一、问题来源
我日常写博客时,首先使用 typora 编辑 markdown 文件,然后在 CSDN 的 markdown 编辑器中导入 .md 文件。但是使用 typora 的小伙伴们都知道,typora 中缩放图片时使用的是 zoom 属性,然而 CSDN 并不支持这个属性。因此在导入用 typora 写好的 .md 文件时,在 CSDN 上观看时图片老大一个,并且不会自动居中,因此十分不爽。
typora中不改变图片大小后直接粘贴的效果:
二、解决方案
这里我使用 python 正则匹配来替换所有图片对应的 url 内容。经过测试,只需要将 .md 文件放入项目工程中,运行 python 脚本后,把新生成的 .md 文件拷贝到 CSDN 中即可。下面介绍具体方案:
(一)创建工程项目
使用 pycharm 创建工程项目,在项目文件夹下创建两个文件夹 in 和 out。in 文件夹存储待处理的 .md 文件,out 文件夹为输出文件夹:
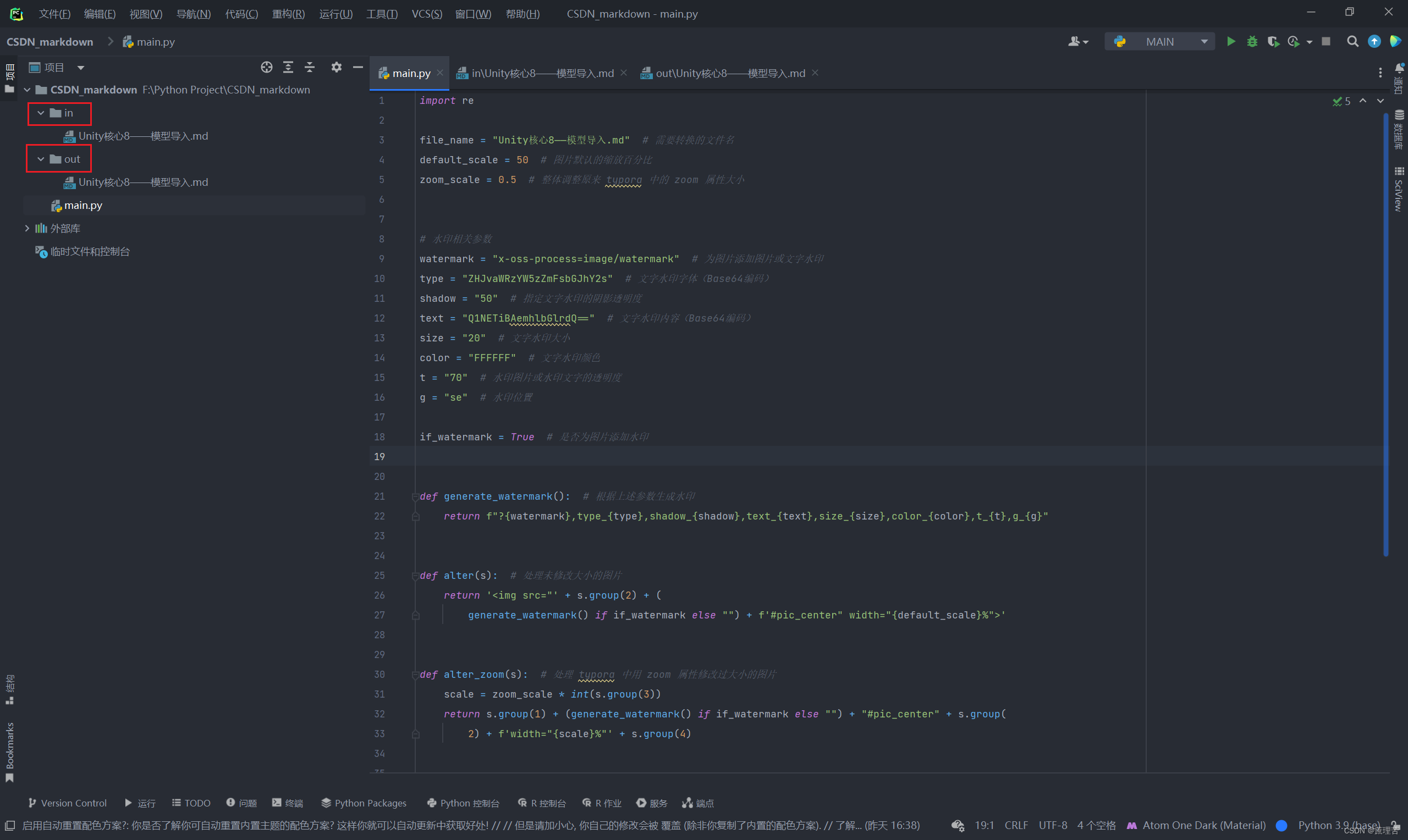
当然,如果你使用的是 vscode 或者其他 idle,类似即可,配置不复杂。
(二)代码
编写代码,这里我把我自己写的代码附上,仅供参考:
import re
file_name = "Unity核心8——模型导入.md" # 需要转换的文件名
default_scale = 50 # 图片默认的缩放百分比
zoom_scale = 0.5 # 整体调整原来 typora 中的 zoom 属性大小
# 水印相关参数
watermark = "x-oss-process=image/watermark" # 为图片添加图片或文字水印
type = "ZHJvaWRzYW5zZmFsbGJhY2s" # 文字水印字体(Base64编码)
shadow = "50" # 指定文字水印的阴影透明度
text = "Q1NETiBAemhlbGlrdQ==" # 文字水印内容(Base64编码)
size = "20" # 文字水印大小
color = "FFFFFF" # 文字水印颜色
t = "70" # 水印图片或水印文字的透明度
g = "se" # 水印位置
if_watermark = True # 是否为图片添加水印
def generate_watermark(): # 根据上述参数生成水印
return f"?{watermark},type_{type},shadow_{shadow},text_{text},size_{size},color_{color},t_{t},g_{g}"
def alter(s): # 处理未修改大小的图片
return '<img src="' + s.group(2) + (
generate_watermark() if if_watermark else "") + f'#pic_center" width="{default_scale}%">'
def alter_zoom(s): # 处理 typora 中用 zoom 属性修改过大小的图片
scale = zoom_scale * int(s.group(3))
return s.group(1) + (generate_watermark() if if_watermark else "") + "#pic_center" + s.group(
2) + f'width="{scale}%"' + s.group(4)
with open("./in/" + file_name, "r", encoding="utf-8") as fin, open("./out/" + file_name, "w", encoding="utf-8") as fout:
pattern = re.compile(r"(!\[image-\d+]\()(.+)(\))") # 未修改大小的图片的匹配规则
pattern_zoom = re.compile(r'(<img src=".*)(" .* )style="zoom:\s?(\d+)%;"(\s?/>)') # 带有 zoom 属性的图片的匹配规则
content = fin.read() # 读取文件内容
content1 = pattern.subn(alter, content) # 第一次处理
content2 = pattern_zoom.subn(alter_zoom, content1[0]) # 第二次处理
fout.write(content2[0]) # 写入新文件
print("原始图片替换次数:", content1[1])
print("zoom 属性图片替换次数:", content2[1])
print("总共替换次数:", content1[1] + content2[1])
关于水印参数部分,不清楚的可以参考 这篇文章
这里我将图片分为两种,一种是直接复制进 typora 的,即  这种类型的链接图片。另一种是在 typora 中右键修改过大小的带有 zoom 属性的链接图片。
- 对于第一种图片,替换后默认缩放大小为 default_scale%;
- 对于第二种,原本是想保留原来的 zoom 属性值,直接替换为 width 属性。后来想想还是设置了一个缩放比例 zoom_scale。即,原来图片大小为 zoom: 50% 的图片,经过处理后变为 width: 50 * zoom_scale%
