': False}
# 错误处理
if request.get_data() is None:
return_dict['code'] = '5002'
return_dict['message'] = '请求参数为空'
return json.dumps(return_dict, ensure_ascii=False)
# 获取传入的参数
get_data = request.get_json()
# 使用简单的token校验
token = get_data.get("token")
if token != DEFAULT_TOKEN:
return_dict['code'] = '5001'
return_dict['message'] = 'TOKEN错误'
return json.dumps(return_dict, ensure_ascii=False)
img_base64 = get_data.get("img")
# 调用模型识别
result_dict = mnist_digit_rec(img_base64)
# 结果打包为JSON格式并返回
json_encode_result = json.dumps(result_dict, cls=NpEncoder)
return_dict['result'] = json_encode_result
return_str = json.dumps(return_dict, ensure_ascii=False)
return return_str
3.2.5 手写画板页面开发
基于Github开源项目drawingborad 进行开发,以快速适应需求。经过分析,决定在工具栏加入识别按钮,用于触发手写数字识别的任务,并移除工具栏保存图片按钮。结果的展示可由弹窗进行显示。
[info]drawingborad
https://github.com/zhoushuozh/drawingborad
[/info]
工具栏识别按钮单击事件监听在main.js中进行,主要代码如下:
scan.onclick = function () {
//无正在进行的请求
if (!isRequesting) {
//控制识别按钮点击后不可重复调用接口
isRequesting = true
//将识别按钮图标替换为正在加载效果
var loadingImgObj = new loadingImg()
loadingImgObj.show()
let imgUrl = canvas.toDataURL("image/png");
console.log(imgUrl)
var data = {
"img": imgUrl,
"token": "THISISAFUCKINGTOKEN"
}
//通过JQuery发送ajax异步http请求
$.ajax({
type: 'post',
url: '/digit_rec',
data: JSON.stringify(data),
contentType: 'application/json; charset=UTF-8',
dataType: 'json', success: function (data) {
if (data.code == "200") {
var rootObj = JSON.parse(data.result)
//弹窗显示识别后的文字结果和图片结果
showResult(rootObj.numbers, rootObj.marked_img)
} else {
alert('请求错误:'+data.code+" "+data.message)
}
//正在加载效果隐藏,恢复识别按钮
loadingImgObj.hide()
scan.innerHTML = "<i class=\"iconfont icon-canvas-ranlysaoma\"></i>"
//控制识别按钮点击后可再次调用接口
isRequesting = false
}, error: function (xhr, type, xxx) {
alert('请求错误:未知错误')
loadingImgObj.hide()
scan.innerHTML = "<i class=\"iconfont icon-canvas-ranlysaoma\"></i>"
isRequesting = false
}
});
} else {
//点击识别按钮,但上次识别任务还未结束,提示等待
alert("正在识别中,请等待");
}
}
4. 基于深度学习的手写数字识别