当然这里我的图片链接并不是本地的,我设置了云图床。如果你的图片链接是本地链接(即,使用了 assets 文件夹),那么复制到 CSDN 时可能转换失败。我这里没尝试过本地链接,在这里附上 typora 图床的配置教程
配置完成后,将 .md 文件放入 in 文件夹,修改 file_name,运行脚本后,直接把 out 文件夹中新生成的 .md 文件复制到 CSDN 的 markdown 编辑器即可。对应的图片大小自己微调就好。也可以自己修改代码调整参数自行配置~
2022-06-30 更新
今天上传时,发现并不能直接用 zoom 属性替换 width 的百分比属性,两个属性还是不一样的。因此在原来的代码基础上添加了获取图片大小的功能,将图片大小设置为固定值,该值为 原图大小 * zoom 属性值:
import io
import re
import urllib.request
from PIL import Image
file_name = "Unity核心8——模型导入.md" # 需要转换的文件名
scale = 0.6 # 图片整体缩放比例
# 水印相关参数
watermark = "x-oss-process=image/watermark" # 为图片添加图片或文字水印
type = "ZHJvaWRzYW5zZmFsbGJhY2s" # 文字水印字体(Base64编码)
shadow = "50" # 指定文字水印的阴影透明度
text = "Q1NETiBAemhlbGlrdQ==" # 文字水印内容(Base64编码)
size = "20" # 文字水印大小
color = "FFFFFF" # 文字水印颜色
t = "70" # 水印图片或水印文字的透明度
g = "se" # 水印位置
if_watermark = True # 是否为图片添加水印
def generate_watermark(): # 根据上述参数生成水印
return f"?{watermark},type_{type},shadow_{shadow},text_{text},size_{size},color_{color},t_{t},g_{g}"
def get_size(img_path): # 根据图片链接获取图片的大小
response = urllib.request.urlopen(img_path)
temp_img = io.BytesIO(response.read())
img = Image.open(temp_img)
return img.size
def alter(s): # 处理未修改大小的图片
w, h = get_size(s.group(2))
new_w, new_h = int(scale * w), int(scale * h)
return '<img src="' + s.group(2) + (
generate_watermark() if if_watermark else "") + f'#pic_center" width="{new_w}" height="{new_h}">'
def alter_zoom(s): # 处理 typora 中用 zoom 属性修改过大小的图片
zoom_value = int(s.group(4)) / 100
w, h = get_size(s.group(2))
new_w, new_h = int(zoom_value * w), int(zoom_value * h)
return s.group(1) + s.group(2) + (generate_watermark() if if_watermark else "") + "#pic_center" + s.group(
3) + f'width="{new_w}" height="{new_h}"' + s.group(5)
with open("./in/" + file_name, "r", encoding="utf-8") as fin, open("./out/" + file_name, "w", encoding="utf-8") as fout:
pattern = re.compile(r"(!\[image-\d+]\()(.+)(\))") # 未修改大小的图片的匹配规则
pattern_zoom = re.compile(r'(<img src=")(.*)(" .* )style="zoom:\s?(\d+)%;"(\s?/>)') # 带有 zoom 属性的图片的匹配规则
content = fin.read() # 读取文件内容
content1 = pattern.subn(alter, content) # 第一次处理
content2 = pattern_zoom.subn(alter_zoom, content1[0]) # 第二次处理
fout.write(content2[0]) # 写入新文件
print("原始图片替换次数:", content1[1])
print("zoom 属性图片替换次数:", content2[1])
print("总共替换次数:", content1[1] + content2[1])