目前在计算机视觉领域,神经网络是一种主流的图像特征提取方式。深度学习更是使得计算机视觉领域取得重大突破。本项目中由于采用了接口方式将前端隔离,将精力集中于手写数字识别的开发成为可能。本项目的手写数字识别模型可在遵照输入输出的标准下进行方便的更换。本项目将使用图像分类经典入门数据集MNIST手写数字数据集用于模型训练,并使用简单易于实现的多层感知器作为分类任务模型。
4.1 多层感知器
由期中的单层感知器作业可以知道单层感知器通过激活函数可以学习简单的线性函数。但其无法学习非线性函数,也就无法完成复杂功能,需要多个神经元共同协调组成深度神经网络(DNN)才能完成复杂任务。多层感知器就是DNN中前馈神经网络的一种形式,其通常由输入层、输出层和至少一个隐藏层组成,通过隐藏层和激活函数可以学习非线性的函数。
多层感知器误差反向传播算法分为以下三步 :
- 前向计算每一层的净输入和输出,直到最后一层,得到预测值。
- 反向传播计算网络在每一层上的损失项,第m层损失项是通过第m+1层的损失项计算得到的。
- 计算每一层参数的偏导数,在神经网络中就是指该张量的梯度,并沿着梯度的反方向更新参数。
多层感知器优点明显,结构简单,易于实现。但其缺点也不可小视,由于是全连接的神经网络,其参数数量较大,倘若增加隐藏层数量,不仅时间耗费会增大,且容易产生梯度消失问题。
对于本项目中的多层感知器,将选择常用于图像分类任务的交叉熵损失函数配合Adam优化算法,同时使用mini-batch的方法进行训练。其中Adam是一个优于传统的随机梯度下降(SGD)的算法,可以自适应调节学习率,适用于大多数情况下的优化任务。而mini-batch是一种样本处理方式,其思想为将原本一次Epoch一次梯度下降的方式(full-batch)改为一个Epoch遍历样本的多个子集(Batch),每个Batch做一次梯度下降,可以大大加快训练速度。
4.2 卷积神经网络
感知器作为一种全连接的前馈神经网络,常常产生参数过多导致的训练效率下降和过拟合问题,同时全连接的特性使其很难提取局部特征。卷积神经网络(Convolutional Neural Network, CNN)则在多层感知器的基础上发展而来,可以有效解决上述问题。CNN一般是由卷积层、采样层(池化层)、全连接层相互堆叠构成的神经网络 。其可以说是针对图像数据而设计的,具有出色的特征提取能力。CNN分类器在MNIST数据集上准确率可以达到99.77% ,相比于MLP分类器的97.2%准确率 要高。因而本项目的神经网络模型可以考虑转用CNN实现。
4.3 多个手写数字的识别
对于第3节所提到的手写画板,其最终输出的是一张尺寸不定,含有数字字符数量不定的RGB彩色图像的Base64编码字符串。而对于使用MNIST训练的神经网络模型来说,其要求的输入是单张只有一个数字字符的28*28像素的灰度图的矩阵。这两者间的转换首先需要用到Base64编码与图像矩阵转换。其次需要使用到光学字符识别(Optical Character Recognition, OCR)中的技术,对原始图像进行字符定位和切割。最后需要对切割后的图像进行特定的预处理,使其可以被MLP分类器处理和高效分类。
4.3.1 图像字符定位和分割
参考Github开源项目HandwrittenDigitRecognition ,使用开源计算机视觉库OpenCV库在Python上的库cv2实现字符定位与分割任务。
HandwrittenDigitRecognition
https://github.com/Wangzg123/HandwrittenDigitRecognition
其中字符定位主要使用OpenCV中的findContours()函数进行。该函数可以通过轮廓检测来实现字符定位,并返回一个数组,数组中每个元素都是图像中的一个轮廓。其次再通过OpenCV的boundingRect()函数得到字符矩形边框,其返回值为边框的四个参数:x,y,w,h. 其分别代表字符左上角在整张图片中的x轴坐标、y轴坐标、字符宽度、字符高度。这样便简单完成了字符的定位。
简化的分割任务是基于以上的字符定位结果的,得到框选字符的矩形的左上角和右下角坐标后,直接在原图的矩阵中取子集便可得到单个字符,易于实现。但这样的坏处是,若多个字符间虽然没有连接,但若有字符的一部分或整体有侵入其它字符的矩形区域的话,会使得被侵入的字符分割后带有其它字符的部分,使得分割产生瑕疵,这是一个值得考虑的改进点。
4.3.2 字符图像数据预处理
经过以上识别和分割后的单个字符的图像是一个大小不定的图像矩阵数据,参考MNIST手写数字数据集中的单个数字字符形式,对字符图像进行灰度化和二值化处理,使得图像的形状和轮廓更为清晰。接着根据图像最长边扩展像素,最长边方向扩展7个像素,短边方向长度等于扩展后的长边。得到一个正方形的手写数字的图像,矩阵变换一下得到28281的三维矩阵,其中前两维为像素位置,第三维为灰度值(0到255)。
以下为使用画板中粗细为10的黑色画笔绘制的几个数字,经过上述处理后的灰度图。

4.4 不同超参数配置策略探究最优参数
至此,系统构建,特别是模型的构建已经告一段落。现对模型训练中的可调节超参数进行控制变量的渐进式调节实验,以探究不同超参数对于分类准确率的影响。探究实验中所使用的训练、测试数据集仍然为MNIST手写数字数据集,其中测试集大小为10000。
表4.1 MLP模型可调节超参数列表
| 参数 |
|---|
| 隐藏层数 |
| EPOCH |
| Batch大小 |
| 初始学习率 |
首先对隐藏层数进行初步探究,以下为隐藏层数作为变量,其它超参数不变的情况下的探究策略表,其中三次训练准确率指使用同一组超参数重复三次的准确率平均值。
表4.2对最优隐藏层数的探究实验策略
| 策略 |
参数值[隐藏层数,EPOCH, Batch大小,初始学习率] |
准确率 |
训练用时(秒) |
| 1 |
[100,5,100,0.001] |
96.98% |
33.3 |
| 2 |
[300,5,100,0.001] |
97.79% |
36.7 |
| 3 |
[400,5,100,0.001] |
97.83% |
41.7 |
| 4 |
[500,5,100,0.001] |
97.91% |
44.0 |
| 5 |
[600,5,100,0.001] |
97.86 % |
46.0 |
| 6 |
[700,5,100,0.001] |
97.98 % |
48.3 |
| 7 |
[800,5,100,0.001] |
98.12 % |
50.0 |
可见大致上准确率随隐藏层数增加而增加,但幅度极小,同时训练时间也随隐藏层数增加而增加。
表4.2对最优学习率的探究实验策略
| 策略 |
参数值[隐藏层数,EPOCH, Batch大小,初始学习率] |
准确率 |
训练用时(秒) |
| 1 |
[500,5,100,0.0001] |
94.67 % |
43 |
| 2 |
[500,5,100,0.0005] |
97.63 % |
43.33 |
| 3 |
[500,5,100,0.001] |
97.86 % |
44 |
| 4 |
[500,5,100, 0.005] |
97.61 % |
44 |
| 5 |
[500,5,100,0.01] |
96.69 % |
46.33 |
| 6 |
[500,5,100,0.05] |
93.22 % |
49.67 |
| 7 |
[500,5,100,0.1] |
77.03 % |
49.33 |
可见学习率在值为0.001时模型效率最高。
表4.3对最优Batch大小的探究实验策略
| 策略 |
参数值[隐藏层数,EPOCH, Batch大小,初始学习率] |
准确率 |
训练用时(秒) |
| 1 |
[100,5,10,0.001] |
97.75 |
168.33 |
| 2 |
[100,5,50,0.001] |
97.93 % |
57.67 |
| 3 |
[100,5,100,0.001] |
97.90 % |
44.33 |
| 4 |
[100,5,150,0.001] |
97.66 % |
40.33 |
| 5 |
[100,5,200,0.001] |
97.70 % |
38.33 |
| 6 |
[100,5,300,0.001] |
97.55 % |
36.00 |
| 7 |
[100,5,600,0.001] |
96.86 % |
34.33 |
可见Batch大小为50时准确率最高,但综合耗时来看,Batch大小为100时的耗时要少十秒以上,且准确率仅低0.03个百分点。因此最优Batch大小应当为100。
如下对EPOCH次数进行探究,在保持隐藏层数为500,Batch大小为100,初始学习率为0.001的情况下,对不同EPOCH记录准确率,并作EPOCH-Acc关系图如下:
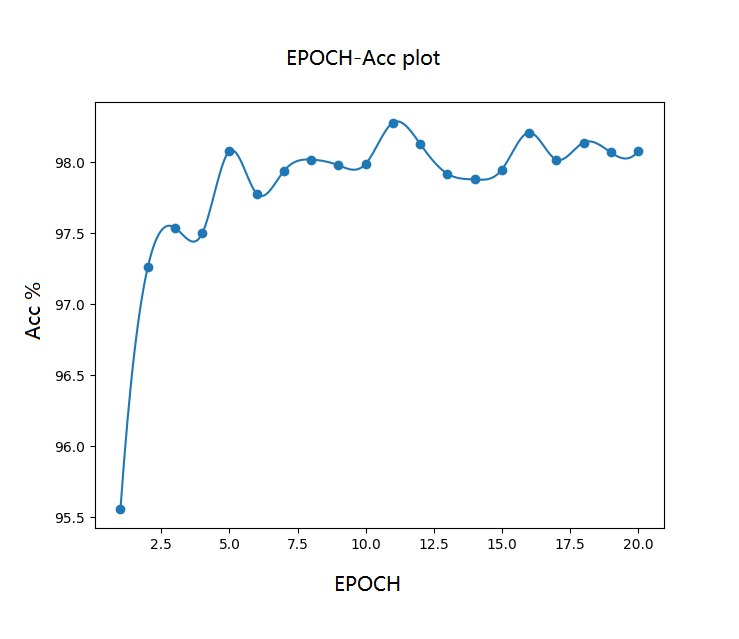
经过简单的探究,可以发现隐藏层神经元数在100到800间变化时对准确率影响不大,对训练时间影响呈正相关;而学习率在0.0001到0.1间变化时对准确率和训练时间都有较为明显的影响,学习率为0.001时准确率最高,且训练时间也相对较短;Batch大小对于训练数据的影响较为显著,特别是Batch比较小的时候训练时间约是最短训练时间的5倍。综合认为最优Batch大小为100;由EPOCH-Acc关系图可知模型在5次EPOCH时收敛。
文章首发:https://ranlychan.top/archives/402.html